Published Date : 2019年10月18日21:21
架空のクラウドソーシング案件に挑戦してみる(3-3)
Try a Fictional Crowdsourcing Deal(3-3)
This blog has an English translation
架空のお仕事をしてみる企画(3-3)です。
It's a project to try a fictitious job(3-3).
仮に自分がフリーランスで、 ある依頼者から適当な仕事を振られてみたら、 果たしてクリアできるのか?といった企画。
If i am a freelance programmer, When a client assigns a suitable job, Can I clear it? That's the plan.
この企画は架空のものですが、日本のクラウドソーシング市場に氾濫しているよくある案件と値段と工数を参考にしてます。
This project is a fictitious one, but it is based on common cases, prices and man-hours flooding the Japanese crowdsourcing market.
取り敢えず前回の続き
For the moment, Let's continue the last time
変更点
Changes
もう一つのサイト用のクラスファイルを作成。
2つ動かすため、crawler.pyの修正。
Create class file for another site.
Modified crawler.py to run two Collectors.
ファイル構成は以下の通り
The file structure is as follows
prototype002
collectors
firstCollector.py
secondCollector.py
data
first_collection
settings.csv
second_collection
settings.csv
scripts
collectors_utils.py
chromedriver.exe
crowler.py
まずはcrawler.pyの修正点の説明をします。
First, I will explain the modification of crawler.py.
crawler.py
import argparse
import time
import sys
sys.path.append('.')
from collectors.firstCollector import FirstCollector
from collectors.secondCollector import SecondCollector
def collectors(num1, num2):
if num1 is not None:
if num1 != 0 and num1 != 1:
print('Please make it 0 or 1 for now.')
sys.exit()
else:
start_time = time.time()
first_collector = FirstCollector('https://woderfulspam.spam', num1, 'data/first_collection')
first_collector.main()
print(f'The first collector completed the collection in {round(time.time() - start_time)} sec')
else:
pass
if num2 is not None:
if num2 != 0 and num2 != 1:
print('Please make it 0 or 1 for now.')
sys.exit()
else:
start_time = time.time()
second_collector = SecondCollector('https://spam.lovelyspam', num2, 'data/second_collection')
second_collector.main()
print(f'The second collector completed the collection in {round(time.time() - start_time)} sec')
else:
pass
def crawler_py():
parser = argparse.ArgumentParser()
first_collector_usage = """
This argument crawls the site for the specified https://woderfulspam.spam.
[-c1, --c1 Number]
Number: Choose between (round trip -> 0) and (one way -> 1).
"""
second_collector_usage = """
This argument crawls the site for the specified https://spam.lovelyspam.
[-c2, --c2 Number]
Number: Choose between (round trip -> 1) and (one way -> 0).
"""
parser.add_argument('-c1','--c1', type=int, help=first_collector_usage)
parser.add_argument('-c2','--c2', type=int, help=second_collector_usage)
args = parser.parse_args()
collectors(args.c1, args.c2)
if __name__=='__main__':
crawler_py()
先にURLと保存先を指定して、オプション引数(数値)によって起動させる。 後に(するか分からないが)バッシュスクリプトやバッチファイルで動かす際に便利かなと思い作成。
First specify the URL and save location, then invoke with the optional argument(Number). I created this as i thought it would be useful to run a bash script or batch file later. (I don't know if I will.)
collectors関数では同じような処理で行数が増えてしまっているが、 とりあえずの試作品でっす。ご勘弁を。
The collectors function does the same thing, increasing the number of rows, but It's just a prototype. Sorry about this.
secondCollector.pyの説明
secondCollector.py description
続いて、secondCollector.pyの説明をします。
Next, let's look at secondCollector.py.
secondCollector.py
# wonderful spam!
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
#
from selenium.webdriver.support.ui import Select
import csv
import time
from datetime import datetime
import os,sys
sys.path.append('./scripts')
import collectors_utils
# if you want to use choromedriver_binary
# import chromedriver_binary
# chromedriver_binary.add_chromedriver_to_path()
class SecondCollector():
def __init__(self, url, way, data_dir):
self.base_url = url
self.way = way
self.data_dir = data_dir
def switch_ways(self, driver, way_num):
"""
way_num:0 = oneway
way_num:1 = roundtrip
ways = driver.find_elements_by_xpath('//ul[@class="clearfix"]/li')
"""
try:
WebDriverWait(driver,3).until(EC.visibility_of_element_located((By.XPATH,'//input[@id="oneway"]')))
except:
print('element invisible')
if way_num == 0:
way = driver.find_element_by_xpath('//input[@id="oneway"]')
elif way_num == 1:
way = driver.find_element_by_xpath('//input[@id="roundtrip"]')
else:
print('element click intercepted')
driver.quit()
driver.execute_script("arguments[0].click()", way)
def page_feed(self, driver, cdate, end_date):
try:
WebDriverWait(driver,9).until(EC.element_to_be_clickable((By.XPATH,'//button[@class="btn_weekly"]')))
except:
print('element click intercepted')
current_btn = driver.find_element_by_xpath('//button[@class="btn_weekly today"]')
cyear, cmonth, cday = cdate.split('(')[0].split('/')
if f'{cyear}/{cmonth}/{cday}' == end_date:
return True
else:
parent_li = current_btn.find_element_by_xpath('..')
