Published Date : 2019年10月13日18:35
架空のクラウドソーシング案件に挑戦してみる(2)
Try a Fictional Crowdsourcing Deal(2)
This blog has an English translation
架空のお仕事をしてみる企画(2)です。
It's a project to try a fictitious job(2).
仮に自分がフリーランスで、 ある依頼者から適当な仕事を振られてみたら、 果たしてクリアできるのか?といった企画。
If i am a freelance programmer, When a client assigns a suitable job, Can I clear it? That's the plan.
この企画は架空のものですが、日本のクラウドソーシング市場に氾濫しているよくある案件と値段と工数を参考にしてます。
This project is a fictitious one, but it is based on common cases, prices and man-hours flooding the Japanese crowdsourcing market.
依頼者からの要望
Request from the client
仕事の依頼内容は、Python,Seleniumを使った「WEAR」の自動で「いいね」を押すツールの開発のお仕事です。
My job assignment is develop a tool that automatically presses "Like" button in "WEAR" using Python, Selenium.
Requierments
1 |
「WEAR」のサイトで指定したハッシュタグに対して「いいね」をするツールを開発してくだちぃ。 You should develop a tool to "Like" the hashtag specified on the "WEAR" site. |
|---|---|
2 |
支払い金額は1000円です。 The payment amount is 1000 yen.($10) |
3 |
期間は1日以内です。 The duration is within one day. |
4 |
納品物はソースコードです。 Deliverables are source code. |
ツール制作開始。
Start tool production
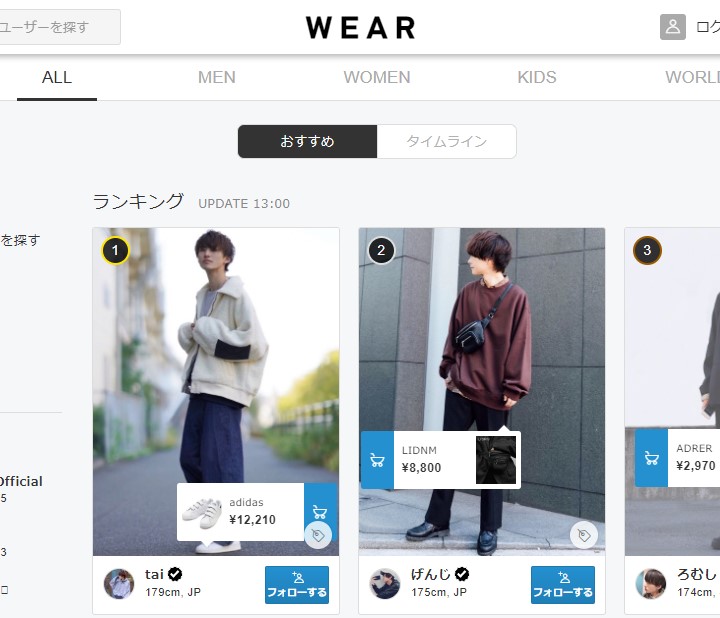
さて、適当なハッシュタグに飛んで、いいねをしてみましょう。
Now, go to appropriate hashtag and try press "like" button.
