Published Date : 2019年12月24日20:56
p5.jsとnumjs - 文字列操作
p5.js and numjs - String operations
This blog has an English translation
今回の記事はちょっと視点を変えて、p5.jsとnumjsを使って自然言語処理をしてみたいと思います。
In this article, I want to change my perspective a bit and try natural language processing with p5.js and numjs.
もちろん、P5はJavascriptで作られているので、P5内でJavascriptそのものが使えます。 なので、基本P5で書いていきますが、P5では難しい文字列処理等はJavascriptでそのまま書いていきます。
Of course, p5.js is written in Javascript, so you can use it directly in p5.js. I usually write code in p5.js, but there many things that are difficult to process in p5.js (String operations, etc.), so if I encounter such a situation, I write code directly in Javascript.
目次
Table of Contents
概要
Summary
簡単な概要です。
Here's a quick overview.
まずこの記事の趣旨は、 NumjsというNumpy(Python)のJavascriptヴァージョンを使用して、 ML.js等のライブラリを使わずにできるだけ1から自然言語処理の仕組みを理解することです。
First of all, the purpose of this blog post is use Numjs that a Javascript version of Python's Numpy, to understand how natural language processing works, without using libraries like ML.js.
機械学習用のライブラリを使えば簡単に事は進みますが、少しでも細かくその仕組みを知っておけば、色々なことに応用できると思います。
If you use a library for machine learning, things go easy, but I think if you know how the details of how machine learning works, you can apply it to many things.
ということで、簡単な文字列操作から行っていきます。
So let's start with a simple string operation.
文字列操作
String operations
ではp5.jsとJavascriptを使用して、簡単なテキストの前処理の為の文字列操作を説明していきまうす。
Here's how to do simple string operations for text preprocessing using p5.js and Javascript.
来年はねずみ年なので、マザーグースの6匹のネズミを使ってみませう。
Next year is the Mouse year ("Japanese zodiac". There are 12 animals, with one animal allocated to every year), so let's use "Six little mice sat down to spin?" from Mother Goose.
let sentences = `Six little mice sat down to spin,
Pussy cat passed and she peeped in.
What are you doing, my little men?
Weaving coats for gentlemen.
Shall I come in and cut off your threads?
No, no, pussy cat, you’d bite off our heads!
Oh, no, I’ll not, I’ll help you spin.
That may be so, but you don’t come in.`
let splitedSentences;
let word2Id = {};
let id2Word = {};
let corpus = [];
function setup(){
splitedSentences = sentences.toLowerCase().split(/\W+/g);
splitedSentences = subset(splitedSentences, 0, -1);
print(splitedSentences)
// It works the same as "enumerate" in Python (for idx,element in enumerate(array))
for (let [index, element] of splitedSentences.entries()) {
if (!(element in word2Id)) {
word2Id[element] = index;
id2Word[index] = element;
}
}
// It works the same as "for ~ in ~" in Python (for value in array)
splitedSentences.forEach(function( value ) {
corpus.push(word2Id[value]);
});
print(word2Id);
print(id2Word);
print(corpus);
}
出力は以下になります。 上から文を分割したリスト。 単語にIDをつけた辞書と、IDに単語をつけた辞書。 そして、単語をID化したリスト。
The output is as follows. From top to bottom, a list of sentences divided into words. A dictionary with ID attached to words and a dictionary with words attached to ID. And a list of words identified by a number.
