Published Date : 2019年7月9日17:34
Deep Manzai Part 8 〜 AWSとFlask編 〜 その弐
前回の簡単なあらすじ
2: デプロイに必要な環境を構築。
3: Pythonライブラリをインストール。
それでは一旦ローカル環境でアプリを 作って行きます。
AIML
AJAX,Flask部分はこちらのコードを 使わせて頂きました。 誠にありがとうございます。
ちなみにAIMLとは 簡単に説明すると、 人間が手入力でセリフを 作っていくための マークアップ言語です。
昔流行ったときメモなんかの ゲームを想像して頂けたら 分かりやすいと思います。
こういったセリフの掛け合いが主な 昔のゲームだと、人間が1から セリフパターンを組んでいるので、 結構な量のセリフ量になります。 (選択式なのでさらに膨大な量) 広辞苑の数冊分もあるという話も。
機会があったらこういった ルールベースを上手く活用できないか 考えてみたいと思います。
LINE APIを使えば こういった地道なルールベースで、 LINEカスタマーセンターアプリ 等はきちんとマニュアルが 整備されていれば
入力に時間と手間がかかりますが、 なかなかいい感じのものが作れます。
そういえば少し古い資料だけど、 こちらの資料 にも書いてある通り、 2016年時点では [ロボットは東大に入れるか] (岡山大学)は ルールベース主体だったみたい。
今でも商用やそれなりの精度が 要求されるチャットボットなどは ルールベース主体が多いのです。
Flask and AJAX
やることはこのコードのAIMLで 動いている部分を Chainer学習モデル推論出力に 書き換えるだけです。
それでは一気にコードを 写していきます。
Flask部分
作れたら、 一気にファイル名だけ決めてしまい、 dataフォルダに必要な データをぶっこみます。
# flaskapp フォルダの中身
- data
|- best_model.npz
|- source_ids.pkl
|- source_words.pkl
|- target_ids.pkl
|- target_words.pkl
- static
|- css
|- style.css
- templates
|- chat.html
- load_model.py
- main.py
- manzai_model.py
- output.py
main.py
# flaskライブラリから、APIの基を作るためのFlask、
# リクエストを受け取るためのrequest、
# Python辞書をJSON形式に変換するjsonifyをインポート
from flask import Flask, render_template, request, jsonify
# こちらは自作した関数。
# 応答文を作成するためと、
# モデルを再構築して、保存したモデルの読み込みを行う。
import output
import load_model
import os
# APIのインスタンスを作成
app = Flask(__name__)
# モデルと応答文のヒントとなるソースボキャブラリごとのIDのリスト
# と応答文のワードと分かち書きに必要なトークナイザーオブジェクトを作る
model,source_ids,target_words,tokenizer_obj=load_model.load_model()
# 引数にユーザーが入力した文字を受け取り、応答文を作成する関数
def create_response(mes):
# 実際に応答文を作成する関数。
query=output.output(mes,source_ids,target_words,model,tokenizer_obj)
return query
# APIのインスタンスをデコレートします。
# ここで行っているデコレーションは
# 簡単に説明すると
# APIインスタンスのappメソッド、routeは
# 受け取ったパス(今回は’/’これはルートと言って
# よくあるhttp://ドメイン名/Page1.htmlではなく
# http://ドメイン名だけでアクセスできる。)
# を基にrouteメソッド内で
# 下に定義した、chat関数を動かしたのち、
# その処理を返す使用になっている。
# もう一つ、@app.route("/")、methods=['GET','POST]
# のようにするとGETリクエストとPOSTリクエストを
# 両方処理できるようになる。
# 今回のように何も指定しないと「GET」になる。
# なんでこんなことをしてるかというと
# APIの基本であるGET(このページを見たいの!お願い伝えてAPI!
# といった際、ご希望通りのファイルを提供してくれる機能)
# はクライアント(ブラウザ)が要求した、
# このページが、このファイルが欲しいの!といった要求にしたがって
# (パスで判断する)処理をするように設計する必要があるけど、
# 大基の枠組みは、どんな処理にでも対応できるように
# 処理をする部分は
# def get(function):
# return function
# となっていなければ、柔軟にカスタマイズできない。
# なのでこのfunctionの部分に関数chatを入れることによって
# 我々は自由にAPI機能を作れるのだ!
# なげー!
@app.route("/")
def chat():
# render_templateはダイレクトリ内にある「templatesフォルダ」から
# 指定されたHTMLファイルを探し出して、それを返して上げる。
return render_template('chat.html')
# 上で説明した通り、パス「/ask」が要求された時、
# POST要求を処理する。
# POSTは今回の場合、
# HTMLファイルに応答文を作成するように命令すること。
# ユーザー認証など、クライアント側(ブラウザ)で
# 入力した値をHTMLに反映させるとか、
# 裏でデータベースを使用して、記憶、照合を行ったりする際も
# POSTメソッドをつかいマイケル。
@app.route("/ask", methods=['POST'])
def ask():
# メッセージを取得
message = str(request.form['messageText'])
# 君が「quit」を入力するまで、応答文を作成するをやめない!!
while True:
if message == "quit":
exit()
else:
bot_response = create_response(message)
# チャットボットの返答を返す
return jsonify({'status':'OK','answer':bot_response})
# if __name__ == "__main__"。
# これって、普段例えば、import osとか外部のモジュール呼びますよね?
# でもosモジュール内部で、if __name__ == "__main__"が無かったら悲惨です。
# import osと入力した時点で、全ての定義された関数が発動します。
# これを入れることによって、外部モジュールとして機能できるようにするんDESU!
# 例
# test.py
# def test():
# return(”spam!”)
# if __name__ == "__main__":
# test()
# >>import test
# と打った時、__name__には”test”という名前が入りますので
# if __name__ != "__main__"なので勝手に発動しません。
# >>python test.pyと打った時、__name__には”__main__”が入る決まりになっていますので、
# ”spam!”が返されるという仕組みです。
# なげー!
if __name__ == "__main__":