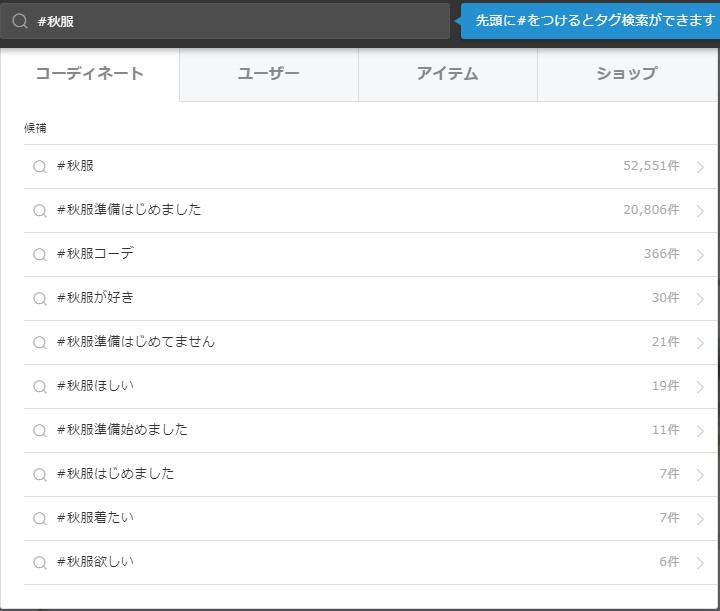
秋服で検索してみました。とりあえず一番件数がありそうなタグをクリック。
I searched by autumn clothes. For now, click on the most likely number of tags.
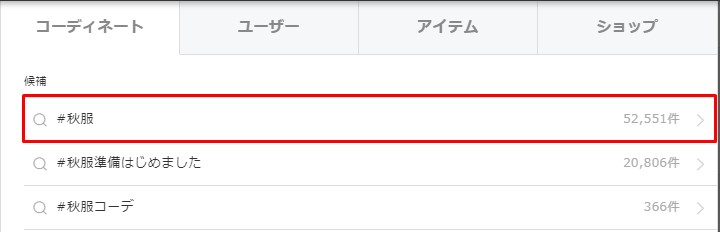
表示されているページのいいねを押していきます。
Press "like" on the displayed pages.
その前に、恐らく想像ですが、実際の案件だとこんな単純なタグのキワード指定ではないと思われます。
Before that, I guess it's not a simple tag keyword specification in a real case.
何故なら、依頼主は恐らく「自分に利益があるよう」に「いいね」を押させたいはずです。
Because the client probably wants "I feel that I have a profit." to press "like".
そうすると、「いいね」の対象は「少数」(依頼主が推したい限られた人か服)になるはずです。
The "like" target should then be "minority" (a limited number of people or clothing that a client wants to recommend).
なので、キーワード検索の時点で「1人から3人」になるような「一つの珍しいタグ」また「複数のタグの組み合わせ」にしたいと思います。
Therefore, I would like to make it "One unique tag" or "Multiple tag combinations" so that it becomes "one to three people" at the time of keyword search.
とりあえずまた適当にキーワードを入力する。
For now, I'll just type in a few more keywords.
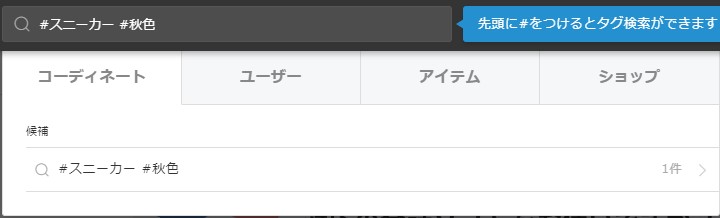
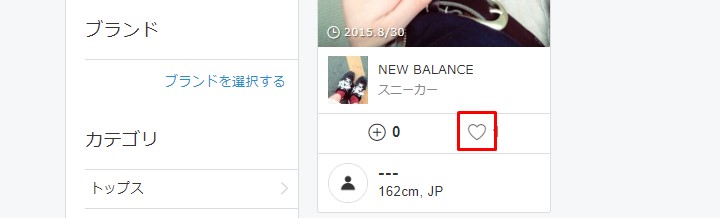
一件です。ページを表示させていいねを押しましょう。
Just one. Let's display the page and press the Like button.
