Published Date : 2019年10月11日18:07
架空のクラウドソーシング案件に挑戦してみる
Try a Fictional Crowdsourcing Deal
This blog has an English translation
架空のお仕事をしてみる企画です。
It's a project to try a fictitious job.
仮に自分がフリーランスで、 ある依頼者から適当な仕事を振られてみたら、 果たしてクリアできるのか?といった企画。
If i am a freelance programmer, When a client assigns a suitable job, Can I clear it? That's the plan.
この企画は架空のものですが、日本のクラウドソーシング市場に氾濫しているよくある案件と値段と工数を参考にしてます。
This project is a fictitious one, but it is based on common cases, prices and man-hours flooding the Japanese crowdsourcing market.
依頼者からの要望
Request from the client
仕事の依頼内容はPythonを使ったWebページスクレイピング&CSVファイルへの出力です。
Your job request is to scrape a web page using Python and output it to a CSV file.
Requierments
1 |
以下のURLからTAISコードをすべて取得して、CSVファイルに出力するプログラムを作って下さい。 Please make a program to get all TAIS codes from the following URL and output to CSV file. |
|---|---|
2 |
支払い金額は2000円です。 The payment amount is 2000 yen.($20) |
3 |
期間は1日以内です。 The duration is within one day. |
4 |
納品物はソースコードとCSVファイルです。 Deliverables are source code and CSV file. |
スクレイピング開始。
Scraping is started.
今回の詳しいURLはプライバシー保護の為隠します。
I will hide the detailed URL this time for privacy protection.
架空の案件ではありますが、たった2000円で請け負った人に幸あれ!
It's a fictitious project, but please bring good luck to the person who undertook it for only 2000 yen!
さて、指定されたURLに飛んで、目的のTAISコードとやらを確認してみましょう。
Now, go to the specified URL and see what TAIS code you want.
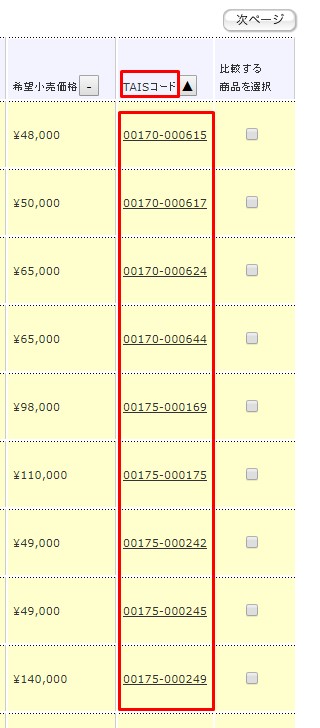
TAISコードは見つかったので、目的の値のHTMLソースを調べます。
Now that the TAIS code has been found, check the HTML source for the desired values.
<td class="classCode"><a href=".php?RowNo=1&Code1=00&Code2=000111" title="詳細" id="Detail">00170-000615</a></td>
どうやらaタグの文字みたいです。
It seems to be a letter of anchor tag.
もうスクリプトは作れそうなので、後はページ送りをした時の挙動を確かめます。
I think I can write a script now, so I will check the behavior when I page forward.
「次へ」ボタンを押せばページ送りです。
I think I can write a script now, so I will check the behavior when I page forward.

「前へ」ボタンが現れたということは、最後のページに行けば「次へ」ボタンは消える。 つまり「次へ」ボタンが消えた時が最後のページです。
I think I can write a script now, so I will check the behavior when I page forward.