# ホスト名を指定
# この場合'0.0.0.0'は何でもOKという意味です。
# ’’127.0.0.1”でも
# ”192.XX.XX.XX”でも
# 全て俺が('0.0.0.0'が)受け止めてやるぜベイベー
# ということです。
# デバックをTrueにすれば
# コンソール画面に今どんな状況か
# POSTメソッドを受け付けました、
# GETメソッドは200で正常でしたよ!
# などと表示される。
app.run(host='0.0.0.0', debug=True)
load_model.py
Flaskの説明で力尽きたので、 以下軽〜く説明。
# Chainer学習モデルを再構築するため、モデルとパラメーターを呼び込む。 from manzai_model import ParseArg,Transformer from chainer import cuda,serializers import chainer import numpy as np import os import dill from janome.tokenizer import Tokenizer def load_model(): # いつものごとく、どんなダイレクとリ構造でも対応できるようにする。 BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) data_dir= os.path.join(BASE_DIR, 'flaskapp/data') # どうせCPUだけどエラー回避のため仕方が無く必要。 if cuda.available and cuda.cudnn_enabled: xp = cuda.cupy else: xp = np # dillを使ってPickleファイルからPythonオブジェクトに変換 with open(os.path.join(data_dir,'source_ids.pkl'),'rb') as f:source_ids=dill.load(f) with open(os.path.join(data_dir,'target_ids.pkl'),'rb') as f:target_ids=dill.load(f) with open(os.path.join(data_dir,'source_words.pkl'),'rb') as f:source_words=dill.load(f) with open(os.path.join(data_dir,'target_words.pkl'),'rb') as f:target_words=dill.load(f) # 学習時に設定したパラメーターを呼び出す。 args = ParseArg() # Transformerモデルを召喚 model = Transformer( args.layer, min(len(source_ids), len(source_words)), min(len(target_ids), len(target_words)), args.unit, h=args.head, dropout=args.dropout, max_length=500, use_label_smoothing=args.use_label_smoothing, embed_position=args.embed_position) # 学習済みモデルの重みパラメーターを読み込む serializers.load_npz(os.path.join(data_dir,"best_model.npz"),model) # 分かち書きしてくれるオブジェクトを作成。 tokenizer_obj = Tokenizer() # 応答文作成に必要なオブジェクトを返す。 return model,source_ids,target_words,tokenizer_obj
output.py
import re
import random
# 情報量が多いと困るので、とりあえず記号は排除する。
split_mark_pattern=re.compile(r'[\(、。・_;:」…「^)℃(!?,!\?\.\[\]『』【】《》\)*\n<>]')
# 数字も全て0にする。
split_digit=re.compile(r'[\d]+')
# 一行ずつパターンにマッチした記号と数字を処理する関数
def split_marks(x):
try:
x=split_mark_pattern.sub('',x)
x=split_digit.sub('0',x)
return x
except:
return x
# 実際に応答文を作成する関数
def output(mes,source_ids,target_words,model,tokenizer_obj):
# 記号と数字を処理
input_data = split_marks(mes)
print("\nPredict")
# 分かち書きする 例:「おはよう 調子はどう」ー>「おはよう」「調子」「は」「ど」「う」
query=janome_parse(input_data,tokenizer_obj)
# 入力された文を素に学習したモデルからビームサーチを使って応答文生成。
res=translate_one(query,source_ids,target_words,model)
# 0をランダムな数字にして楽しむ、<UNK>はreplaceメソッドで空文字にする。
try:
manzai_response = re.sub('0',str(random.randint(1,100)),''.join(res).replace('',''))
except:
manzai_response = ''.join(res).replace('','')
return manzai_response
# 実際に分かち書きするための関数
def janome_parse(text,tokenizer_obj):
tokens=tokenizer_obj.tokenize(text)
return [token.surface for token in tokens]
# translate_oneは内部でtransleteを呼び出し、
# translateは引数のbeamが指定されていると、
# Transfomerクラスのtranslate_beamメソッドを使って
# ビームサーチで応答文を返す。
def translate_one(source,source_ids,target_words,model):
words = source
print('# source : ' + ' '.join(words))
x = model.xp.array(
[source_ids.get(w, 1) for w in words], 'i')
ys = model.translate([x], beam=5)[0]
words = [target_words[y] for y in ys]
print('# result : ' + ' '.join(words))
return words
manzai_model.py
from chainer import Chain, Variable, cuda, optimizer, optimizers, serializers
# Chainerで用意されている、DeepLeaningに必要な
# 関数とパラメータを持ったニューラルネットの関数を呼び出す。
import chainer.functions as F
import chainer.links as L
from chainer.dataset import convert
from chainer import training
from chainer.training import extensions
import numpy as np
import chainer
from chainer import reporter
if chainer.cuda.available and chainer.cuda.cudnn_enabled:
xp = cuda.cupy
else:
xp = np
# オリジナルソースコードではコマンドラインから受け付けるパラメーターを
# アプリケーション用にクラスに変換。
class ParseArg:
def __init__(self,batchsize=16,epoch=100,gpu=0,unit=512,
layer=6,head=8,dropout=0.1,input_='data',source='encode_train_data.txt',
target='decode_train_data.txt',source_valid='encode_valid_data.txt',
target_valid='decode_valid_data.txt',out_='result',
source_vocab=40000,target_vocab=40000,no_bleu=True,
use_label_smoothing=True,embed_position=True,use_fixed_lr=True):
self.batchsize=batchsize
self.epoch=epoch
self.gpu=gpu
self.unit=unit
self.layer=layer
self.head=head
self.dropout=dropout
self.input=input_
self.source=source
self.target=target
self.source_valid=source_valid
self.target_valid=target_valid
self.out=out_
self.source_vocab=source_vocab
self.target_vocab=target_vocab
self.no_bleu=no_bleu
self.use_label_smoothing=use_label_smoothing
self.embed_position=embed_position
self.use_fixed_lr=use_fixed_lr
# 余ったベクトル枠を0とか<PAD>といった文字列を入れてパディングするための処理。
# Xt1「’あ’、’い’、’う’、’え’、’お’、<PAD>、<PAD>、<PAD>」
# Xt2「’あ’、’い’、’う’、’え’、’お’、’か’、’き’、’く’」
def seq2seq_pad_concat_convert(xy_batch, device, eos_id=0, bos_id=2):
"""
Args:
xy_batch (list of tuple of two numpy.ndarray-s or cupy.ndarray-s):
xy_batch[i][0] is an array
of token ids of i-th input sentence in a minibatch.
xy_batch[i][1] is an array
of token ids of i-th target sentence in a minibatch.
The shape of each array is `(sentence length, )`.
device (int or None): Device ID to which an array is sent. If it is
negative value, an array is sent to CPU. If it is positive, an
array is sent to GPU with the given ID. If it is ``None``, an
array is left in the original device.
Returns:
Tuple of Converted array.
(input_sent_batch_array, target_sent_batch_input_array,
target_sent_batch_output_array).
The shape of each array is `(batchsize, max_sentence_length)`.
All sentences are padded with -1 to reach max_sentence_length.
"""
#print(xy_batch)
#print(*xy_batch)
x_seqs, y_seqs = zip(*xy_batch)
x_block = convert.concat_examples(x_seqs, device, padding=-1)
y_block = convert.concat_examples(y_seqs, device, padding=-1)
xp = cuda.get_array_module(x_block)
# The paper did not mention eos
# add eos
x_block = xp.pad(x_block, ((0, 0), (0, 1)),
'constant', constant_values=-1)
for i_batch, seq in enumerate(x_seqs):
x_block[i_batch, len(seq)] = eos_id
x_block = xp.pad(x_block, ((0, 0), (1, 0)),
'constant', constant_values=bos_id)
y_out_block = xp.pad(y_block, ((0, 0), (0, 1)),
'constant', constant_values=-1)
for i_batch, seq in enumerate(y_seqs):
y_out_block[i_batch, len(seq)] = eos_id
y_in_block = xp.pad(y_block, ((0, 0), (1, 0)),
'constant', constant_values=bos_id)
return (x_block, y_in_block, y_out_block)
# translate内で使用するようのパッディング関数。
def source_pad_concat_convert(x_seqs, device, eos_id=0, bos_id=2):
x_block = convert.concat_examples(x_seqs, device, padding=-1)
xp = cuda.get_array_module(x_block)
# add eos
x_block = xp.pad(x_block, ((0, 0), (0, 1)),
'constant', constant_values=-1)
for i_batch, seq in enumerate(x_seqs):
x_block[i_batch, len(seq)] = eos_id
x_block = xp.pad(x_block, ((0, 0), (1, 0)),
'constant', constant_values=bos_id)
return x_block
# linear_init = chainer.initializers.GlorotNormal()
# デフォルトのScale1(-1~1)を素に正規化。
linear_init = chainer.initializers.LeCunUniform()
# エムベッド(固定された次元の分散表現ベクトルへ変換されたもの)
# を2次元配列に変換する。
def sentence_block_embed(embed, x):
""" Change implicitly embed_id function's target to ndim=2
Apply embed_id for array of ndim 2,
shape (batchsize, sentence_length),
instead for array of ndim 1.