(64) ["six", "little", "mice", "sat", "down", "to", "spin", "pussy", "cat", "passed", "and", "she", "peeped", "in", "what", "are", "you", "doing", "my", "little", "men", "weaving", "coats", "for", "gentlemen", "shall", "i", "come", "in", "and", "cut", "off", "your", "threads", "no", "no", "pussy", "cat", "you", "d", "bite", "off", "our", "heads", "oh", "no", "i", "ll", "not", "i", "ll", "help", "you", "spin", "that", "may", "be", "so", "but", "you", "don", "t", "come", "in"]
{"six": 0, "little": 1, "mice": 2, "sat": 3, "down": 4, "to": 5, "spin": 6, …}
{0: "six", 1: "little", 2: "mice", 3: "sat", 4: "down", 5: "to", 6: "spin", …}
(64) [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 1, 20, 21, 22, 23, 24, 25, 26, 27, 13, 10, 30, 31, 32, 33, 34, 34, 7, 8, 16, 39, 40, 31, 42, 43, 44, 34, 26, 47, 48, 26, 47, 51, 16, 6, 54, 55, 56, 57, 58, 16, 60, 61, 27, 13]
sentences.toLowerCase().split(/\W+/g);
スクリプトの細かい説明ですが、まず文を全て少文字に直します。 そこから正規表現を利用して文字以外(スペースやピリオド、感嘆符)等で文字を分割します。
As for the detailed description of the script, first, I will change all the sentences to small letters. From there, regular expressions are used to divide characters by non-characters (Spaces,periods,or exclamation marks ...etc).
(65) ["six", "little", "mice", "sat", "down", "to", … , ""]
すると、最後に空文字ができてしまうので、Subsetメソッドを利用して、最後だけ抜かしてリストに再格納します。
The result is an empty string at the end, so the subset method is used to skip the end and store it back in the list.
subset(splitedSentences, 0, -1);
(64) ["six", "little", "mice", "sat", "down", "to", …]
Entriesメソッドを利用して、リストのインデックス番号と要素をセットで抜き出していきます。
Use the Entries method to return a list of index numbers and elements.
for (let [index, element] of splitedSentences.entries())
一つの単語に対して、固有のIDを付けたいので、 If文を使って単語が辞書に含まれているかを判定します。 含まれていなければ辞書をつくります。
I want to add a unique ID to each word. Use the If statement to determine if a word is in the dictionary. If it is not included, add it to the dictionary.
if (!(element in word2Id))
{"six": 0, "little": 1, "mice": 2, "sat": 3, "down": 4, "to": 5, "spin": 6, …}
{0: "six", 1: "little", 2: "mice", 3: "sat", 4: "down", 5: "to", 6: "spin", …}
そして、numjsを使って計算したいので、番号だけのリストを作成します。
Then, because I want to calculate using numjs, I create a list of numbers only.
corpus.push(word2Id[value]);
(64) [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 1, …]
numjsの使い所
Where to Use numjs
詳しくは次回に内容を書きますが、numjsがこの後どこでどのように使われるのかを知っておいたほうがスッキリすると思います。
I will write the details next time, but I think you will be more convinced if you know where and how use numjs after manipulating the strings.
例えば、コサイン近似度という計算方法があります。
For example, there is a calculation method called cosine similarity
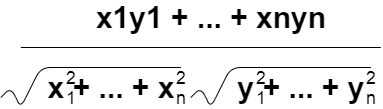
簡単に言ってしまえば、2つのベクトルが完全に同じ方向を向いていれば「1」、逆向きであれば「ー1」という数字を計算します。
Simply put, we calculate the number 1 if the two vectors are pointing in exactly the same direction, and -1 if they are pointing in the opposite direction.
スクリプトに直すとこんな感じです。
This is what it looks like in a script.
nx = x.divide((nj.sqrt(nj.sum(x.pow(2))).add(Number.EPSILON)).get(0));
ここで入力されているXはワンホットベクトルといって、 例えば「You and I」という文の、「You」なら「1、0、0」といった具合に、語彙数に対して単語をベクトル表現したものになります。
The input X is referred to as a one-hot vector, For example, "You" in the sentence "You and I" becomes "[1, 0, 0]". This is the vector equivalent of the word.
これをnumjs使わずに計算すると、Forループで回して、計算をして、値を別の変数に蓄積させて、さらにまたForループで計算することになります。
If you do not use numjs to compute this, you will have to go around in the "For loop", do the computation, accumulate the value in another variable, and then do the computation again in another "For loop".
