Published Date : 2019年12月25日22:57
p5.jsとnumjs - カウントベース手法
p5.js and numjs - Count Based
This blog has an English translation
今回の記事は、p5.jsとnumjsを使って自然言語処理のカウントベース手法を試したいと思います。
In this article, I'll try a count-based in natural language processing using p5.js and numjs.
もちろん、P5はJavascriptで作られているので、P5内でJavascriptそのものが使えます。 なので、基本P5で書いていきますが、P5では難しい文字列処理等はJavascriptでそのまま書いていきます。
Of course, p5.js is written in Javascript, so you can use it directly in p5.js. I usually write code in p5.js, but there many things that are difficult to process in p5.js (String operations, etc.), so if I encounter such a situation, I write code directly in Javascript.
目次
Table of Contents
概要
Summary
簡単な概要です。
Here's a quick overview.
まずこの記事の趣旨は、 NumjsというNumpy(Python)のJavascriptヴァージョンを使用して、 ML.js等のライブラリを使わずにできるだけ1から自然言語処理の仕組みを理解することです。
First of all, the purpose of this blog post is use Numjs that a Javascript version of Python's Numpy, to understand how natural language processing works, without using libraries like ML.js.
機械学習用のライブラリを使えば簡単に事は進みますが、少しでも細かくその仕組みを知っておけば、色々なことに応用できると思います。
If you use a library for machine learning, things go easy, but I think if you know how the details of how machine learning works, you can apply it to many things.
前回は簡単な文字列操作の説明を行いました。今回はnumjsを使って、共起行列を作たいと思います。
Last time we discussed simple string operations. This time, I'll use numjs to create a co-occurrence matrix.
共起行列
co-occurrence matrix
では前回のP5のスクリプトから始めます。
Let's start with the previous p5 script.
preprocess.jsという名前で保存してくだちぃ。
Please save as "preprocess.js"
preprocess.js
function preprocess(sentence){
let splitedSentences = [];
// It works the same as "for ~ in ~" in Python (for value in array)
sentence.forEach(function( value ) {
splitedSentences.push(value.toLowerCase().split(/[^’.\w]+/g).join(' ').replace('.',' .'));
});
splitedSentences = splitedSentences.join(' ').split(/[^’.\w]+/g);
splitedSentences = subset(splitedSentences, 0, -1);
let word2Id = {};
let id2Word = {};
// It works the same as "enumerate" in Python (for idx,element in enumerate(array))
splitedSentences.forEach(function( word ) {
if (!(word in word2Id)) {
let newId = Object.keys(word2Id).length;
word2Id[word] = newId;
id2Word[newId] = word;
}
});
let corpus = [];
// It works the same as "for ~ in ~" in Python (for value in array)
splitedSentences.forEach(function( value ) {
corpus.push(word2Id[value]);
});
// numjs courpus
let numcorpus = nj.array(corpus);
return [numcorpus,word2Id,id2Word];
}
引数に文章を受け取り、最後にコーパスをnumjsのndarrayに変えて、リストとして関数の結果を返してあげます。
It takes a sentence as an argument, changes the corpus to ndarray of numjs, and returns the result of the function as a list.
それでは必要な環境を整えましょう。
Then let's prepare the necessary environment.
working folder
your working directory
-- assets
-- sixLittleMice.txt
-- nlpExample.html
-- nlpExample.js
-- utils
-- preprocess.js
"6匹のネズミ"は「アセット」内にテキストファイルとして保存します。
Save "Six little mice sat down to spin" as a text file in the "assets" folder.
assets/sixLittleMice.txt
Six little mice sat down to spin, Pussy cat passed and she peeped in. What are you doing, my little men? Weaving coats for gentlemen. Shall I come in and cut off your threads? No, no, pussy cat, you’d bite off our heads! Oh, no, I’ll not, I’ll help you spin. That may be so, but you don’t come in.