"""
batch, length = x.shape
_, units = embed.W.shape
e = embed(x.reshape((batch * length, )))
assert(e.shape == (batch * length, units))
e = F.transpose(F.stack(F.split_axis(e, batch, axis=0), axis=0), (0, 2, 1))
assert(e.shape == (batch, units, length))
return e
# 入力された2次元の配列を三次元配列に変換する。
def seq_func(func, x, reconstruct_shape=True):
""" Change implicitly function's target to ndim=3
Apply a given function for array of ndim 3,
shape (batchsize, dimension, sentence_length),
instead for array of ndim 2.
"""
batch, units, length = x.shape
e = F.transpose(x, (0, 2, 1)).reshape(batch * length, units)
e = func(e)
if not reconstruct_shape:
return e
out_units = e.shape[1]
e = F.transpose(e.reshape((batch, length, out_units)), (0, 2, 1))
assert(e.shape == (batch, out_units, length))
return e
# 以下英語の説明を読んでくだちぃ。。。
class LayerNormalizationSentence(L.LayerNormalization):
""" Position-wise Linear Layer for Sentence Block
Position-wise layer-normalization layer for array of shape
(batchsize, dimension, sentence_length).
"""
def __init__(self, *args, **kwargs):
super(LayerNormalizationSentence, self).__init__(*args, **kwargs)
def __call__(self, x):
y = seq_func(super(LayerNormalizationSentence, self).__call__, x)
return y
class ConvolutionSentence(L.Convolution2D):
""" Position-wise Linear Layer for Sentence Block
Position-wise linear layer for array of shape
(batchsize, dimension, sentence_length)
can be implemented a convolution layer.
"""
def __init__(self, in_channels, out_channels,
ksize=1, stride=1, pad=0, nobias=False,
initialW=None, initial_bias=None):
super(ConvolutionSentence, self).__init__(
in_channels, out_channels,
ksize, stride, pad, nobias,
initialW, initial_bias)
def __call__(self, x):
"""Applies the linear layer.
Args:
x (~chainer.Variable): Batch of input vector block. Its shape is
(batchsize, in_channels, sentence_length).
Returns:
~chainer.Variable: Output of the linear layer. Its shape is
(batchsize, out_channels, sentence_length).
"""
x = F.expand_dims(x, axis=3)
y = super(ConvolutionSentence, self).__call__(x)
y = F.squeeze(y, axis=3)
return y
class MultiHeadAttention(chainer.Chain):
""" Multi Head Attention Layer for Sentence Blocks
For batch computation efficiency, dot product to calculate query-key
scores is performed all heads together.
"""
def __init__(self, n_units, h=8, dropout=0.1, self_attention=True):
super(MultiHeadAttention, self).__init__()
with self.init_scope():
if self_attention:
self.W_QKV = ConvolutionSentence(
n_units, n_units * 3, nobias=True,
initialW=linear_init)
else:
self.W_Q = ConvolutionSentence(
n_units, n_units, nobias=True,
initialW=linear_init)
self.W_KV = ConvolutionSentence(
n_units, n_units * 2, nobias=True,
initialW=linear_init)
self.finishing_linear_layer = ConvolutionSentence(
n_units, n_units, nobias=True,
initialW=linear_init)
self.h = h
self.scale_score = 1. / (n_units // h) ** 0.5
self.dropout = dropout
self.is_self_attention = self_attention
def __call__(self, x, z=None, mask=None):
xp = self.xp
h = self.h
if self.is_self_attention:
Q, K, V = F.split_axis(self.W_QKV(x), 3, axis=1)
else:
Q = self.W_Q(x)
K, V = F.split_axis(self.W_KV(z), 2, axis=1)
batch, n_units, n_querys = Q.shape
_, _, n_keys = K.shape
# Calculate Attention Scores with Mask for Zero-padded Areas
# Perform Multi-head Attention using pseudo batching
# all together at once for efficiency
batch_Q = F.concat(F.split_axis(Q, h, axis=1), axis=0)
batch_K = F.concat(F.split_axis(K, h, axis=1), axis=0)
batch_V = F.concat(F.split_axis(V, h, axis=1), axis=0)
assert(batch_Q.shape == (batch * h, n_units // h, n_querys))
assert(batch_K.shape == (batch * h, n_units // h, n_keys))
assert(batch_V.shape == (batch * h, n_units // h, n_keys))
mask = xp.concatenate([mask] * h, axis=0)
batch_A = F.batch_matmul(batch_Q, batch_K, transa=True) \
* self.scale_score
batch_A = F.where(mask, batch_A, xp.full(batch_A.shape, -np.inf, 'f'))
batch_A = F.softmax(batch_A, axis=2)
batch_A = F.where(
xp.isnan(batch_A.data), xp.zeros(batch_A.shape, 'f'), batch_A)
assert(batch_A.shape == (batch * h, n_querys, n_keys))
# Calculate Weighted Sum
batch_A, batch_V = F.broadcast(
batch_A[:, None], batch_V[:, :, None])
batch_C = F.sum(batch_A * batch_V, axis=3)
assert(batch_C.shape == (batch * h, n_units // h, n_querys))
C = F.concat(F.split_axis(batch_C, h, axis=0), axis=1)
assert(C.shape == (batch, n_units, n_querys))
C = self.finishing_linear_layer(C)
return C
class FeedForwardLayer(chainer.Chain):
def __init__(self, n_units):
super(FeedForwardLayer, self).__init__()
n_inner_units = n_units * 4
with self.init_scope():
self.W_1 = ConvolutionSentence(n_units, n_inner_units,
initialW=linear_init)
self.W_2 = ConvolutionSentence(n_inner_units, n_units,
initialW=linear_init)
# self.act = F.relu
self.act = F.leaky_relu
def __call__(self, e):
e = self.W_1(e)
e = self.act(e)
e = self.W_2(e)
return e
class EncoderLayer(chainer.Chain):
def __init__(self, n_units, h=8, dropout=0.1):
super(EncoderLayer, self).__init__()
with self.init_scope():
self.self_attention = MultiHeadAttention(n_units, h)
self.feed_forward = FeedForwardLayer(n_units)
self.ln_1 = LayerNormalizationSentence(n_units, eps=1e-6)
self.ln_2 = LayerNormalizationSentence(n_units, eps=1e-6)
self.dropout = dropout
def __call__(self, e, xx_mask):
sub = self.self_attention(e, e, xx_mask)
e = e + F.dropout(sub, self.dropout)
e = self.ln_1(e)
sub = self.feed_forward(e)
e = e + F.dropout(sub, self.dropout)
e = self.ln_2(e)
return e
class DecoderLayer(chainer.Chain):
def __init__(self, n_units, h=8, dropout=0.1):
super(DecoderLayer, self).__init__()
with self.init_scope():
self.self_attention = MultiHeadAttention(n_units, h)
self.source_attention = MultiHeadAttention(
n_units, h, self_attention=False)
self.feed_forward = FeedForwardLayer(n_units)
self.ln_1 = LayerNormalizationSentence(n_units, eps=1e-6)
self.ln_2 = LayerNormalizationSentence(n_units, eps=1e-6)
self.ln_3 = LayerNormalizationSentence(n_units, eps=1e-6)
self.dropout = dropout
