Published Date : 2019年10月22日1:08
架空のクラウドソーシング案件に挑戦してみる(3-5)
Try a Fictional Crowdsourcing Job(3-5)
This blog has an English translation
架空のお仕事をしてみる企画(3-5)です。
It's a project to try a fictitious job(3-5).
仮に自分がフリーランスで、 ある依頼者から適当な仕事を振られてみたら、 果たしてクリアできるのか?といった企画。
If i am a freelance programmer, When a client assigns a suitable job, Can I clear it? That's the plan.
この企画は架空のものですが、日本のクラウドソーシング市場に氾濫しているよくある案件と値段と工数を参考にしてます。
This project is a fictitious one, but it is based on common cases, prices and man-hours flooding the Japanese crowdsourcing market.
取り敢えず前回の続き
For the moment, Let's continue the last time
変更点
Changes
Collector4,5,6を作成。それにまた新しい機能を追加し、多少の変更を加えました。
Created Collector3,4,5. I've also added new features and made some changes.
ファイル構成は以下の通り
The file structure is as follows
prototype002
collectors
firstCollector.py
secondCollector.py
thirdCollector.py
fourthCollector.py
fifthCollector.py
sixthCollector.py
data
first_collection
settings.csv
second_collection
settings.csv
third_collection
settings.csv
fourth_collection
settings.csv
fifth_collection
settings.csv
sixth_collection
settings.csv
scripts
collectors_utils.py
chromedriver.exe
crowler.py
collector4,5,6.py
collector4,5,6.py
全体コードとほんのちょっと解説
General code and brief description.
fourthCollector.py
# wonderful spam!
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
#
from selenium.webdriver.support.ui import Select
import csv
import time
from datetime import datetime
import os,sys
##
import re
sys.path.append('./scripts')
import collectors_utils
# if you want to use choromedriver_binary
# import chromedriver_binary
# chromedriver_binary.add_chromedriver_to_path()
class FourthCollector():
def __init__(self, url, data_dir):
self.base_url = url
#
self.data_dir = data_dir
##
def close_modal(self, driver):
# try:
# WebDriverWait(driver,6).until(EC.visibility_of_element_located((By.XPATH,'//img[@id="ads-banner-img"]')))
# except:
# driver.find_element_by_xpath('//div[@id="cv-tech-modal-close"]').click()
try:
driver.find_element_by_xpath('//div[@id="cv-tech-modal-close"]').click()
except:
pass
##
def page_feed(self,driver, end_date, current_date, y,m,d):
##
if f'{y}/{m}/{d}' == end_date:
return True
else:
##
current_date.find_element_by_xpath('input[@id="search_tomorrow"]').click()
return False
def fetch_table_header(self, driver):
header_element = driver.find_elements_by_xpath('//tr[@id="search_head"]/th')
table_header = [e.text for e in header_element if e.text != '']
return table_header
def fetch_table_contents(self, driver, table_header):
try:
WebDriverWait(driver,6).until(EC.visibility_of_element_located((By.XPATH,'//div[@id="fare_list_new"]')))
except:
print('empty contents')
time.sleep(3)
# See if it's empty
content_elements = driver.find_elements_by_xpath('//div[@id="fare_list_new"]/table/tbody')
if content_elements != []:
table_contents = []
for c in content_elements:
temp_dict = {}
for idx,p in enumerate(c.find_elements_by_xpath('./tr/td')):
temp_dict[table_header[idx]] = p.text.replace('\n','->')
if p.text.replace('\n','->') == '':
pass
else:
table_contents.append(temp_dict)
return table_contents
else:
return None
def fetch_select_options(self, element):
select_element = Select(element)
select_options_dic = {option.text:option.get_attribute('value') for option in select_element.options if option.text != '出発地'}
return select_element, select_options_dic
#
def set_dep_date(self, start, dep_date, driver):
start = start.split('/')
# set year
year = driver.find_element_by_xpath('//input[@id="departure_date[y]"]')
driver.execute_script(f'arguments[0].setAttribute("value", "{start[0]}")', year)
# set month
month = driver.find_element_by_xpath('//input[@id="departure_date[m]"]')
driver.execute_script(f'arguments[0].setAttribute("value", "{start[1]}")', month)
# day
day = driver.find_element_by_xpath('//input[@id="departure_date[d]"]')
driver.execute_script(f'arguments[0].setAttribute("value", "{start[2]}")', day)
##
def collect_price(self, driver, current_url):
