Published Date : 2019年7月10日18:22
Deep Manzai Part 8 〜 Herokuデプロイ編 〜
前回の簡単なあらすじ
2: AWSの設定、デプロイ。
お次はHeroku、DESU!
Heroku
超簡単にHerokuの説明。
前回AWSの設定と、 デプロイまで行いましたが、 設定が多くて大変じゃなかったですか?
3、4年前、CentOS7で Apachの設定からとかから始まり、
Wordpressでブログサイトを 作るまでやってみたのですが、 (全く忘れてしましましたが。。。)
あの時の「面倒くさい」記憶だけが 鮮やかに蘇りました。
iptable(CentOS7はfirewalldでした。) の設定やらなんやらで、 「自分はいつになったら ブログサイトを作れるんだ??」 とイライラしていました。
あの設定を全てすっ飛ばして アプリに必要最低限のファイルを
リソースを提供しているクラウドサービスに 渡すだけで、ウェブでアプリが 速攻使用できるようになればいいですよね。
そうすればWebアプリを作ること だけに集中できる。
そんな魔法のような クラウドサービスないかな。 そう、Herokuならできるんです。
しかもある程度まで無料で。
まさに、「そう、Herokuならね。」
前置きが長くなりましたが、 さっさと登録して、 HerokuCLIをインストールして コマンドプロンプトや ターミナルでHerokuにログイン アンド操作できるようにしましょう。
登録からHerokuCLI
この後メール確認、 パスワード設定、 クレジットカード入力 (無料プランを選べば、引き落としはされない)
等の試練をくぐり抜けます。
無事アカウントが作成できたら、 一度試しにログイン。
ターミナル等で操作できるようにしましょう。
ここにアクセスして、 各OS毎にインストール。
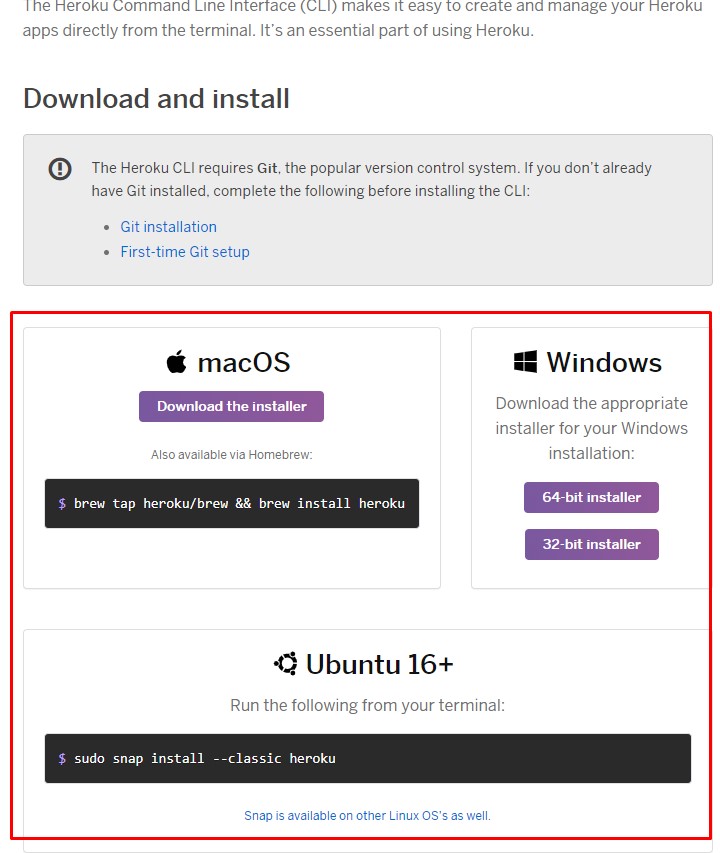
インストールは自動ですぐ終わりますが、 何かあったらとりあえず、ググる。
参考になりそうなサイトは
Heroku初心者がHello, Herokuをしてみる
Troubleshooting
Step 1: Herokuアカウントとコマンドラインツール(CLI)をセットアップしよう!