しかし、URLは変化がありません。ここは無難にSeleniumを使う事にします。
However, the URL remains the same. I will safely use Selenium here.
フォルダの構成はこちら。
The contents of the folder are like this.
directory
data
TAIS_codes.csv # result output data
py37 # virtual environment
selenium_spider.py
requirements.txt
まず、こちらの環境と相手の環境を合わせてやる必要がでてきます。仮想環境を用意してあげましょう。Python3標準装備のVenvを使います。
First, we need to match your environment with your client. Set up a virtual environment. Python3 has a built-in virtual environment, Venv.
mkdir directory
cd directory
mkdir data
python -m venv py37
Seleniumをインポート
Import Selenium.
pip install selenium
さて、ブラウザを実際に操作するためにドライバーが必要です。 今回はChromeを使います。 ChromeDriverをここからダウンロードするか(推奨)、
Now, you need a driver to actually operate the browser. I use Chrome this time. Download the ChromeDriver from here (recommended) or
バイナリーデータを直接pipでインストールするかしてください。 ただし、使っているブラウザとヴァージョンが違うとエラーになるので、 ChromeDriverをヴァージョンごとに直接ダウンロードしたほうが無難です。
Install the binary data directly with pip. However, if the version is different from the browser you are using, an error occurs. It's better to download ChromeDriver directly for each version.
pip install chrome-driver
では本体のスクリプトを書きます。
Now I'll write a script for the main.
selenium_spider.py
"""
### Usage ###
python -m venv py37
# activate for mac
source py37/bin/activate
# windows
py37\Scripts\activate.bat
pip install -r requirements.txt
# If you want to install the ChromeDriver directly from pip.
pip install chromedriver-binary
# down load chrome driver
# ダウンロードを選んだ場合は作業用ダイレクトリにChromeDriverを直接置いてください。
# If you choose to download, place the ChromeDriver directly in the working directory.
https://chromedriver.chromium.org/downloads
######################
your working directory
data
csv file
py37 # virtual env
chromedriver binary file
selenium_spider.py
requirements.txt
######################
# run script
python selenium_spider.py
# deactivate venv
# mac
deactivate
# windows
py37\Scripts\deactivate.bat
もしドライバーのバージョンが違うと警告されたら。
If you are warned that the driver version is different.
指定されたバージョンのChromeDriverをダウンロードし直してください。
Please re-download the specified version of ChromeDriver.
This version of ChromeDriver only supports Chrome version 75
https://chromedriver.chromium.org/downloads
"""
from selenium.webdriver import Chrome,ChromeOptions
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import csv
# if you want to use choromedriver_binary
# import chromedriver_binary
# chromedriver_binary.add_chromedriver_to_path()
def set_web_driver():
options = ChromeOptions()
driver_path = "chromedriver.exe"
# 下をコメントアウトすると、ヘッドレスモードで検証できます。
# You can verify in headless mode by commenting out below.
# options.add_argument('--headless')
options.add_argument('--incognito')
# If you are using chromedriver _ binary
# driver = Chrome(options=options)
driver = Chrome(driver_path, options=options)
base_url = 'http://www.spamhamspamspameggbaconspamspam.php'
driver.get(base_url)
return driver
def search_product(driver):
driver.find_element_by_xpath('//input[@id="spam"]').send_keys(1)
driver.find_element_by_xpath('//div[@class="spam search"]/input').click()
def pagenation(driver):
try:
driver.find_element_by_xpath('//input[@onclick="btnNext_OnClick()"]').click()
return True
except:
print('TAIS codes for all pages were scraped.')
return False
def get_code(driver):
TAIS_codes = []
page = 1
while True:
print(f'page: {page}')
try:
WebDriverWait(driver,10).until(EC.presence_of_element_located((By.XPATH,'//table[@class="spam table"]')))
except:
time.sleep(1)
table = driver.find_element_by_xpath('//table[@class="spam table"]')
for a in table.find_elements_by_xpath('//tr/td[@class="eggbacon"]/a'):
try:
TAIS_codes.append(a.text)
except:
pass
if pagenation(driver):
page += 1
else:
break
with open('data/tais_codes.csv', 'w', newline='') as f:
csv_writer = csv.writer(f, delimiter=',')
csv_writer.writerow(["TAIS"])
for code in TAIS_codes:
csv_writer.writerow([code])
if __name__=='__main__':
driver = set_web_driver()
search_product(driver)
get_code(driver)
driver.quit()
これを実行すると、大体10分くらいで作業は完了しました。
This took about 10 minutes to complete.
python selenium_spider.py

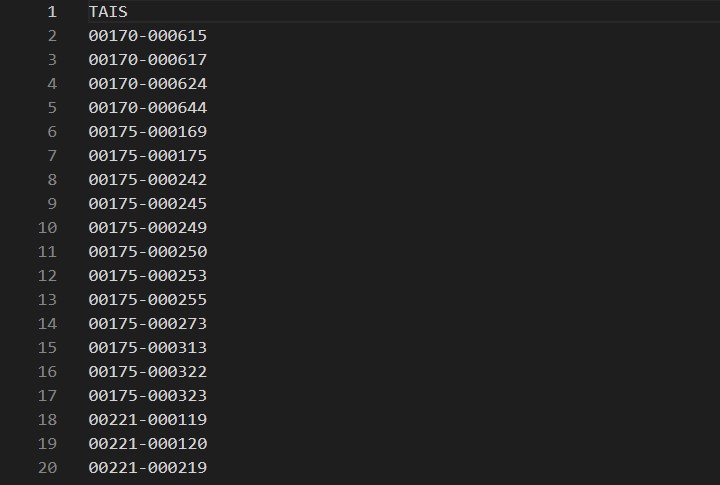
アウトプットされたCSVファイルを見ると10000行くらいありました。
When I looked at the output CSV file, there were about 10,000 lines.
それではrequirements.txtに依存関係パッケージを書き出して、納品します。
I will write down the dependency package in requirements.txt and deliver it.
pip freeze > requirements.txt
case001
data
TAIS_codes.csv # result output data
selenium_spider.py
requirements.txt
git push -u orgin master
以上です。
That's all.
See You Next Page!