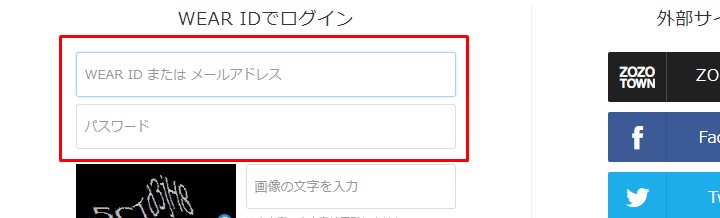
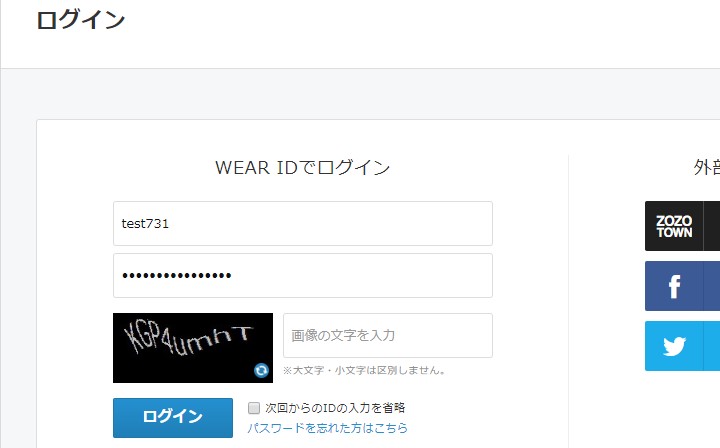
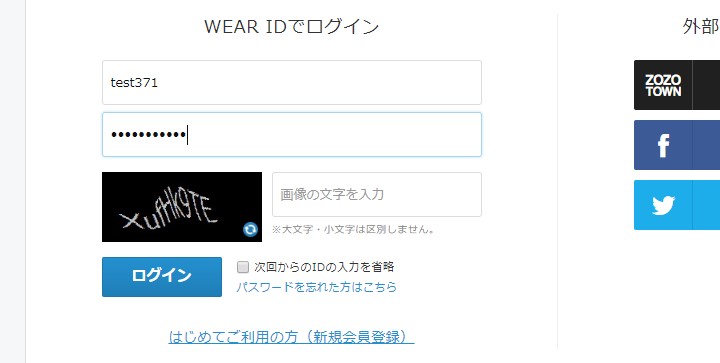
ログイン画面です。ログインしなければ「いいね」は押せないようです。 ということは依頼主にIDとパスワードを入力させるような、入力待ちの処理を入れないといけないですね。
The login page. If you don't login, you can't press "like". That means I have to put in a process wating for the client to input the ID and password.

とりあえず自分のIDでログインして、いいねを押してみます。
Anyway, I will login with my ID and press the "like" button.
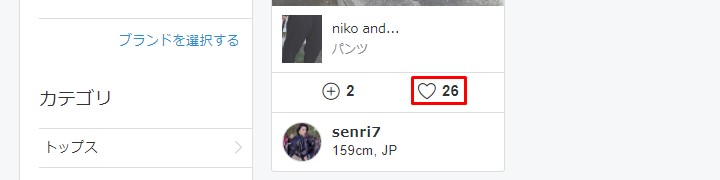
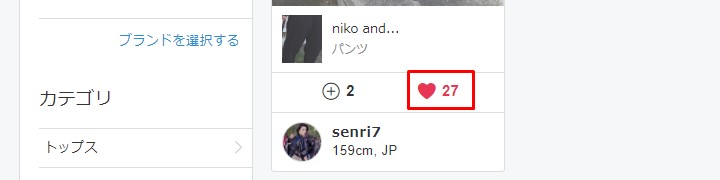
普通に押せたので、自動化スクリプトを作成します。
Now that i have pressed it normally, create an automation script.