# Load a file with specified conditions.
rows = collectors_utils.read_file(self.data_dir)
for row in rows:
try:
WebDriverWait(driver,30).until(EC.visibility_of_element_located((By.XPATH,'//select[@name="departure_airport_id"]')))
except:
print('element invisible')
driver.quit()
# Enterring the data of the imported file.
dep = row['dep']
des = row['des']
# Departure locations
dep_box = driver.find_element_by_xpath('//select[@name="departure_airport_id"]')
dep_box, select_options_dic = self.fetch_select_options(dep_box)
dep_box.select_by_value(select_options_dic[dep])
# Destination locations
des_box = driver.find_element_by_xpath('//select[@name="arrival_airport_id"]')
des_box, select_options_dic = self.fetch_select_options(des_box)
des_box.select_by_value(select_options_dic[des])
## dep-date
dep_date = driver.find_element_by_xpath(f'//input[@id="datePicker"]')
# set date
start = row['start']
end = row['end']
start_date_check = collectors_utils.check_date(start)
end_date_check = collectors_utils.check_date(end)
if start_date_check:
start = start.replace('/','/')
else:
start = collectors_utils.get_date()[0]
if end_date_check:
end = end.replace('/','/')
else:
end = collectors_utils.get_date()[1]
## enter departure date
self.set_dep_date(start, dep_date, driver)
# click search button
driver.find_element_by_xpath('//button[@id="js-btnSearchTicket"]').click()
# fetch table header
table_header = self.fetch_table_header(driver)
date_obj = datetime.now()
dir_date = datetime.strftime(date_obj,'%Y%m%d')
##
dir_name = f'片道-{dep.replace("/","")}-{des.replace("/","")}-{dir_date}'
if os.path.exists(f'{self.data_dir}/{dir_name}'):
pass
else:
os.mkdir(f'{self.data_dir}/{dir_name}')
while True:
current_date = driver.find_element_by_xpath('//p[@class="flightselect-cont"]')
current_date_text = current_date.text
y, m, d = current_date_text.split('/')
endsplit = end.split('/')
file_name = f"{self.data_dir}/{dir_name}/{m}-{d}_{endsplit[1]}-{endsplit[2]}"
table_contents = self.fetch_table_contents(driver, table_header)
if table_contents is not None:
##
if self.page_feed(driver, end, current_date, y,m,d):
##
break
else:
collectors_utils.write_file(file_name, table_header, table_contents)
else:
##
if self.page_feed(driver, end, current_date, y,m,d):
break
else:
pass
driver.get(current_url)
driver.quit()
def main(self):
driver = collectors_utils.set_web_driver(self.base_url)
current_url = driver.current_url
##
self.collect_price(driver, current_url)
fifthCollector.py
# wonderful spam!
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
#
from selenium.webdriver.support.ui import Select
import csv
import time
from datetime import datetime
import os,sys
##
import re
sys.path.append('./scripts')
import collectors_utils
# if you want to use choromedriver_binary
# import chromedriver_binary
# chromedriver_binary.add_chromedriver_to_path()
class FifthCollector():
def __init__(self, url, data_dir):
self.base_url = url
#
self.data_dir = data_dir
##
def close_modal(self, driver):
# try:
# WebDriverWait(driver,6).until(EC.visibility_of_element_located((By.XPATH,'//img[@id="ads-banner-img"]')))
# except:
# driver.find_element_by_xpath('//div[@id="cv-tech-modal-close"]').click()
try:
driver.find_element_by_xpath('//div[@id="cv-tech-modal-close"]').click()
except:
pass
##
def page_feed(self,driver, end_date, current_date, m,d):
##
if m == end_date.split('/')[1] and d == end_date.split('/')[2]:
return True
else:
##
current_button = driver.find_element_by_xpath('//div[@class="lowest_price_list_cell tx-c active selectable"]')
next_button = current_button.find_element_by_xpath('following-sibling::div')
next_button.click()
return False
def fetch_table_header(self, driver):
header_element = driver.find_elements_by_xpath('//div[@class="flight-table-header border-1 border-gray-thin box-bb"]/div')
table_header = [e.text for e in header_element if e.text != '']
return table_header
def fetch_table_contents(self, driver, table_header):
try:
WebDriverWait(driver,6).until(EC.visibility_of_element_located((By.XPATH,'//table[@class="flight-table"]')))