Heroku開発におけるHeroku CLI
CLIでログインしてみる
作れたら、 前回作ったファイルや フォルダをコピーします。
新規で作るのは この3つのファイルだけ。
ひとまず、このフォルダ内で ターミナルを立ち上げMASU。
立ち上げたら以下のコマンドを打つ。
heroku login
heroku: Press any key to open up the browser to login or q to exit:
こんな文字がでますので、エンター。
ブラウザが立ち上がるので、 パスワードを入力してログイン。

ダメそうなら、以下を試す。
コマンドライン上でログインする。
heroku login -i heroku: Enter your login credentials Email [[email protected]]: Password: **************** Logged in as [email protected]
無事ログインできたら、 以下のコマンドで Python仮想環境を作っておく。
python -m venv (適当な仮想環境名)venvはPython3.3以降 Pythonに標準装備された 仮想環境用ライブラリ。
仮想環境に没入。
mac,linux
source (作った仮想環境名)/bin/activatewindows
.\(作った仮想環境名)\Scripts\activateアーライ!没入したらこんな感じになる。
(作った仮想環境名) C:\your\app\dir>それぞれ古いのでアップデートする。
python -m pip install --upgrade pip
python -m pip install --upgrade setuptools必要なライブラリをインポート!
pip install dill chainer flask janome gunicornHerokuが、 仮想環境からGunicornによる起動、 必要なライブラリの自動インストールを 行えるように、前述の3つの 必要なファイルを用意する。
requirements.txt
pip freezeは インストール済みの パッケージ一覧を見ることができる。
それをrequirements.txt という名前で書き出す。
pip freeze > requirements.txt
Procfile
Procfile(拡張子はいらない) という名前のファイルを作り、 以下のように書いてNE。
web: gunicorn main:app -b 0.0.0.0:8000 --log-file=-
プロセスタイプはWEBで、 Gunicornを起動だよ。 アプリ本体はmainだよ。 お馴染みで0.0.0.0:8000でバインドするよ。 ログを表示するよ。 という意味。
HerokuはProcfileというファイルを 見つけると、「これが俺様に実行して欲しい スクリプトか、ふざけるな!下等生物が! 誰が実行するものか! 。。。しかし今日は機嫌が良い。 仕方がない、今回だけだぞ!」 てな感じでツンデレ実行してくれる。
runtime.txt
どの言語を 利用してるかHerokuに 知らせるためのファイル。
python -V
Python 3.7.1中身はこんな感じ。
python-3.7.1
必要なファイルを用意できたら、 gitにリモートリポジトリを作る。
git init
リモートリポジトリとは、 簡単に説明すると、 フォルダやファイルがどうなっているか 記録しておく場所がリポジトリで、 みんなが見れて管理できる場所がリモートです。
空のリポジトリが作られたので
ローカルフォルダに 「.git」というフォルダが作られている。
このフォルダは単純にいうと、 リポジトリという記憶装置を作る為の,必要なすべての情報が詰まっているYO!
続いてHerokuにアプリを作る。
ついでにPythonで作った言語はPythonですよと伝える。
heroku create (アプリの名前) --buildpack heroku/python
Herokuにアプリがあるか確認。
heroku apps
=== [email protected] Apps herokuflaskapp
gitのリポジトリとHerokuのアプリを紐付ける。
heroku git:remote -a (アプリの名前)
リポジトリに作ったファイル、フォルダを加える。
git add .
「.」はこのダイレクトリにある全てのフォルダ、ファイルという意味で、 必要なファイルだけ加えたい場合は「git add spam.txt」のようにする。
コミットする。
git commit -m "my first app"
「add」すると ローカルリポジトリに変更する準備が整い、 「commit」すると ローカルリポジトリに変更が反映されます。 「コメント」があると 何をどう変更したかが分かるので付けたほうが良いYO。
準備が整ったのでgitにプッシュして同時にHrokuに反映させる。
git push heroku master
地道に待ちます。

Chainerデータ
似 てる 似 てる わ お前 は 0 人 中 0人 に 似 てる よ お前 ややこしい 顔 し てる わ .そんな こと ない です よ .いや 下手 な ほう です よ .うま ない 言う てん ねん .何 も 言う て くれ て へん が な .出 ます ね .声 じゃ ない ん です よ 歯茎 が ものすごく 出る ん です そっち が 気 に なっ て 歌 聴い て なかっ た .歌っ てる とき よ .笑っ て よ の とこ .