続いてHTMLファイル。
Next, create an HTML file.
nlpExample.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<!-- p5.js cdn -->
<script src="https://cdnjs.cloudflare.com/ajax/libs/p5.js/0.6.1/p5.min.js"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/p5.js/0.6.1/addons/p5.dom.min.js"></script>
<!-- numjs cdn -->
<script src="https://cdn.jsdelivr.net/gh/nicolaspanel/[email protected]/dist/numjs.min.js"></script>
<!-- utils -->
<script src="../../utils/preprocess.js"></script>
<!-- sketch -->
<script src="nlpExample.js"></script>
<title>Document</title>
</head>
<body>
</body>
</html>
メインとなるJSファイルです。
Create the main JS file.
nlpExample.js
let result;
function preload(){
result = loadStrings("./assets/sixLittleMice.txt");
}
let word2Id;
let id2Word;
let corpus;
let arrOfResults;
let bocabSize;
function setup(){
arrOfResults = preprocess(result);
corpus = arrOfResults[0];
word2Id = arrOfResults[1];
id2Word = arrOfResults[2];
print("result: ", result);
print("corpus: ", corpus.toString());
print("word to id: ", word2Id);
print("id to word: ", id2Word);
bocabSize = Object.keys(word2Id).length;
print(bocabSize)
}
ここまでの結果は前回と同様です。 変更点はテキストファイルを読み込む際に、自動的に改行で分割されて、 リスト化されてしまっているので、文章の一行ずつ処理をしなければなりません。
The results so far are the same as before. But there are some changes. When you import a text file, it automatically becomes a list separated by newlines, so you must process each line of text.
nlpExample.js
sentence.forEach(function( value ) {
splitedSentences.push(value.toLowerCase().split(/[^’.\w]+/g).join(' ').replace('.',' .'));
});
それでは共起行列を作りましょう。
Let's make a co-occurrence matrix.
buildCoOccurrenceMatrix.js
function buildCoOccurrenceMatrix(corpus, vocabSize, windowSize = 1){
corpusSize = corpus.shape[0];