def __call__(self, e, s, xy_mask, yy_mask):
sub = self.self_attention(e, e, yy_mask)
e = e + F.dropout(sub, self.dropout)
e = self.ln_1(e)
sub = self.source_attention(e, s, xy_mask)
e = e + F.dropout(sub, self.dropout)
e = self.ln_2(e)
sub = self.feed_forward(e)
e = e + F.dropout(sub, self.dropout)
e = self.ln_3(e)
return e
class Encoder(chainer.Chain):
def __init__(self, n_layers, n_units, h=8, dropout=0.1):
super(Encoder, self).__init__()
self.layer_names = []
for i in range(1, n_layers + 1):
name = 'l{}'.format(i)
layer = EncoderLayer(n_units, h, dropout)
self.add_link(name, layer)
self.layer_names.append(name)
def __call__(self, e, xx_mask):
for name in self.layer_names:
e = getattr(self, name)(e, xx_mask)
return e
class Decoder(chainer.Chain):
def __init__(self, n_layers, n_units, h=8, dropout=0.1):
super(Decoder, self).__init__()
self.layer_names = []
for i in range(1, n_layers + 1):
name = 'l{}'.format(i)
layer = DecoderLayer(n_units, h, dropout)
self.add_link(name, layer)
self.layer_names.append(name)
def __call__(self, e, source, xy_mask, yy_mask):
for name in self.layer_names:
e = getattr(self, name)(e, source, xy_mask, yy_mask)
return e
class Transformer(chainer.Chain):
def __init__(self, n_layers, n_source_vocab, n_target_vocab, n_units,
h=8, dropout=0.1, max_length=500,
use_label_smoothing=False,
embed_position=False):
super(Transformer, self).__init__()
with self.init_scope():
self.embed_x = L.EmbedID(n_source_vocab, n_units, ignore_label=-1,
initialW=linear_init)
self.embed_y = L.EmbedID(n_target_vocab, n_units, ignore_label=-1,
initialW=linear_init)
self.encoder = Encoder(n_layers, n_units, h, dropout)
self.decoder = Decoder(n_layers, n_units, h, dropout)
if embed_position:
self.embed_pos = L.EmbedID(max_length, n_units,
ignore_label=-1)
self.n_layers = n_layers
self.n_units = n_units
self.n_target_vocab = n_target_vocab
self.dropout = dropout
self.use_label_smoothing = use_label_smoothing
self.initialize_position_encoding(max_length, n_units)
self.scale_emb = self.n_units ** 0.5
def initialize_position_encoding(self, length, n_units):
xp = self.xp
"""
# Implementation described in the paper
start = 1 # index starts from 1 or 0
posi_block = xp.arange(
start, length + start, dtype='f')[None, None, :]
unit_block = xp.arange(
start, n_units // 2 + start, dtype='f')[None, :, None]
rad_block = posi_block / 10000. ** (unit_block / (n_units // 2))
sin_block = xp.sin(rad_block)
cos_block = xp.cos(rad_block)
self.position_encoding_block = xp.empty((1, n_units, length), 'f')
self.position_encoding_block[:, ::2, :] = sin_block
self.position_encoding_block[:, 1::2, :] = cos_block
"""
# Implementation in the Google tensor2tensor repo
channels = n_units
position = xp.arange(length, dtype='f')
num_timescales = channels // 2
log_timescale_increment = (
xp.log(10000. / 1.) /
(float(num_timescales) - 1))
inv_timescales = 1. * xp.exp(
xp.arange(num_timescales).astype('f') * -log_timescale_increment)
scaled_time = \
xp.expand_dims(position, 1) * \
xp.expand_dims(inv_timescales, 0)
signal = xp.concatenate(
[xp.sin(scaled_time), xp.cos(scaled_time)], axis=1)
signal = xp.reshape(signal, [1, length, channels])
self.position_encoding_block = xp.transpose(signal, (0, 2, 1))
def make_input_embedding(self, embed, block):
batch, length = block.shape
emb_block = sentence_block_embed(embed, block) * self.scale_emb
emb_block += self.xp.array(self.position_encoding_block[:, :, :length])
if hasattr(self, 'embed_pos'):
emb_block += sentence_block_embed(
self.embed_pos,
self.xp.broadcast_to(
self.xp.arange(length).astype('i')[None, :], block.shape))
emb_block = F.dropout(emb_block, self.dropout)
return emb_block
def make_attention_mask(self, source_block, target_block):
mask = (target_block[:, None, :] >= 0) * \
(source_block[:, :, None] >= 0)
# (batch, source_length, target_length)
return mask
def make_history_mask(self, block):
batch, length = block.shape
arange = self.xp.arange(length)
history_mask = (arange[None, ] <= arange[:, None])[None, ]
history_mask = self.xp.broadcast_to(
history_mask, (batch, length, length))
return history_mask
def output(self, h):
return F.linear(h, self.embed_y.W)
def output_and_loss(self, h_block, t_block):
batch, units, length = h_block.shape
# Output (all together at once for efficiency)
concat_logit_block = seq_func(self.output, h_block,
reconstruct_shape=False)
rebatch, _ = concat_logit_block.shape
# Make target
concat_t_block = t_block.reshape((rebatch))
ignore_mask = (concat_t_block >= 0)
n_token = ignore_mask.sum()
normalizer = n_token # n_token or batch or 1
# normalizer = 1
if not self.use_label_smoothing:
loss = F.softmax_cross_entropy(concat_logit_block, concat_t_block)
loss = loss * n_token / normalizer
else:
log_prob = F.log_softmax(concat_logit_block)
broad_ignore_mask = self.xp.broadcast_to(
ignore_mask[:, None],
concat_logit_block.shape)
pre_loss = ignore_mask * \
log_prob[self.xp.arange(rebatch), concat_t_block]
loss = - F.sum(pre_loss) / normalizer
accuracy = F.accuracy(
concat_logit_block, concat_t_block, ignore_label=-1)
perp = self.xp.exp(loss.data * normalizer / n_token)
# Report the Values
reporter.report({'loss': loss.data * normalizer / n_token,
'acc': accuracy.data,
'perp': perp}, self)
if self.use_label_smoothing:
label_smoothing = broad_ignore_mask * \
- 1. / self.n_target_vocab * log_prob
label_smoothing = F.sum(label_smoothing) / normalizer
loss = 0.9 * loss + 0.1 * label_smoothing
return loss
def __call__(self, x_block, y_in_block, y_out_block, get_prediction=False):
batch, x_length = x_block.shape
batch, y_length = y_in_block.shape
# Make Embedding
ex_block = self.make_input_embedding(self.embed_x, x_block)
ey_block = self.make_input_embedding(self.embed_y, y_in_block)
# Make Masks
xx_mask = self.make_attention_mask(x_block, x_block)
xy_mask = self.make_attention_mask(y_in_block, x_block)
yy_mask = self.make_attention_mask(y_in_block, y_in_block)
yy_mask *= self.make_history_mask(y_in_block)
# Encode Sources
z_blocks = self.encoder(ex_block, xx_mask)