フォルダの構成はこちら。
The contents of the folder are like this.
directory
data
taglist.csv # tag list table
py37 # virtual environment
press_like.py
requirements.txt
全コードはこちら
Hear is the full code.
press_like.py
from selenium.webdriver import Chrome,ChromeOptions
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import csv
from getpass import getpass
import time
# if you want to use choromedriver_binary
# import chromedriver_binary
# chromedriver_binary.add_chromedriver_to_path()
def set_web_driver():
options = ChromeOptions()
driver_path = "chromedriver.exe"
# 下をコメントアウトすると、ヘッドレスモードで検証できます。
# You can verify in headless mode by commenting out below.
# options.add_argument('--headless')
options.add_argument('--incognito')
# If you are using chromedriver _ binary
# driver = Chrome(options=options)
driver = Chrome(driver_path, options=options)
base_url = 'https://wear.jp/'
driver.get(base_url)
return driver
def login_wear(driver):
driver.find_element_by_xpath('//p[@class="login"]/a').click()
while True:
driver.find_element_by_xpath('//input[@id="input_wearid"]').clear()
driver.find_element_by_xpath('//input[@id="input_wearid"]').send_keys(input('enter your id: '))
driver.find_element_by_xpath('//input[@type="password"]').clear()
driver.find_element_by_xpath('//input[@type="password"]').send_keys(getpass('enter your password: '))
driver.find_element_by_xpath('//input[@class="captcha_text"]').clear()
driver.find_element_by_xpath('//input[@class="captcha_text"]').send_keys(input('enter captcha: '))
driver.find_element_by_xpath('//input[@value="ログイン"]').click()
try:
WebDriverWait(driver,6).until(EC.presence_of_element_located((By.XPATH, '//a[@href="/member/"]')))
break
except:
print('Error. The ID, password or Captch is different. Please try again.')
def read_tags():
with open('data/taglist.csv') as f:
reader = csv.reader(f)
tags=[[tag for tag in row] for row in reader]
return tags
def set_taglist(tags):
taglist = []
if len(tags) >= 1:
for ts in tags:
row = ''
for tag in ts:
row += tag + ','
taglist.append(row)
return taglist
else:
print('Missing tag words.')
return False
def search_contents(driver, tagwords):
searchwindow = '//form[@id="gSearch_form"]/p/span/input'
try:
WebDriverWait(driver,10).until(EC.presence_of_element_located((By.XPATH,searchwindow)))
except:
time.sleep(1)
driver.find_element_by_xpath(searchwindow).clear()
driver.find_element_by_xpath(searchwindow).send_keys(tagwords)
driver.find_element_by_xpath(searchwindow).send_keys(Keys.ENTER)
def pagenation(driver):
try:
driver.find_element_by_xpath('//p[@class="next"]/a').click()
except:
print('This tool Pressed "Like" on every page.')
def press_like(driver):
try:
WebDriverWait(driver,10).until(EC.presence_of_element_located((By.XPATH,'//ul[@class="list img_after_load clearfix"]/li[@class="like_mark"]')))
except:
time.sleep(3)
contents = driver.find_elements_by_xpath('//ul[@class="list img_after_load clearfix"]/li[@class="like_mark"]')
for content in contents:
content.find_element_by_xpath('div[@class="meta clearfix"]/ul/li[@class="like icon_font"]/div/p/a').click()
time.sleep(1)
def main():
driver = set_web_driver()
login_wear(driver)
taglist = set_taglist(read_tags())
if taglist == False:
driver.quit()
else:
for tagwords in taglist:
search_contents(driver, tagwords)
press_like(driver)
pagenation(driver)
driver.quit()
if __name__=='__main__':
main()
まず、こちらの環境と相手の環境を合わせてやる必要がでてきます。仮想環境を用意してあげましょう。Python3標準装備のVenvを使います。
First, we need to match your environment with your client. Set up a virtual environment. Python3 has a built-in virtual environment, Venv.
mkdir directory
cd directory
mkdir data
python -m venv py37
Seleniumをインポート
Import Selenium.