sibl_li = parent_li.find_element_by_xpath('following-sibling::li')
sibl_li.find_element_by_xpath('button[@class="btn_weekly"]').click()
return False
def fetch_table_header(self, driver):
header_element = driver.find_elements_by_xpath('//tr[@id="search_head_new"]/th')
table_header = [e.text for e in header_element if e.text != '']
return table_header
def fetch_table_contents(self, driver, table_header):
try:
WebDriverWait(driver,6).until(EC.visibility_of_element_located((By.XPATH,'//div[@id="fare_list_new"]/table[@id="fare_result_list_new"]')))
except:
print('empty contents')
# See if it's empty
content_elements = driver.find_elements_by_xpath('//div[@id="fare_list_new"]/table[@id="fare_result_list_new"]/tbody')
if content_elements != []:
table_contents = [{table_header[idx]:td.text.replace('\n','->') for idx,td in enumerate(c.find_elements_by_tag_name('td'))} for c in content_elements]
return table_contents
else:
return None
def fetch_select_options(self, element):
select_element = Select(element)
select_options_dic = {option.text:option.get_attribute('value') for option in select_element.options if option.text != '出発地'}
return select_element, select_options_dic
def collect_price(self, driver, current_url, way_num):
# Load a file with specified conditions.
rows = collectors_utils.read_file(self.data_dir)
for row in rows:
try:
WebDriverWait(driver,30).until(EC.visibility_of_element_located((By.XPATH,'//select[@id="departure_airport"]')))
except:
print('element invisible')
driver.quit()
# Enterring the data of the imported file.
dep_box = driver.find_element_by_xpath('//select[@id="departure_airport"]')
replace_btn = driver.find_element_by_xpath('//button[@id="set_reverse"]')
des_box = driver.find_element_by_xpath('//select[@id="arrival_airport"]')
dep = row['dep']
des = row['des']
# Departure locations
dep_box, select_options_dic = self.fetch_select_options(dep_box)
dep_box.select_by_value(select_options_dic[dep])
# Destination locations
des_box, select_options_dic = self.fetch_select_options(des_box)
des_box.select_by_value(select_options_dic[des])
if way_num == 0:
# dep-date
dep_date = driver.find_element_by_xpath(f'//div[@class="search__ctrl__date"]/div[@id="date"]/input[@id="js-DP"]')
else:
# dep-date
dep_date = driver.find_element_by_xpath(f'//div[@class="search__ctrl__date"]/div[@id="date"]/input[@id="js-DP"]')
# des-date
des_date = driver.find_element_by_xpath(f'//div[@class="search__ctrl__date__arrival"]/div[@id="date2"]/input[@id="js-DP2"]')
# set date
start = row['start']
end = row['end']
start_date_check = collectors_utils.check_date(start)
end_date_check = collectors_utils.check_date(end)
if start_date_check:
start = start.replace('/','/')
else:
start = collectors_utils.get_date()[0]
if end_date_check:
end = end.replace('/','/')
else:
end = collectors_utils.get_date()[1]
if way_num == 0:
# enter departure date
driver.execute_script(f"arguments[0].value = '{start.replace('/','/')}'", dep_date)
else:
# enter departure date
driver.execute_script(f"arguments[0].value = '{start.replace('/','/')}'", dep_date)
# enter destination date
driver.execute_script(f"arguments[0].value = '{end.replace('/','/')}'", des_date)
# click search button
driver.find_element_by_xpath('//button[@id="js-btnSearchTicket"]').click()
# fetch table header
table_header = self.fetch_table_header(driver)
date_obj = datetime.now()
dir_date = datetime.strftime(date_obj,'%Y%m%d')
if way_num == 0:
dir_name = f'片道-{dep}-{des}-{dir_date}'
else:
dir_name = f'往復-{dep}-{des}-{dir_date}'
if os.path.exists(f'{self.data_dir}/{dir_name}'):
pass
else:
os.mkdir(f'{self.data_dir}/{dir_name}')
while True:
try:
WebDriverWait(driver,3).until(EC.visibility_of_element_located((By.XPATH,'//p[@class="date"]')))
except:
print('element invisible')
current_date_text = driver.find_element_by_xpath('//p[@class="date"]').text
current_date = current_date_text.replace('\u3000|\u3000','-').replace(' - ','-').replace(' (','(').replace('/','-')
current_date = f"{current_date.split('-')[1]}-{current_date.split('-')[2]}"
if way_num == 0:
file_name = f'{self.data_dir}/{dir_name}/{current_date}'
else:
endsplit = end.split('/')
file_name = f"{self.data_dir}/{dir_name}/{current_date}_{endsplit[1]}-{endsplit[2]}"
table_contents = self.fetch_table_contents(driver, table_header)
if table_contents is not None:
if self.page_feed(driver, current_date_text, end):
if way_num == 1:
endsplit = end.split('/')
last_day = int(endsplit[-1]) + 1
end = f'{endsplit[1]}-{last_day}'
file_name = f"{self.data_dir}/{dir_name}/{current_date}_{end}"
collectors_utils.write_file(file_name, table_header, table_contents)
break
else:
collectors_utils.write_file(file_name, table_header, table_contents)
else:
if self.page_feed(driver, current_date_text, end):
break
else:
pass
driver.get(current_url)
driver.quit()
def main(self):
driver = collectors_utils.set_web_driver(self.base_url)
way_num = int(self.way)
self.switch_ways(driver, way_num)
current_url = driver.current_url
self.collect_price(driver, current_url, way_num)
from selenium.webdriver.support.ui import Select
SelectメソッドはSelectタグをSeleniumで扱えるようにしてくれる便利なあんちくしょーなやつです。 今回はSelectタグから直接Optionリストを操作しないと行き先等が打ち込めないサイトでした。
The Select method is a handy way to handle Select tags in Selenium. This time, it was a site where you could not specify the destination etc. without operating the Option list directly from the Select tag.