except:
print('empty contents')
time.sleep(3)
# See if it's empty
content_elements = driver.find_elements_by_xpath('//table[@class="flight-table"]/tbody/tr')
if content_elements != []:
table_contents = []
for c in content_elements:
temp_dict = {}
for idx,p in enumerate(c.find_elements_by_xpath('td')):
temp_dict[table_header[idx]] = p.text.replace('\n','->')
if p.text.replace('\n','->') == '':
pass
else:
table_contents.append(temp_dict)
return table_contents
else:
return None
def fetch_select_options(self, element):
select_element = Select(element)
select_options_dic = {option.text:option.get_attribute('value') for option in select_element.options if option.text != '出発地'}
return select_element, select_options_dic
#
def set_dep_date(self, start, dep_date, driver):
start = start.split('/')
# set year
year = driver.find_element_by_xpath('//input[@id="departure_date[y]"]')
driver.execute_script(f'arguments[0].setAttribute("value", "{start[0]}")', year)
# set month
month = driver.find_element_by_xpath('//input[@id="departure_date[m]"]')
driver.execute_script(f'arguments[0].setAttribute("value", "{start[1]}")', month)
# day
day = driver.find_element_by_xpath('//input[@id="departure_date[d]"]')
driver.execute_script(f'arguments[0].setAttribute("value", "{start[2]}")', day)
##
def collect_price(self, driver, current_url):
# Load a file with specified conditions.
rows = collectors_utils.read_file(self.data_dir)
for row in rows:
try:
WebDriverWait(driver,30).until(EC.visibility_of_element_located((By.XPATH,'//select[@class="pl10 departure"]')))
except:
print('element invisible')
driver.quit()
# Enterring the data of the imported file.
dep = row['dep']
des = row['des']
# Departure locations
dep_box = driver.find_element_by_xpath('//select[@class="pl10 departure"]')
dep_box, select_options_dic = self.fetch_select_options(dep_box)
dep_box.select_by_value(select_options_dic[dep])
# Destination locations
des_box = driver.find_element_by_xpath('//select[@class="pl10 arrive"]')
des_box, select_options_dic = self.fetch_select_options(des_box)
des_box.select_by_value(select_options_dic[des])
## dep-date
dep_date = driver.find_element_by_xpath(f'//input[@aria-labelledby="aria-label-departure-date"]')
# set date
start = row['start']
end = row['end']
start_date_check = collectors_utils.check_date(start)
end_date_check = collectors_utils.check_date(end)
if start_date_check:
start = start.replace('/','/')
else:
start = collectors_utils.get_date()[0]
if end_date_check:
end = end.replace('/','/')
else:
end = collectors_utils.get_date()[1]
## enter departure date
#self.set_dep_date(start, dep_date, driver)
search_date = start.replace("/",'/')
driver.execute_script(f'arguments[0].setAttribute("value","{search_date}")', dep_date)
# click search button
driver.find_element_by_xpath('//div[@class="decide-btn btn-grad-orange"]').click()
# fetch table header
table_header = self.fetch_table_header(driver)
date_obj = datetime.now()
dir_date = datetime.strftime(date_obj,'%Y%m%d')
##
dir_name = f'片道-{dep.replace("/","")}-{des.replace("/","")}-{dir_date}'
if os.path.exists(f'{self.data_dir}/{dir_name}'):
pass
else:
os.mkdir(f'{self.data_dir}/{dir_name}')
while True:
current_date = driver.find_element_by_xpath('//div[@class="lowest_price_list_cell tx-c active selectable"]/p[1]')
current_date_text = current_date.text
m, d, _ = current_date_text.replace('(','/').split('/')
endsplit = end.split('/')
file_name = f"{self.data_dir}/{dir_name}/{m}-{d}_{endsplit[1]}-{endsplit[2]}"
table_contents = self.fetch_table_contents(driver, table_header)
if table_contents is not None:
##
if self.page_feed(driver, end, current_date, m,d):
##
break
else:
collectors_utils.write_file(file_name, table_header, table_contents)
else:
##
if self.page_feed(driver, end, current_date, m,d):
break
else:
pass
driver.get(current_url)
driver.quit()
def main(self):
driver = collectors_utils.set_web_driver(self.base_url)
current_url = driver.current_url
##
self.collect_price(driver, current_url)