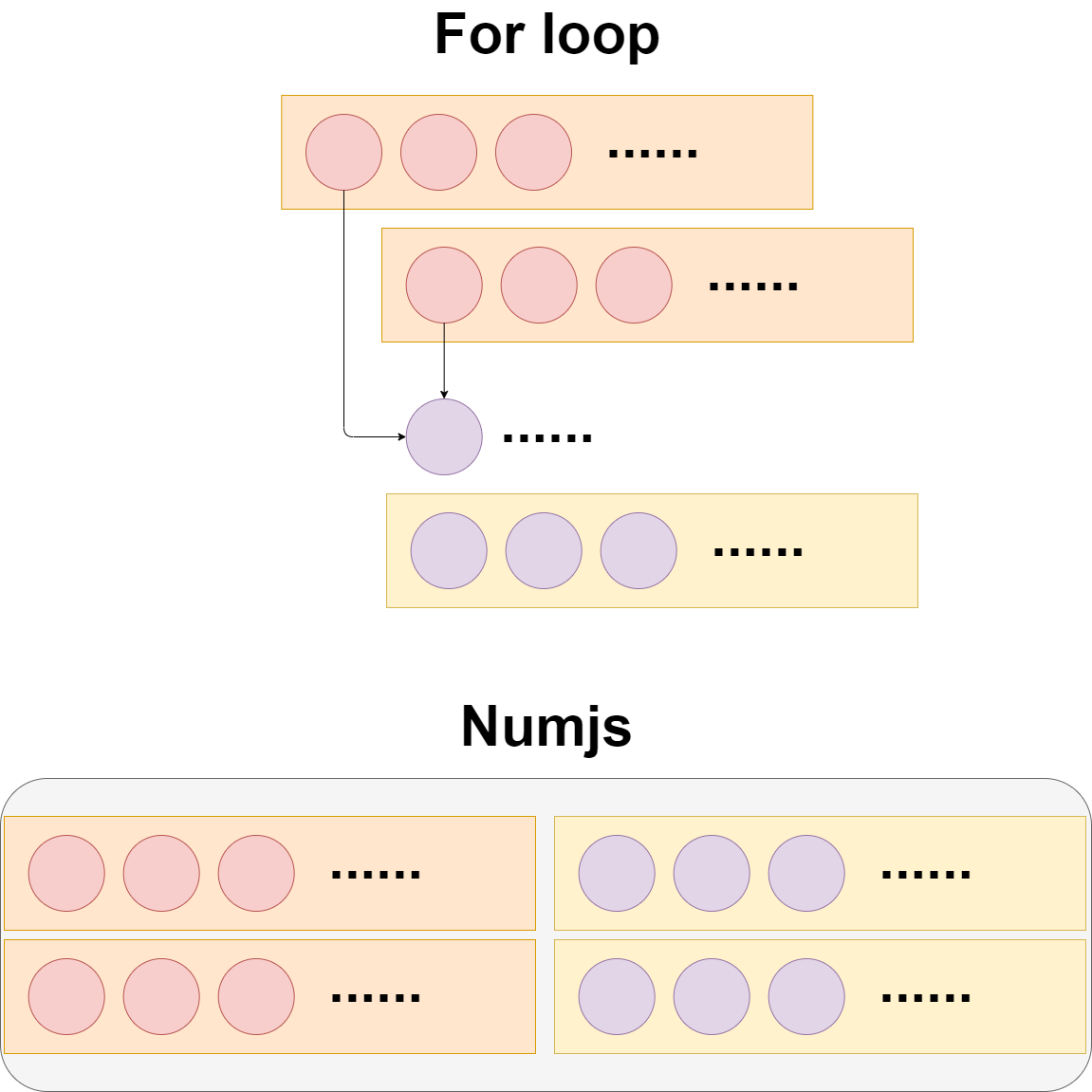
numjsを使えば、並列処理でベクトルの計算が一気に行えます。
With numjs, you can quickly compute vectors in parallel.