Published Date : 2019年10月20日22:27
架空のクラウドソーシング案件に挑戦してみる(3-4)
Try a Fictional Crowdsourcing Job(3-4)
This blog has an English translation
架空のお仕事をしてみる企画(3-4)です。
It's a project to try a fictitious job(3-4).
仮に自分がフリーランスで、 ある依頼者から適当な仕事を振られてみたら、 果たしてクリアできるのか?といった企画。
If i am a freelance programmer, When a client assigns a suitable job, Can I clear it? That's the plan.
この企画は架空のものですが、日本のクラウドソーシング市場に氾濫しているよくある案件と値段と工数を参考にしてます。
This project is a fictitious one, but it is based on common cases, prices and man-hours flooding the Japanese crowdsourcing market.
取り敢えず前回の続き
For the moment, Let's continue the last time
変更点
Changes
Collector3を作成。それにまた新しい機能を追加し、多少の変更を加えました。
Created Collector3. I've also added new features and made some changes.
ファイル構成は以下の通り
The file structure is as follows
prototype002
collectors
firstCollector.py
secondCollector.py
thirdCollector.py
data
first_collection
settings.csv
second_collection
settings.csv
third_collection
settings.csv
scripts
collectors_utils.py
chromedriver.exe
crowler.py
まずはcrawler.pyの修正点の説明をします。
First, I will explain the modification of crawler.py.
crawler.py
def collectors(num1, num2, num3):
............................................
if num3 is not None:
if num3 != 0:
print('Please make it 0 for now.')
sys.exit()
else:
start_time = time.time()
third_collector = ThirdCollector('https://egg.spambacon.spam', 'data/third_collection')
third_collector.main()
print(f'The third collector completed the collection in {round(time.time() - start_time)} sec')
else:
pass
def crawler_py():
.................................
third_collector_usage = """
This argument crawls the site for the specified egg.spambacon.spam.
[-c3, --c3 Number]
Number: Specifying 0 causes C3 to scrape
"""
このサイトの場合、最初は片道からしか調べられないようなので、引数は一通りにする。 引数が与えられれば、クローラーは起動するが、分かりやすくするために「0」にする。
At this site, you can only search from one way at first, so use a single argument. if an argument is given, the crawler starts, but for clarity, it is set to "0".
thirdCollector.pyの説明
thirdCollector.py description
続いて、thirdCollector.pyの説明をします。
Next, let's look at thirdCollector.py.
thirdCollector.py
import re
正規表現が必要になったのでreモジュールをインポート
Importe re module because I needed a regular expression.
class ThirdCollector():
def __init__(self, url, data_dir):
self.base_url = url
self.data_dir = data_dir
前述の通りself.wayは不要なので取り除く
As mentioned above, self.way is unnecessary, so i decided to removed it.
def page_feed(self,driver, end_date, current_date_text):
##
current_date = re.sub(r'[年月日\(]', ' ', current_date_text).split()
cyear = current_date[0]
cmonth = current_date[1]
cday = current_date[2]
if f'{cyear}/{cmonth}/{cday}' == end_date:
return True
else:
##
c_date = cmonth + cday
lis = driver.find_elements_by_xpath('//div[@id="weekly_data"]/ul/li')
for idx, li in enumerate(lis):
if c_date == li.text.split('(')[0].replace('/',''):
next_page = lis[idx + 1]
next_page.click()
break
return False
ページ送りの判定基準の為、今表示されているページの年月日を取得する。 その際に、不要な文字を正規表現を使って消し去る!ニフラム!
I need it to send the page, so I get the date of the page that is displayed now. I used regular expressions to remove unwanted characters.
def set_dep_date(self, start, dep_date, driver):
start = start.split('/')
dep_date.click()
# set year
datepicker_year = driver.find_element_by_xpath('//select[@class="ui-datepicker-year"]')
datepicker_year_select = Select(datepicker_year)
datepicker_year_select.select_by_value(start[0])
# set month
month_n = driver.find_element_by_xpath('//span[@class="ui-datepicker-month"]')
driver.execute_script(f"arguments[0].innerHTML = '{start[1]}月'", month_n)
# day
select_days = driver.find_elements_by_xpath('//td[@data-handler="selectDay"]')
for sd in select_days:
if ''.join(start) in sd.get_attribute('class'):
sd.click()
break
日付データを直接テキストとして貼り付けられない仕様になっているので、Selectタグとtableタグを直接操作する。
I can't paste date data directory as text, so i can directory manipulate the select and table tags.
変更箇所はこれぐらいDESU。もちろんXpathもNE。
That's all for the explanation fo the changes. (Xpath is, of course, different.)
実食
To check
準備ができたら、crawler.pyを動かす。
When ready, run crawler.py
python crawler.py -c3 0
サードコレクターのみを動かす。
Activates only the thirdCollector.
settings.csvの中身は前回と同じ。
The content of settings.py is the same as last time.
prototype002/data/second_collection/settings.csv
dep,des,start,end 新千歳,羽田,, 羽田,新千歳,2019/11/21,2019/12/20
取れたデータの中身は以下のようになる。
Here's what the data looks like.
prototype002/data/third_collection/片道-札幌新千歳-東京羽田-20191020/11-1_11-20.csv
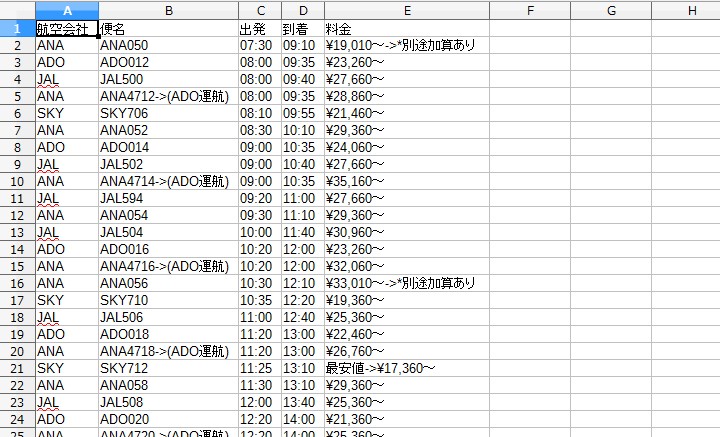
しかし、なかなか進まないですね。本業とその他のことをやりながらだと時間が大分限られてきます。 まっ、遊びだからいんだけどNE。
But it's not going well. After all, my time is very limited if i do my main business and other things. Well, I'm just programming for fun, so that's fine.
See You Next Page!