sixthCollector.py
# wonderful spam!
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
#
from selenium.webdriver.support.ui import Select
import csv
import time
from datetime import datetime
import os,sys
##
import re
sys.path.append('./scripts')
import collectors_utils
# if you want to use choromedriver_binary
# import chromedriver_binary
# chromedriver_binary.add_chromedriver_to_path()
class SixthCollector():
def __init__(self, url, data_dir):
self.base_url = url
#
self.data_dir = data_dir
##
def airticket(self, driver):
try:
WebDriverWait(driver,6).until(EC.visibility_of_element_located((By.XPATH,'//button[@id="tab-flight-tab-hp"]')))
except:
time.sleep(1)
driver.find_element_by_xpath('//button[@id="tab-flight-tab-hp"]').click()
time.sleep(1)
driver.find_element_by_xpath('//label[@id="flight-type-one-way-label-hp-flight"]').click()
time.sleep(1)
driver.find_element_by_xpath('//a[@id="primary-header-flight"]').click()
def close_modal(self, driver):
# try:
# WebDriverWait(driver,6).until(EC.visibility_of_element_located((By.XPATH,'//img[@id="ads-banner-img"]')))
# except:
# driver.find_element_by_xpath('//div[@id="cv-tech-modal-close"]').click()
try:
driver.find_element_by_xpath('//div[@id="cv-tech-modal-close"]').click()
except:
pass
##
def page_feed(self,driver, end_date, current_date, m,d):
##
#driver.back()
if m == end_date.split('/')[1] and d == end_date.split('/')[2]:
return True
else:
##
current_button = driver.find_element_by_xpath('//div[@class="lowest_price_list_cell tx-c active selectable"]')
next_button = current_button.find_element_by_xpath('following-sibling::div')
next_button.click()
return False
def fetch_table_header(self, driver):
header_element = driver.find_elements_by_xpath('//div[@id="flight-listing-container"]')
table_header = [e.text for e in header_element if e.text != '']
return table_header
def fetch_table_contents(self, driver, table_header):
try:
WebDriverWait(driver,6).until(EC.visibility_of_element_located((By.XPATH,'//li[@data-test-id="offer-listing"]')))
except:
print('empty contents')
time.sleep(3)
# See if it's empty
content_elements = driver.find_elements_by_xpath('//li[@data-test-id="offer-listing"]')
if content_elements != []:
table_contents = []
for c in content_elements:
temp_dict = {}
for idx,p in enumerate(c.text.split('\n')):
temp_dict[table_header[idx]] = p
table_contents.append(temp_dict)
return table_contents
else:
return None
def fetch_select_options(self, element):
select_element = Select(element)
select_options_dic = {option.text:option.get_attribute('value') for option in select_element.options if option.text != '出発地'}
return select_element, select_options_dic
#
def set_dep_date(self, start, dep_date, driver):
start = start.split('/')
# set year
year = driver.find_element_by_xpath('//input[@id="departure_date[y]"]')
driver.execute_script(f'arguments[0].setAttribute("value", "{start[0]}")', year)
# set month
month = driver.find_element_by_xpath('//input[@id="departure_date[m]"]')
driver.execute_script(f'arguments[0].setAttribute("value", "{start[1]}")', month)
# day
day = driver.find_element_by_xpath('//input[@id="departure_date[d]"]')
driver.execute_script(f'arguments[0].setAttribute("value", "{start[2]}")', day)
##
def collect_price(self, driver, current_url):
# Load a file with specified conditions.
rows = collectors_utils.read_file(self.data_dir)
for row in rows:
try:
WebDriverWait(driver,30).until(EC.visibility_of_element_located((By.XPATH,'//*[@id="flight-origin-hp-flight"]')))
except:
print('element invisible')