# [(batch, n_units, x_length), ...]
# Encode Targets with Sources (Decode without Output)
h_block = self.decoder(ey_block, z_blocks, xy_mask, yy_mask)
# (batch, n_units, y_length)
if get_prediction:
return self.output(h_block[:, :, -1])
else:
return self.output_and_loss(h_block, y_out_block)
def translate(self, x_block, max_length=50, beam=5):
if beam:
return self.translate_beam(x_block, max_length, beam)
# TODO: efficient inference by re-using result
with chainer.no_backprop_mode():
with chainer.using_config('train', False):
x_block = source_pad_concat_convert(
x_block, device=None)
batch, x_length = x_block.shape
# y_block = self.xp.zeros((batch, 1), dtype=x_block.dtype)
y_block = self.xp.full(
(batch, 1), 2, dtype=x_block.dtype) # bos
eos_flags = self.xp.zeros((batch, ), dtype=x_block.dtype)
result = []
for i in range(max_length):
log_prob_tail = self(x_block, y_block, y_block,
get_prediction=True)
ys = self.xp.argmax(log_prob_tail.data, axis=1).astype('i')
result.append(ys)
y_block = F.concat([y_block, ys[:, None]], axis=1).data
eos_flags += (ys == 0)
if self.xp.all(eos_flags):
break
result = cuda.to_cpu(self.xp.stack(result).T)
# Remove EOS taggs
outs = []
for y in result:
inds = np.argwhere(y == 0)
if len(inds) > 0:
y = y[:inds[0, 0]]
if len(y) == 0:
y = np.array([1], 'i')
outs.append(y)
return outs
def translate_beam(self, x_block, max_length=50, beam=5):
# TODO: efficient inference by re-using result
# TODO: batch processing
with chainer.no_backprop_mode():
with chainer.using_config('train', False):
x_block = source_pad_concat_convert(
x_block, device=None)
batch, x_length = x_block.shape
assert batch == 1, 'Batch processing is not supported now.'
y_block = self.xp.full(
(batch, 1), 2, dtype=x_block.dtype) # bos
eos_flags = self.xp.zeros(
(batch * beam, ), dtype=x_block.dtype)
sum_scores = self.xp.zeros(1, 'f')
result = [[2]] * batch * beam
for i in range(max_length):
log_prob_tail = self(x_block, y_block, y_block,
get_prediction=True)
ys_list, ws_list = get_topk(
log_prob_tail.data, beam, axis=1)
ys_concat = self.xp.concatenate(ys_list, axis=0)
sum_ws_list = [ws + sum_scores for ws in ws_list]
sum_ws_concat = self.xp.concatenate(sum_ws_list, axis=0)
# Get top-k from total candidates
idx_list, sum_w_list = get_topk(
sum_ws_concat, beam, axis=0)
idx_concat = self.xp.stack(idx_list, axis=0)
ys = ys_concat[idx_concat]
sum_scores = self.xp.stack(sum_w_list, axis=0)
if i != 0:
old_idx_list = (idx_concat % beam).tolist()
else:
old_idx_list = [0] * beam
result = [result[idx] + [y]
for idx, y in zip(old_idx_list, ys.tolist())]
y_block = self.xp.array(result).astype('i')
if x_block.shape[0] != y_block.shape[0]:
x_block = self.xp.broadcast_to(
x_block, (y_block.shape[0], x_block.shape[1]))
eos_flags += (ys == 0)
if self.xp.all(eos_flags):
break
outs = [[wi for wi in sent if wi not in [2, 0]] for sent in result]
outs = [sent if sent else [0] for sent in outs]
return outs
def get_topk(x, k=5, axis=1):
ids_list = []
scores_list = []
xp = cuda.get_array_module(x)
for i in range(k):
ids = xp.argmax(x, axis=axis).astype('i')
if axis == 0:
scores = x[ids]
x[ids] = - float('inf')
else:
scores = x[xp.arange(ids.shape[0]), ids]
x[xp.arange(ids.shape[0]), ids] = - float('inf')
ids_list.append(ids)
scores_list.append(scores)
return ids_list, scores_list
他HTML等部分
templates/chat.html
<!DOCTYPE html>
<html>
<head lang="ja">
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>会話不成立ボット</title>
# スタティックファイルからスタイルシートを呼び出す。
<link rel="stylesheet" href="{{ url_for('static', filename='css/style.css') }}" >
# JQuery bootstrap font-awesomeをCDN使って読み込む
<script src="https://ajax.googleapis.com/ajax/libs/jquery/3.2.1/jquery.min.js"></script>
<link href="https://maxcdn.bootstrapcdn.com/bootstrap/3.3.6/css/bootstrap.min.css" rel="stylesheet">
<link href="https://maxcdn.bootstrapcdn.com/font-awesome/4.6.3/css/font-awesome.min.css" rel="stylesheet">
</head>
<body>
<div class="container background-color: rgb(255,0,255);">
<div class="row">
<h3 class="text-center header_text">
会話不成立ボット
</h3>
<div class="col-md-4 col-md-offset-4">
<div id="chatPanel" class="panel panel-info">
<div class="panel-heading">
<strong> 会話不成立ボットです。話しかけてください</strong>
</div>
# 応答生成をAJAXを使ってページ更新しないで表示させていく部分。
<div class="panel-body fixed-panel">
<ul class="media-list">
</ul>
</div>
# ユーザーが文字を入力し、SENDボタンを押し
# POSTリクエストがされると、AJAXがそれを感知して
# 応答文をFlask APIから取ってきて、
# HTMLファイルをその場で作成するためのHTML。
<div class="panel-footer">
<form method="post" id="chatbot-form">
<div class="input-group">
<input type="text" class="form-control" placeholder="Enter Message" name="messageText" id="messageText" autofocus/>
<span class="input-group-btn">
<button class="btn btn-info" type="button" id="chatbot-form-btn">SEND</button>
</span>
</div>
</form>
</div>
</div>
</div>
</div>
</div>
# javascriptの部分。
<script src="http://code.jquery.com/jquery-1.12.4.min.js"></script>
<script src="https://maxcdn.bootstrapcdn.com/bootstrap/3.3.6/js/bootstrap.min.js"></script>
<script>
# ID chatbot-form-btnのボタンがクリックされると、
# イベント(e)を受け取り処理する関数を発動。
# preventDefault()によってデフォルトの動作を阻止。
#(SENDクリックはすぐさまPOST送信をして、ページを変移させてしまう)
# javascriptでフォーム送信を処理するようにする。
$(function () {
$('#chatbot-form-btn').click(function (e) {
e.preventDefault();
$('#chatbot-form').submit();
});
# フォーム送信を受け取ったら、
# 同じようにデフォルト動作を阻止して、
# インプット要素で送った文字を変数に格納。
# クラスmedia-listのulタグ内に生のHTMLで書いた、liタグを作る。
$('#chatbot-form').submit(function (e) {
e.preventDefault();