こんな感じで使用します。
Use it like this.
def fetch_select_options(self, element):
select_element = Select(element)
select_options_dic = {option.text:option.get_attribute('value') for option in select_element.options if option.text != '出発地'}
return select_element, select_options_dic
# Departure locations
dep_box, select_options_dic = self.fetch_select_options(dep_box)
dep_box.select_by_value(select_options_dic[dep])
空港名がキーで、番号がバリューの辞書を作成します。 settings.pyには空港名で指定されるからです。 ただ、後に存在しない空港名を除外、またはルールベースで推論するように 修正しないといけません。
Create a dictionary with the airport name as key and the number as value. This is because settings.py is specified by the airport name. However, we have to exclude the names of airports that do not exist later or modify them to infer them based on rules.
# Departure locations
dep_box, select_options_dic = self.fetch_select_options(dep_box)
dep_box.select_by_value(select_options_dic[dep])
その他、細かい修正が入ってます。 WebDriverWait()の種類の変更。 「/」をエスケープする必要が無くなる。 勿論、Xpathも変わってます。
There are other minor corrections. Changing the WebDriverWait() type. There is no need to escape the "/". Of coursem, the Xpath has also changed.
ただ、基本的にはfirstCollectorと同じなので、さっさと合成もしくは継承させたいです。 そして、Xpathは外部から変更可能にしたいところです。 ですが、そんなにコード量が大きくないので、 取り敢えず残り4つのサイトの挙動を確かめた後に作ったほうが楽そうです。
However, it is basically the same as firstCollector, so I want to merge or inherit it quickly. And I want Xpath to be externally modifiable. However, the amount of code is not so large. It seems to be easier to make it after checking the behavior of the remaing 4 sites.
その他、細かい修正が入ってます。 WebDriverWait()の種類の変更。 「/」をエスケープする必要が無くなる。 勿論、Xpathも変わってます。
There are other minor corrections. Changing the WebDriverWait() type. There is no need to escape the "/". Of coursem, the Xpath has also changed.
実食
To check
準備ができたら、crawler.pyを動かす。
When ready, run crawler.py
python crawler.py -c2 0
セカンドコレクターのみ動かし、片道(0)を指定。
Activates only the secondCollector and specifies oneway(0).
settings.csvの中身は前回と同じ。
The content of settings.py is the same as last time.
prototype002/data/second_collection/settings.csv
dep,des,start,end 新千歳,羽田,, 羽田,新千歳,2019/11/21,2019/12/20
取れたデータの中身は以下のようになる。
Here's what the data looks like.
prototype002/data/second_collection/片道-東京(羽田)(HND)-札幌(新千歳)(CTS)-20191018/12-19(木).csv

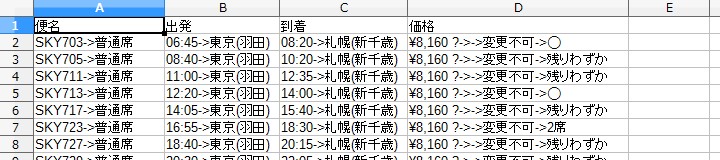
気付いていると思いますが、往復便の航空チケット料金が片道しか取れてません。 実は行きの便をクリックしないと帰りの便の時間と料金が表示されないのです。 つまりもし片道10件あったら、10回ずつクリックして、10回ずつスクレイピングして、10回ずつバックしなければなりません。
You may have noticed, but we only have data on round-trip air tickets for one way. Actually, the time and fare of the return flight are not displayed unless I click the flight to go. So if you had 10 oneway trips, you'd have to click 10 times, scrape 10 times, and go back 10 times.
何が言いたいかというと、実装は簡単ですが、クロールの時間がかかります。 取り敢えず他のサイトも終わらせたあとに色々考えることにします。 おやすみ。
What I mean is that it's easy to implement, but it takes time to crawl. For now, I will think about other sites after I finish them. Good night.
See You Next Page!