# Enterring the data of the imported file.
dep = row['dep']
des = row['des']
# Departure locations
dep_box = driver.find_element_by_xpath('//*[@id="flight-origin-hp-flight"]')
dep_box.clear()
dep_box.send_keys(dep)
# Destination locations
des_box = driver.find_element_by_xpath('//*[@id="flight-destination-hp-flight"]')
des_box.clear()
des_box.send_keys(des)
## dep-date
dep_date = driver.find_element_by_xpath(f'//input[@id="flight-departing-single-flp"]')
# set date
start = row['start']
end = row['end']
start_date_check = collectors_utils.check_date(start)
end_date_check = collectors_utils.check_date(end)
if start_date_check:
start = start.replace('/','/')
else:
start = collectors_utils.get_date()[0]
if end_date_check:
end = end.replace('/','/')
else:
end = collectors_utils.get_date()[1]
## enter departure date
#self.set_dep_date(start, dep_date, driver)
search_date = start.replace("/",'/')
dep_date.clear()
dep_date.send_keys(search_date)
# click search button
search_btn = driver.find_element_by_xpath('//label[@class="col search-btn-col"]/button')
driver.execute_script('arguments[0].click()', search_btn)
# fetch table header
#table_header = self.fetch_table_header(driver)
table_header = [i+1 for i in range(19)]
date_obj = datetime.now()
dir_date = datetime.strftime(date_obj,'%Y%m%d')
##
dir_name = f'片道-{dep.replace("/","")}-{des.replace("/","")}-{dir_date}'
if os.path.exists(f'{self.data_dir}/{dir_name}'):
pass
else:
os.mkdir(f'{self.data_dir}/{dir_name}')
while True:
current_date = driver.find_element_by_xpath('//div[@class="lowest_price_list_cell tx-c active selectable"]/p[1]')
current_date_text = current_date.text
m, d, _ = current_date_text.replace('(','/').split('/')
endsplit = end.split('/')
file_name = f"{self.data_dir}/{dir_name}/{m}-{d}_{endsplit[1]}-{endsplit[2]}"
table_contents = self.fetch_table_contents(driver, table_header)
if table_contents is not None:
##
if self.page_feed(driver, end, current_date, m,d):
##
break
else:
collectors_utils.write_file(file_name, table_header, table_contents)
else:
##
if self.page_feed(driver, end, current_date, m,d):
break
else:
pass
driver.get(current_url)
driver.quit()
def main(self):
driver = collectors_utils.set_web_driver(self.base_url)
self.airticket(driver)
current_url = driver.current_url
##
self.collect_price(driver, current_url)
説明といっても殆どが既存クラスのコピーで、多少の時刻取得やデータ加工が変わっているのみです。 物凄く簡単に一気に説明しているのは、一応期限が5日と(勝手に決めていたので)あと数時間だからです。
Most of the descriptions are copies of existing classes, with a few changes in time acquisition and data processing. I explain it very simply because the deadline is 5 days and (I decided on my own.) just a few more hours.
後は、crawler.pyに付け足していけば完成です。
Then add it to crawler.py and you're done.
crawler.py
import argparse
import time
import sys
sys.path.append('.')
from collectors.firstCollector import FirstCollector
from collectors.secondCollector import SecondCollector
from collectors.thirdCollector import ThirdCollector
from collectors.fourthCollector import FourthCollector
from collectors.fifthCollector import FifthCollector
from collectors.sixthCollector import SixthCollector
def collectors(num1, num2, num3, num4, num5, num6):
if num1 is not None:
if num1 != 0 and num1 != 1:
print('Please make it 0 or 1 for now.')
sys.exit()
else:
start_time = time.time()
first_collector = FirstCollector('https://woderfulspam.spam', num1, 'data/first_collection')
first_collector.main()
print(f'The first collector completed the collection in {round(time.time() - start_time)} sec')
else:
pass
if num2 is not None:
if num2 != 0 and num2 != 1:
print('Please make it 0 or 1 for now.')
sys.exit()
else:
start_time = time.time()
second_collector = SecondCollector('https://spam.lovelyspam', num2, 'data/second_collection')
second_collector.main()
print(f'The second collector completed the collection in {round(time.time() - start_time)} sec')
else:
pass
if num3 is not None:
if num3 != 0:
print('Please make it 0 for now.')
sys.exit()
else:
start_time = time.time()
third_collector = ThirdCollector('https://egg.spambacon.spam', 'data/third_collection')
third_collector.main()
print(f'The third collector completed the collection in {round(time.time() - start_time)} sec')
else:
pass
if num4 is not None:
if num4 != 0:
print('Please make it 0 for now.')