こんな感じで、 それぞれ、encode_train_data.txt、 decode_train_data.txt、 encode_valid_data.txt、 decode_valid_data.txt、 4つのテキストファイルは 既に分かち書き済みで 記号は無くして、 数字は0に、改行無しで「.」で繋がってます。
データの分かち書きとかは前々々回あたりを参考にしてくだちぃ。
後はオリジナルソースの通りに データをコンバートしていくだけです。
ちょっとだけ改良した場所といえば、preprcess.pyの部分。ioから呼び出すところを 通常のテキストファイルを呼び出すようにしたところと、
split_sentenceぐらいでしょうか。
def open_file(path): return io.open(path, encoding='utf-8', errors='ignore')
# open_file を消して以下に統一 with open(path, 'r',encoding='utf-8') as f:
# 読み込んだファイルを「.」で区切ったリストにして返すだけに変更
def split_sentence(f):
return f.read().split('.')
後はできたファイルを Pickleで保存してダウンロードするだけ。
import dill
with open('data/souce_ids.pkl','wb') as f:dill.dump(source_ids,f)
with open('data/target_ids.pkl','wb') as f:dill.dump(target_ids,f)
with open('data/souce_words.pkl','wb') as f:dill.dump(source_words,f)
with open('data/target_words.pkl','wb') as f:dill.dump(target_words,f)
デフォルトのハイパーパラメータだと、 メモリオーバーになるので、 Batchサイズは24ぐらいにしとくのが吉。
実食 アンド 次回へ続く
remote: Successfully installed Click-7.0 Flask-1.1.1 Janome-0.3.9 Jinja2 2.10.1 MarkupSafe-1.1.1 Werkzeug-0.15.4 chainer-6.1.0 dill-0.3.0 filelock-3.0.1 gunicorn-19.9.0 itsdangerous-1.1.0 numpy-1.16.4 protobuf-3.7.1 six-1.12.0 typi g-3.6.6 typing-extensions-3.6.6 remote: remote: -----> Discovering process types remote: Procfile declares types -> web remote: remote: -----> Compressing... remote: Done: 389.5M remote: -----> Launching... remote: ! Warning: Your slug size (389 MB) exceeds our soft limit (300 MB) which may affect boot time. remote: Released v3 remote: https://yourappname.herokuapp.com/ deployed to Heroku remote: remote: Verifying deploy... done. To https://git.heroku.com/yourappname.git * [new branch] master -> masterメモリやばいよって出てますね。
案の定
heroku openでアプリを見に行くと、
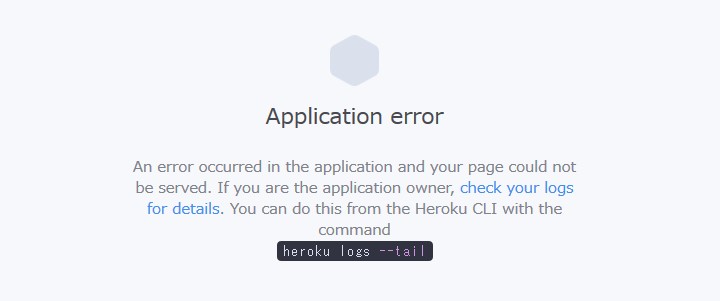
支持通りログを見に行くと、
heroku logs --tail
Error R14 (Memory quota exceeded Process running mem=702M(136.9%) Stopping process with SIGKILL State changed from starting to crashed
Worker数を減らしたり、
heroku config:set WEB_CONCURRENCY=1
公式 に従って色々やりましたが、 自分には無理ゲーでした。
つーことで有料版へお布施か もっと良いやり方を探すしかなさそうっすね。
ちなみにデータのロードで 「そんなパス存在しないよ!」 って怒られたら。
heroku run bash --app (appName)
cd data
pwd --> /app/data/みたいになってるんで、 書き換えてNE。
Herokuで初めてデプロイしましたが、 AWSよりかは簡単ですけど、 フリー版はそれなりなんですね。
Herokuの良さはデプロイの速さなので、 こんなところで躓いていたら意味がないので、 先に進みMASU。
See You Next Page!