var message = $('#messageText').val();
$(".media-list").append(
'<li class="media"><div class="media-body"><div class="media"><div class="media-body">ユーザー:' +
message + '<hr/></div></div></div></li>');
# AJAXを使い非同期に処理する。
# POST通信でurlが"/ask"
# serializeするー> (id=messageText&name=messageText)
# Flask APIは’/ask’をルーティングして、
# POSTリクエストを感知。
# 処理を発動させて、最終的な応答文をJSON形式で
# レスポンスとして返してくる
# その冒頭部分で成功したら「StatusはOK」になっているので、
# Success以下の処理が行われる。
# 応答文生成の際スクロールさせたいが、
# そのアニメーション処理を1000ミリ秒(1秒)ストップさせる処理
# なんかしらのAPIエラーが生じたらコンソールログにエラー内容を表示させる。
$.ajax({
type: "POST",
url: "/ask",
data: $(this).serialize(),
success: function (response) {
$('#messageText').val('');
var answer = response.answer;
const chatPanel = document.getElementById("chatPanel");
$(".media-list").append(
'<li class="media"><div class="media-body"><div class="media"><div class="media-body">ボット:' +
answer + '<hr/></div></div></div></li>');
$(".fixed-panel").stop().animate({
scrollTop: $(".fixed-panel")[0].scrollHeight
}, 1000);
},
error: function (error) {
console.log(error);
}
});
});
});
</script>
</body>
</html>
static/css/style.css
# この辺は自由にいじって遊んでいいと思いMASU
body {
background: #fff;
}
.row{
background-color: floralwhite;
}
.fixed-panel {
min-height: 450px;
max-height: 450px;
background-color: #19313c;
color: white;
overflow: auto;
}
.media-list {
overflow: auto;
clear: both;
display: table;
overflow-wrap: break-word;
word-wrap: break-word;
word-break: normal;
line-break: strict;
}
.panel {
margin-bottom: 20px;
background-color: #fff;
border: 6px solid transparent;
border-radius: 25px;
}
.panel-info {
border-color: #8ef13c;
}
.panel-info>.panel-heading {
color: #fff;
background-color: #8ef13c !important;
border-color: #0c2735;
}
.panel-footer {
padding: 10px 15px;
background-color: #0c2735;
border-top: 1px solid #0c2735;
border-bottom-right-radius: 3px;
border-bottom-left-radius: 3px;
}
.leave_form{
font-size: 16px;
margin-top: 2px;
color: #0c468f;
text-align: center;
font-weight: bold;
}
.leave_empid{
margin-top: 10px;
color:#0c468f;
width: 100%;
}
.leave_password{
margin-top: 10px !important;
color:#0c468f;
}
動かす
python main.py
port:5000番で待機してるので、
ブラウザを立ち上げ、
以下を入力。
localhost:5000
こんな感じだYO
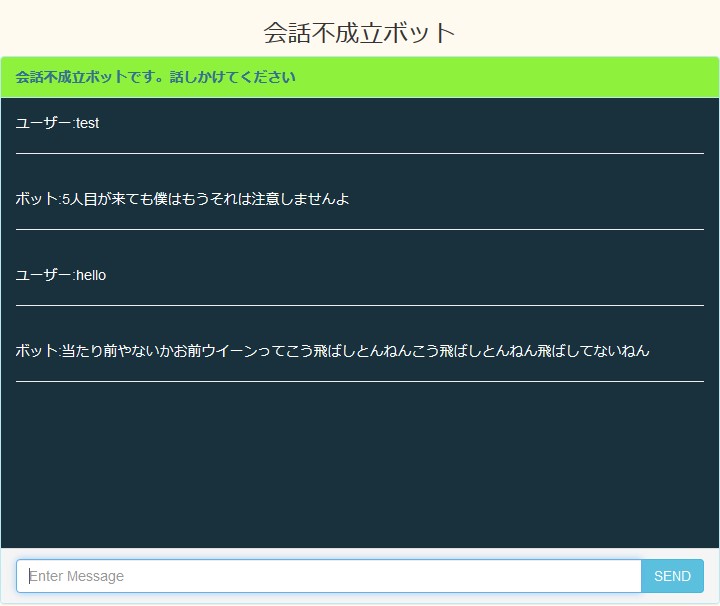
AWS再び
前回 同様にターミナルでAWSアクセスします。
アクセスしたら アプリのフォルダを作る アンド 移動.
$ mkdir flaskapp $ cd flaskapp
ファイル転送ソフトで, 上で作ったファイルを転送。
WindowsならWinScpとか、 MacならSyberduckとか、
WinScpですが、詳しくはこちら
Nginx設定
ファイルをアップロードし終えたら、 まずNginxの設定をします。
$ cd /etc/nginx $ cd sites-available $ sudo vi flaskapp

設定ファイルの中身は 80番ポートを開放して 待ち受ける パブリックIPアドレスを サーバーネームにする。
server {
listen 80;
server_name (your public ip address);
location = /favicon.ico {access_log off; log_not_found off;}
location /static/ {
root /home/(your user name)/flaskapp;
}
location / {
include proxy_params;
proxy_pass http://unix:/home/(your user name)/flaskapp/flaskapp.sock;
}
}
favicon.icoがないと 怒られるのを防ぐための設定。
(favicon.icoとは、 よくあるブラウザのタグ画像です。)
(例えばYoutubeならタグに赤と白の再生マークが小さく出ているはずです)
staticファイル(CSSや画像など)を どこから見つけるかを設定
プロキシー設定をソックファイルとして 書き出す。
(プロキシーとは「代理」です。 何かの代わりに、 行動をしてくれる存在です。 不動産賃貸業で例えるなら 大家さん(WEBサーバー) 借りたい人(ブラウザ) その間を取り持ってくれる業者が プロキシーにあたります。 直接でも取引できますが、 双方都合が悪く 負担が大きくなってしまうので 仲介業者を使うのが一般的です。
ここではNginxが プロキシーWebサーバー として、Gunicornとやりとりをして GunicornはPythonプログラムと やりとりをする プロキシーWSGIサーバー と言えます。
WEBサーバーとのやりとりも このようにそれに特化した 働きをするプロに任せたほうが 速度や安定性で優れることが あります。
このように処理の負荷を分散させることも デプロイに必要です。 ん〜〜、大変。
そしてSockとはソケットの意味で、 これが、またプロキシーとして サーバー間を取り持ってくれます。
色々と細かい部品があるんですね〜。
セキュリティグループの変更
忘れずに80番ポートを開放させてあげてくだちぃ。
AWSのアカウントコンソールからEC2を選択して、セキュリティグループをクリック。

インバウンドから編集を押して、 以下のように設定し保存。


またターミナルへ戻って、
$ sudo ln -s /etc/nginx/sites-available/flaskapp /etc/nginx/sites-enabled/
保存したら、上のコマンドを実行。 シンボリックファイルを作ります。
シンボリックファイルとはショートカットみたいなもんで、 実行ファイル自体は別の場所に ありますが、実行ファイルと同じ 働きをしてくれるファイルのことです。
こうしないと上手く動かないので 面倒くさいですが、設定しましょう。
$ sudo nginx -t
そして、テストオプションをつけて うまくいくかテストします。
上手くいったらNginxを再起動して、
デフォルトの8000番ポートを無視するよう設定し、 新たなファイアーウォールの設定をし直します。
$ sudo systemctl restart nginx $ sudo ufw delete allow 8000 $ sudo ufw arrow 'Nginx Full'
そして次に、 AWSからログアウトしても Gunicornが動いてくれるように、 自動起動の設定をしていきます。
systemdというシステムの デーモンを設定する場所に Gunicorn用のデーモンファイルを作ります。
デーモンとは裏でずっと稼働して、 ユーザーの操作とは関係なしに、 様々な処理をするやつのことです。
こういったシステム関連が集まっているダイレクトリは etcという名前で存在しています。
$ sudo vi /etc/systemd/system/gunicorn.service
Afterとはどのタイミングで起動するかを設定します。
ここではネットワークの構築が完成したらとします。
GroupとはどのHTTPプロキシを利用するか、
ここではNginxをが利用できるにします。
ExecStartにGunicornの起動コマンドを書きます。
Workerとは、簡単に説明すると アプリケーションの処理と(ここでいう応答文の生成) UIの処理(ブラウザ表示を描画している処理) の作業分担を分けることで、処理の遅延をなるべく減らす働きをします。 Worker(労働者)ですね。 しかし、UNIXのKIllコマンドといい、 表現が生生しいですよね。。。
Installはどのユーザーを使って実行させるかです。
この場合マルチユーザー、つまり、root(所有者権限)以外のユーザーでも
使用できるようにするということです。
WindowsにしろMacにしろLinuxにしろ、複数のユーザーを切り替えて
作業していきますが、
シングルユーザーただ一人では、root権限に切り替えて、動作させなくてはならないので、
登録してあるユーザーであれば(この場合あなたがEC2を作る際登録したユーザー)
このスクリプトを実行できますよとしてあげれば、
スムーズにGunicornを動かすことができるのです。
[Unit] Description=gunicorn daemon After=network.target [Service] User=ubuntu Group=www-data WorkingDirectory=/home/(your user name)/flaskapp; ExecStart=/home/(your user name)/(your pyvirenv name)/bin/gunicorn --access-logfile - --workers 3 --bind unix:/home/(your user name)/flaskapp.sock main:app [Install] WantedBy=multi-user.target
ファイルの実行権限を変えてあげます。
755は八進数の割当で、
r(読み込み)ー>4
w(書き込み)ー>2
x(実行)ー>1
のようになっており、
さらに3つのグループに分けられて、
「自 分」 → r+w+x = 4+2+1 = 7
「グループ」→ r+x = 5
「他 人」→ r+x = 5
とします。
何故八進数かはご覧の通り、
3つの数字の組み合わせでそれぞれの役割が再現できるからなのです。
$ sudo chmod 755 /etc/systemd/system/flaskapp.service
最後にGunicornを動かします。
$ sudo sytemctl start gunicornおっとその前に!