sys.exit()
else:
start_time = time.time()
fourth_collector = FourthCollector('https://egg.spambacon.spam', 'data/fourth_collection')
fourth_collector.main()
print(f'The fourth collector completed the collection in {round(time.time() - start_time)} sec')
else:
pass
if num5 is not None:
if num5 != 0:
print('Please make it 0 for now.')
sys.exit()
else:
start_time = time.time()
fifth_collector = FifthCollector('https://egg.spambacon.spam', 'data/fifth_collection')
fifth_collector.main()
print(f'The fifth collector completed the collection in {round(time.time() - start_time)} sec')
else:
pass
if num6 is not None:
if num6 != 0:
print('Please make it 0 for now.')
sys.exit()
else:
start_time = time.time()
sixth_collector = SixthCollector('https://egg.spambacon.spam', 'data/sixth_collection')
sixth_collector.main()
print(f'The sixth collector completed the collection in {round(time.time() - start_time)} sec')
else:
pass
def crawler_py():
parser = argparse.ArgumentParser()
first_collector_usage = """
This argument crawls the site for the specified https://woderfulspam.spam.
[-c1, --c1 Number]
Number: Choose between (round trip -> 0) and (one way -> 1).
"""
second_collector_usage = """
This argument crawls the site for the specified https://spam.lovelyspam.
[-c2, --c2 Number]
Number: Choose between (round trip -> 1) and (one way -> 0).
"""
third_collector_usage = """
This argument crawls the site for the specified https://egg.spambacon.spam.
[-c3, --c3 Number]
Number: Specifying 0 causes C3 to scrape
"""
fourth_collector_usage = """
This argument crawls the site for the specified https://egg.spambacon.spam.
[-c4, --c4 Number]
Number: Specifying 0 causes C4 to scrape
"""
fifth_collector_usage = """
This argument crawls the site for the specified https://egg.spambacon.spam.
[-c5, --c5 Number]
Number: Specifying 0 causes C5 to scrape
"""
sixth_collector_usage = """
This argument crawls the site for the specified https://egg.spambacon.spam.
[-c6, --c6 Number]
Number: Specifying 0 causes C6 to scrape
"""
parser.add_argument('-c1','--c1', type=int, help=first_collector_usage)
parser.add_argument('-c2','--c2', type=int, help=second_collector_usage)
parser.add_argument('-c3','--c3', type=int, help=third_collector_usage)
parser.add_argument('-c4','--c4', type=int, help=fourth_collector_usage)
parser.add_argument('-c5','--c5', type=int, help=fifth_collector_usage)
parser.add_argument('-c6','--c6', type=int, help=sixth_collector_usage)
args = parser.parse_args()
collectors(args.c1, args.c2, args.c3, args.c4, args.c5, args.c6)
if __name__=='__main__':
crawler_py()
実食
To check
準備ができたら、crawler.pyを動かす。
When ready, run crawler.py
python crawler.py -c6 0
sixthコレクターのみを動かす。
Activates only the sixthCollector.
settings.csvの中身。
The content of settings.py.
prototype002/data/sixth_collection/settings.csv
dep,des,start,end 札幌,東京,, 東京,札幌,2019/11/21,2019/12/20
取れたデータの中身は以下のようになる。
Here's what the data looks like.
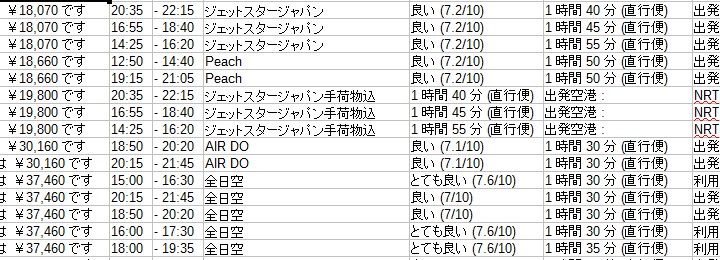
取り敢えず、かろうじて動かせるクローラーとデータは納品できました。 なんにせよ終わらせることが大事なんです。 後はのんびり統合作業をしていきます。
For the time being, we were able to deliver crawlers and data that could barely started. In any case, it's important to finish it. After that, I will do the integration work leisurely.
See You Next Page!