coOccurrenceMatrix = nj.zeros([vocabSize, vocabSize], 'int32');
for (let [idx, wordId] of corpus.tolist().entries()) {
let leftNum = 0
let rightNum = 0
for (let i = 1; i < windowSize + 1; i++) {
let leftIdx = idx - 1;
let rightIdx = idx + 1;
if (leftIdx >= 0) {
let leftWordId = corpus.get(leftIdx);
leftNum += 1;
coOccurrenceMatrix.set(wordId, leftWordId, leftNum);
}
if (rightIdx < corpusSize) {
let rightWordId = corpus.get(rightIdx);
rightNum += 1;
coOccurrenceMatrix.set(wordId, rightWordId, rightNum);
}
}
}
return coOccurrenceMatrix;
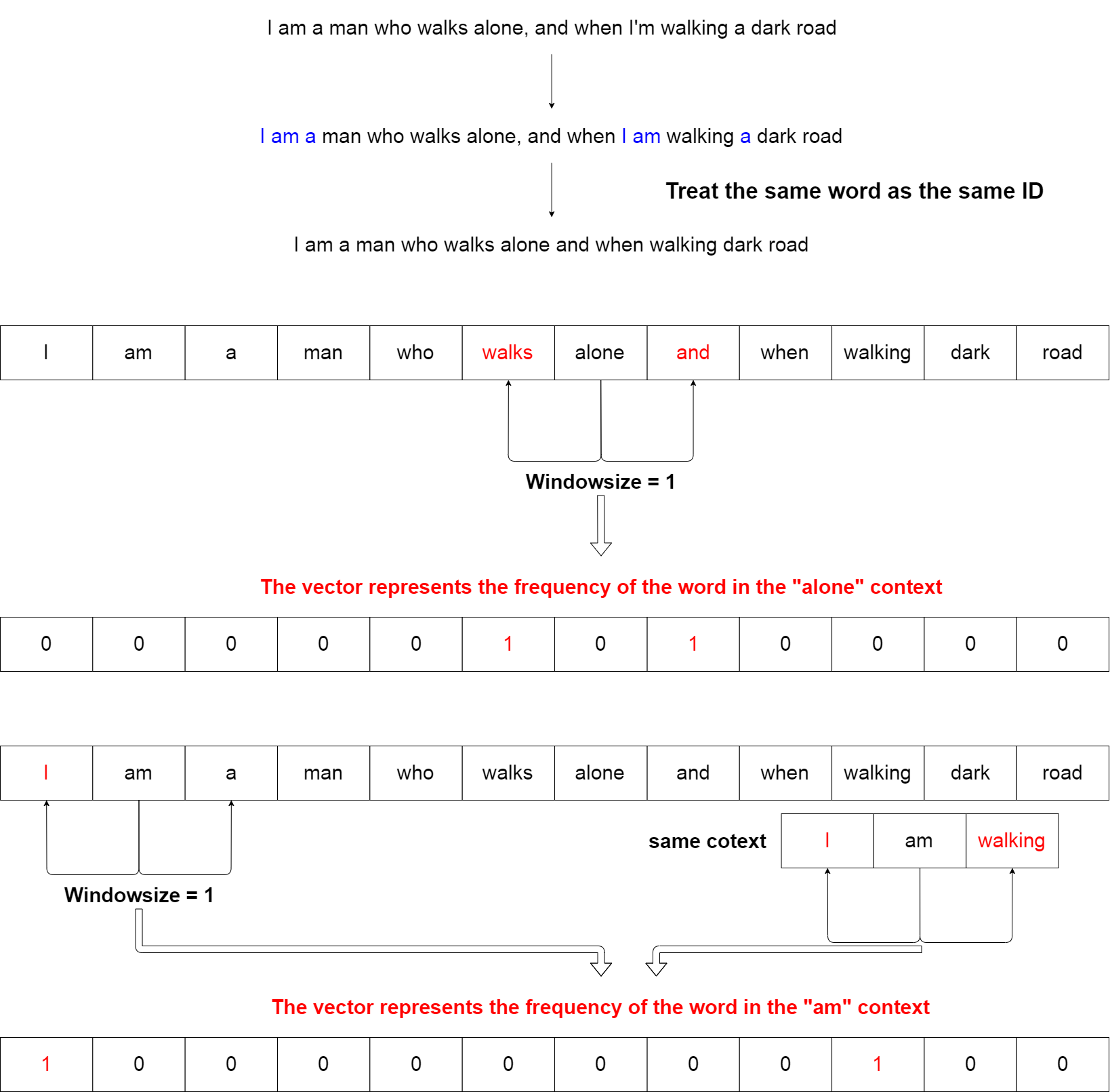
共起行列とは、ある単語の周辺に現れる単語をカウントして、その関係性をベクトル表現したものです。
A co-occurrence matrix is a vectors that represents the number of occurrences of words that are counted around a word.
coOccurrenceMatrix = nj.zeros([vocabSize, vocabSize], 'int32');
最初に語彙数分のゼロ行列を作ります。
First, make a zero matrix by the the vocabulary of words.
for (let i = 1; i < windowSize + 1; i++) {
let leftIdx = idx - 1;
let rightIdx = idx + 1;
Windowサイズが1なら、隣り合った単語を検索します。
A window size of 1 searches for adjacent words.
if (leftIdx >= 0) {
let leftWordId = corpus.get(leftIdx);
leftNum += 1;
coOccurrenceMatrix.set(wordId, leftWordId, leftNum);
}
if (rightIdx < corpusSize) {
let rightWordId = corpus.get(rightIdx);
rightNum += 1;
coOccurrenceMatrix.set(wordId, rightWordId, rightNum);
}
調べる単語が一番左端側なら、右側のみカウントします。 同じく一番右端なら左側をカウントします。 そうでないなら、単語の両端をカウントしていきます。
If the word is on the far left, count only the right side. If it is the rightmost, count only the left side. Otherwise, count both ends of the word.
結果は以下のようになります。
The result is as follows.
coOccurrenceMatrix array([[ 0, 1, 0, ..., 0, 0, 0], [ 1, 0, 1, ..., 0, 0, 0], [ 0, 1, 0, ..., 0, 0, 0], ... [ 0, 0, 0, ..., 0, 0, 0], [ 0, 0, 0, ..., 0, 0, 1], [ 0, 0, 1, ..., 0, 1, 0]], dtype=int32)