Chainerのモデル作りの際に 一時的にメモリが大量に 使われるので、 ここでEC2 t2.microに対して、 Swapの設定が必要です。
Swapとは簡単に説明すると、 メモリが一杯になった時、 HDに使っていないメモリの情報を 一時的に移して、 メモリ容量を空け、 メモリを物理的に多く使えるように することをいいます。
もちろんメモリ使用量が 多くなればなるほど HDとのやりとりが増えて、 速度が遅くなります。 (メモリの処理のほうが、 HDの処理よりも速いんです。)
$ sudo dd if=/dev/zero of=/swapfile1 bs=1M count=512 $ sudo chmod 600 /swapfile1 $ sudo mkswap /swapfile1 $ sudo swapon /swapfile1 $ sudo sh -c 'echo "/swapfile1 none swap sw 0 0" >> /etc/fstab' $ echo 10 | tee /proc/sys/vm/swappiness $ echo vm.swappiness = 10 | tee -a /etc/sysctl.conf
1Mのブロックを512個で合計512Mのファイルを/swapfile1として作成して、 アクセス権限を変更。使用者のみ600(R(4)+W(2))読み書きができるようにする。 スワップ領域を作成して有効化。 再起動してもスワップ領域がマウントされるように/etc/fstabに追加。 teeコマンドは標準出力の結果を表示と同時にファイルに書き込むことができるコマンドで〜す。 スワップすると、ファイルI/Oが発生するので、遅くなるので、スワップの頻度を少なく10に設定。
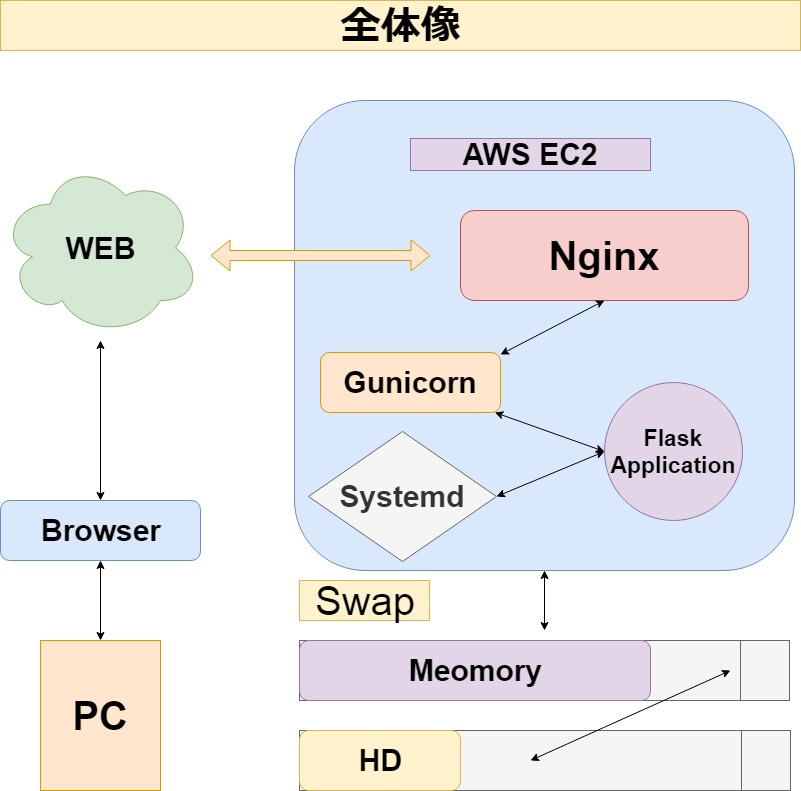
これまでの流れの簡単な模式図。
実食!