pip install selenium
さて、ブラウザを実際に操作するためにドライバーが必要です。 今回はChromeを使います。 ChromeDriverをここからダウンロードするか(推奨)、
Now, you need a driver to actually operate the browser. I use Chrome this time. Download the ChromeDriver from here (recommended) or
バイナリーデータを直接pipでインストールするかしてください。 ただし、使っているブラウザとヴァージョンが違うとエラーになるので、 ChromeDriverをヴァージョンごとに直接ダウンロードしたほうが無難です。
Install the binary data directly with pip. However, if the version is different from the browser you are using, an error occurs. It's better to download ChromeDriver directly for each version.
pip install chrome-driver
ではスクリプトの説明。
describes the script.
def login_wear(driver):
driver.find_element_by_xpath('//p[@class="login"]/a').click()
while True:
driver.find_element_by_xpath('//input[@id="input_wearid"]').clear()
driver.find_element_by_xpath('//input[@id="input_wearid"]').send_keys(input('enter your id: '))
driver.find_element_by_xpath('//input[@type="password"]').clear()
driver.find_element_by_xpath('//input[@type="password"]').send_keys(getpass('enter your password: '))
driver.find_element_by_xpath('//input[@class="captcha_text"]').clear()
driver.find_element_by_xpath('//input[@class="captcha_text"]').send_keys(input('enter captcha: '))
driver.find_element_by_xpath('//input[@value="ログイン"]').click()
try:
WebDriverWait(driver,6).until(EC.presence_of_element_located((By.XPATH, '//a[@href="/member/"]')))
break
except:
print('Error. The ID, password or Captch is different. Please try again.')
使う人のIDなどを入力させて、ログインさせます。 間違えやすいCaptch入力ミスなどが起こった場合、Whileループでループさせる。
Login to WEAR. If there is a capch input error that is easy to make a mistake, use the While loop to re-input.
def read_tags():
with open('data/taglist.csv') as f:
reader = csv.reader(f)
tags=[[tag for tag in row] for row in reader]
return tags
def set_taglist(tags):
taglist = []
if len(tags) >= 1:
for ts in tags:
row = ''
for tag in ts:
row += tag + ','
taglist.append(row)
return taglist
else:
print('Missing tag words.')
return False
リスト化して指定されたキーワードを検索しやすいようにする。
Make it easier to search for specified keywords by listing them.

def search_contents(driver, tagwords):
searchwindow = '//form[@id="gSearch_form"]/p/span/input'
try:
WebDriverWait(driver,10).until(EC.presence_of_element_located((By.XPATH,searchwindow)))
except:
time.sleep(1)
driver.find_element_by_xpath(searchwindow).clear()
driver.find_element_by_xpath(searchwindow).send_keys(tagwords)
driver.find_element_by_xpath(searchwindow).send_keys(Keys.ENTER)
検索窓にキーワードを打ち込み検索をかける。
Type keywords into the search window and search.
def pagenation(driver):
try:
driver.find_element_by_xpath('//p[@class="next"]/a').click()
except:
print('This tool Pressed "Like" on every page.')
def press_like(driver):
try:
WebDriverWait(driver,10).until(EC.presence_of_element_located((By.XPATH,'//ul[@class="list img_after_load clearfix"]/li[@class="like_mark"]')))
except:
time.sleep(3)
contents = driver.find_elements_by_xpath('//ul[@class="list img_after_load clearfix"]/li[@class="like_mark"]')
for content in contents:
content.find_element_by_xpath('div[@class="meta clearfix"]/ul/li[@class="like icon_font"]/div/p/a').click()
time.sleep(1)
もし複数のページが存在するならページ送りをする。
そして”いいね”を押す関数を用意する。
If there are multiple pages, page feed is performed.
Then, prepare a function to press "like".
def main():
driver = set_web_driver()
login_wear(driver)
taglist = set_taglist(read_tags())
if taglist == False:
driver.quit()
else:
for tagwords in taglist:
search_contents(driver, tagwords)
press_like(driver)
pagenation(driver)
driver.quit()
if __name__=='__main__':
main()
全ての処理をMAIN関数としてまとめる。
All processing is combined as a main function.


以上です。
That's all.
See You Next Page!