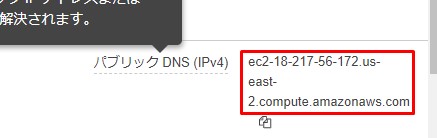
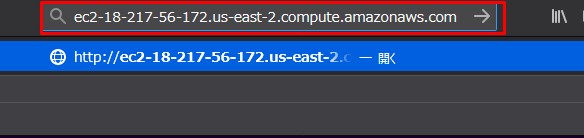
EC2ダッシュボードから パブリックDNSのアドレスを コピーしてブラウザに貼り付けて検索
主に必要になってくるのが、
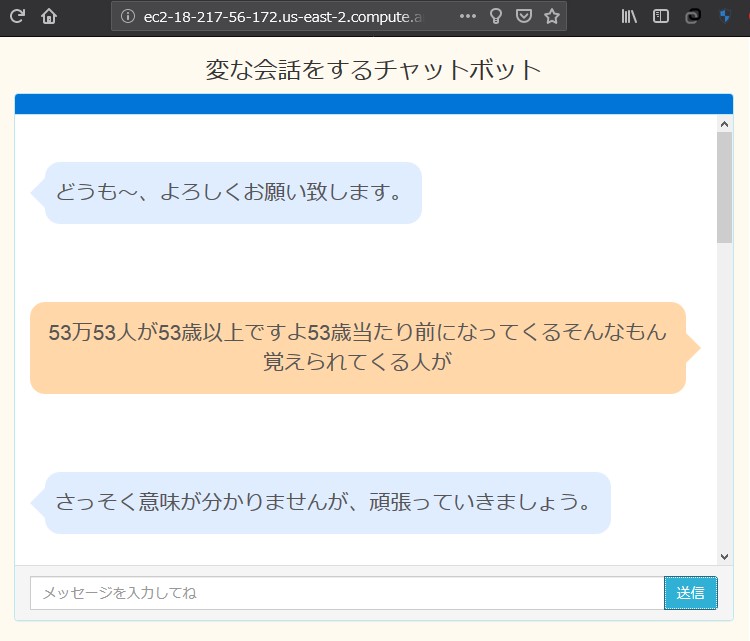
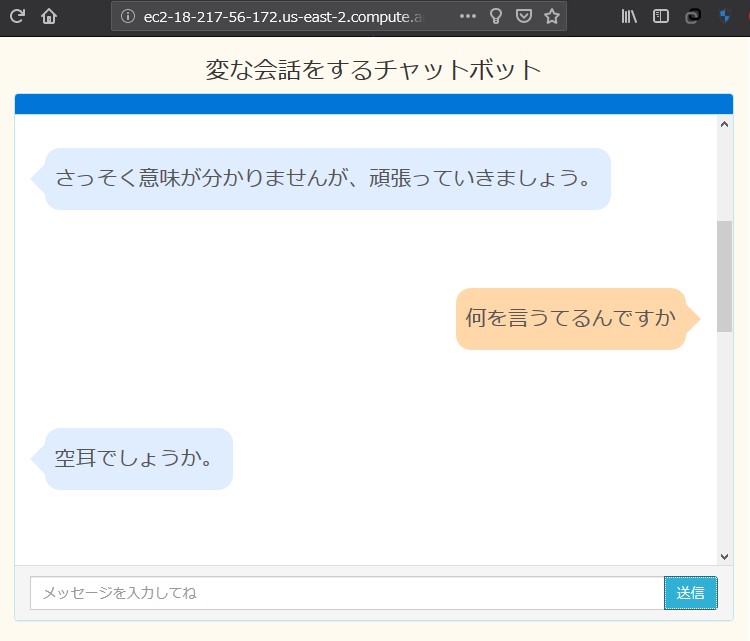
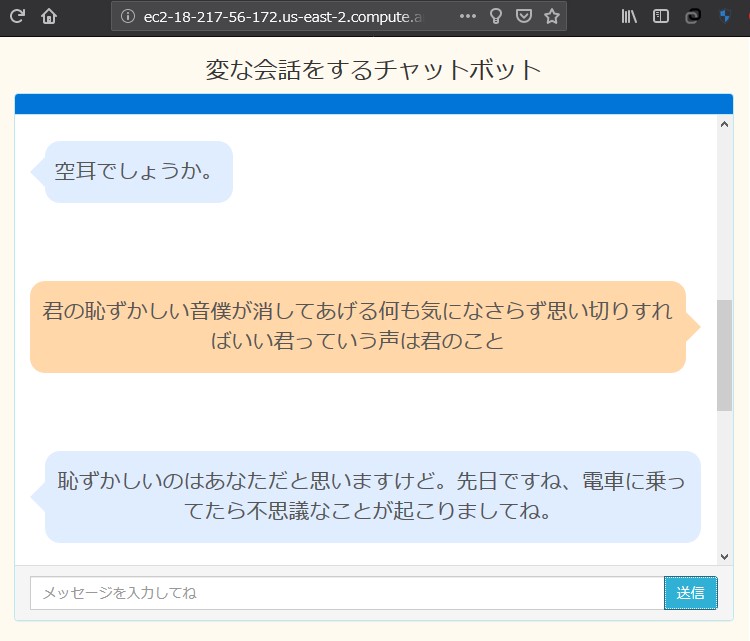
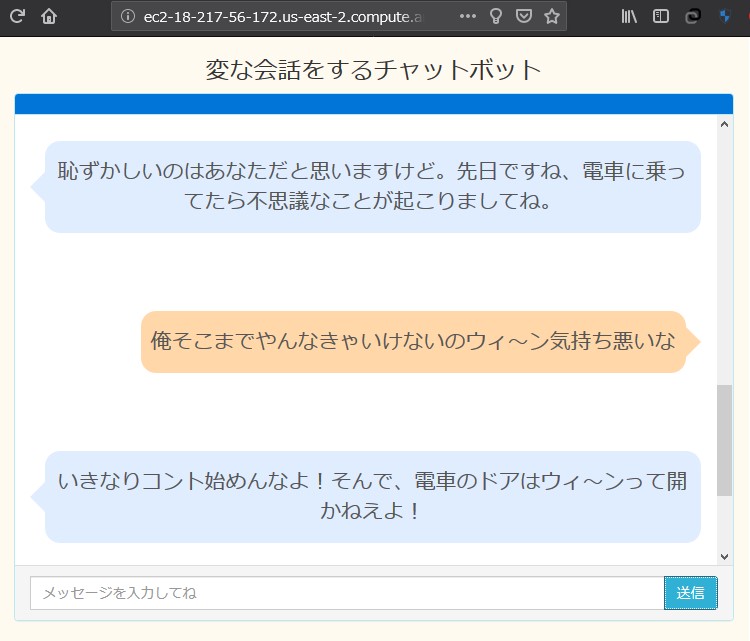
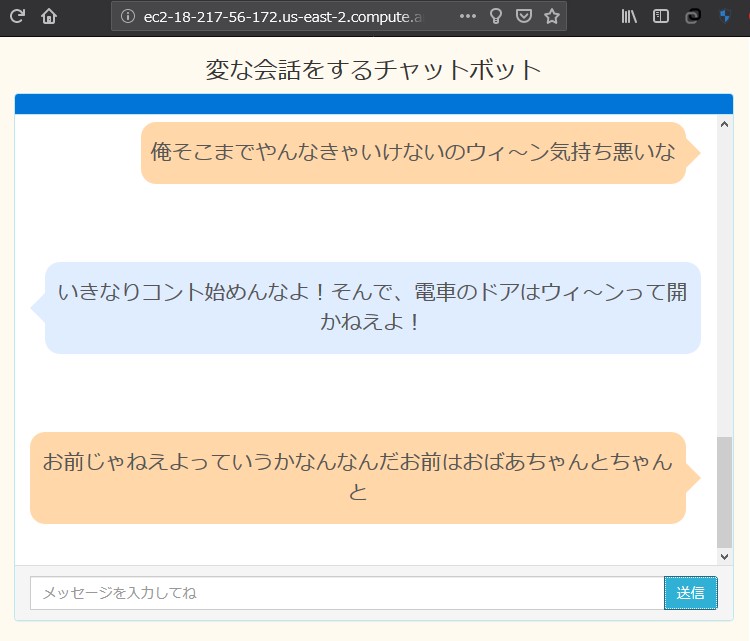
なんかちょっと出来の悪い
オードリーっぽくなってますが、
遊びならこの程度で十分。。。と思いたい。
次回へ続く
何かしらエラーが発生したら、 その都度エラーの言葉でググって、 StackOverflow等の賢者達に助けて貰ってください。
次回はオマケでHerokuにデプロイです。 AWSに比べたら、Herokuは簡単です。
ただ使用メモリのSwapを設定し、 Workerを小さくしても、 対処できないことがあります。 Freeプランは最大512Mbだったはず。
その場合は。。。有料プランへお布施DESU。。。
See You Next Page!