Published Date : 2019年8月4日19:47
日本の会社の名前
Imaginative name of a Japanese office
This article has an English translation
事の始まり
The beginning of a thing
ある知り合いに「外国向けのコンテンツを作ったんだけど、日本っぽい会社の名前って自動生成できない?」 と言われました。
One day, one of my friends said, "I created content for foreign countries, but can't you automatically generate the names of Japanese companies?".
さらに、「沢山のデータを利用したい。どっかからスクレイピングとかできない?」 とも言われました。
He also said, "I want to use a lot of data. Can't you scrape from somewhere?".
「できるんじゃない?まあ、気が向いたらやっておくよ。」
I said to him, "I think I can do it. Well, I'll do it if I feel like it."
とは言ったものの、 「はて、どうするものか。。。」 別に強制でもないですが、心の片隅に残っているのも嫌なので、 サクッとファストフード的なアイデアで実装することにしやした。
I said so, but I thought, "Now, how do I make it?". I didn't have to do this, but I didn't want it to be left in the back of my mind, so I decided to implement it with like a "fast food" idea.
取得データ
Decide which data to retrieve
今回まず考えたのは、実際のデータからくる法則性と、適度のランダム感がでるようにすること。
The idea here is to make sure that there's a certain degree of randomness and a certain degree of regularity from the actual data.
そこで、この記事で利用したマルコフモデルを使うのが簡単で面白いかなと思いました。
I thought it would be easy and interesting to use the Markov model used in this article.
そして、「会社の名前」というより、「日本の組織の名前」にしたほうが、集めるのが簡単に、そして良い感じに「日本っぽく」「気の抜けた」感じになると仮定しました。
I then hypothesized that "Names of Japanese organizations" rather than "Company Name" would make it easier and more pleasantly "Japanese style" and "flat" to collect.
さあそうと決まれば集めてくるデータをどうするか? スクレイピングする?
So what do we do with the data we collect? Scraping?
ここで朗報です。 スクレイピングなどしなくても、適切なデータがありました。
Here's good news. There was adequate data without scraping.
このサイトは日本全国約12万の住所データがCSV形式やSQLなどで手に入り、かつ無償です。
This site provides address data of about 120,000 addresses in Japan in CSV format, SQL, etc. and is free of charge.
そしてここには事業所のデータも相当数存在しています。 無償で使えることに感謝してダウンロードしましょう。
And there's a lot of Japanese Office data out there. Thankfully, you can download it for free.
これをPandasでサクッと抽出して、それをマルコフモデルにすれば簡単にそれなりのものが作れます。
のはず。。。
まあ、なにはともあれ、レッツゲットスターテッドでげす。
If you extract this quickly with Pandas and turn it into a Markov model, you can easily make something of it.
It must be...
Well, let's get started anyway.
データの前処理
Data Preprocessing
まず住所.jpから
csv_zenkoku.zip (3,614,142byte)をダウンロードします。
First, download csv_zenkoku.zip (3,614,142byte) from this 住所.jp site.
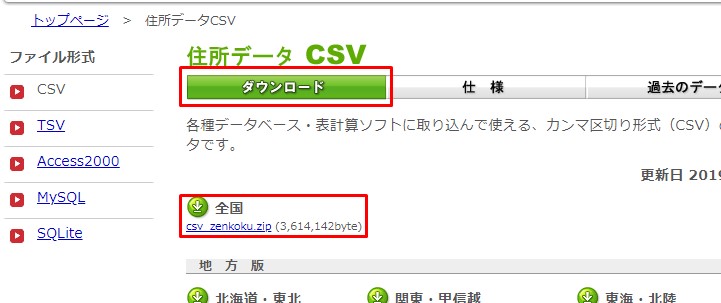
適当な場所に作業用フォルダを作って、 ダウンロードしたZIPファイルを解凍します。
Create a working folder in a location of your choice. Unzip the downloaded ZIP file.
中身はこんな感じです。 ちなみに文字コードは「cp932」です。
The inside looks like this. By the way, the character code is "cp 932".
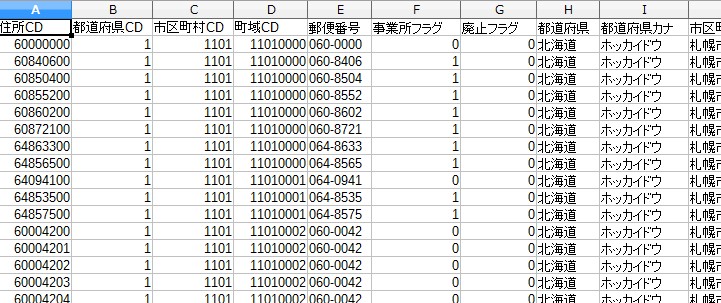
ここに事業所の情報があります。 ざっと見渡したところ「日本っぽい堅い名前」が多いです。 横文字系は少ないかも。
Here is the location information. When I looked around, there were many "a formal Japanese name". There may not be much western language.

ではPandasでファイルを読み込みます。
Now let's preprocess the CSV file by reading it in Pandas.
import pandas as pd
zenkoku = pd.read_csv('zenkoku.csv')
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x8f in position 0: invalid start byte
# はい、先程も言いましたが、文字コードは「cp932」です。
# Yes, as I mentioned earlier, the character code is "cp 932".
# こうします。
# Load it this way.
zenkoku = pd.read_csv('zenkoku.csv',encoding='cp932')
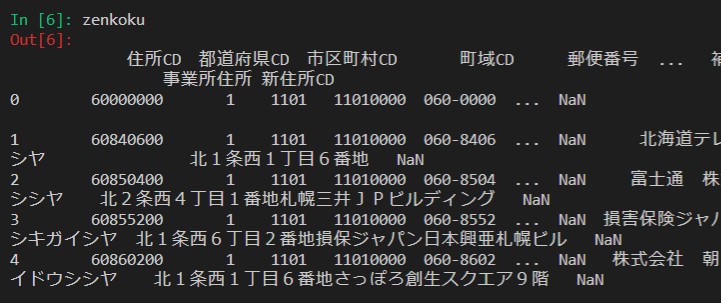
それでは事業所だけを抽出していきます。
Then, we will extract only the offices.
使う列名はこの3つ。
'事業所フラグ'
'事業所名'
'事業所名カナ'
These three column names are used.
'Office location Flag'
'Office Name'
'Office name Kana'
まず事業所フラグでフラグが立っているものを選んで、そのうちの事業所名と事業所名カナを抽出します。
The first step is to select a Office location flag with a flag, and extract the Office name and Office name Kana from the flag.
office_list = zenkoku.loc[zenkoku['事業所フラグ']==1,['事業所名','事業所名カナ']] print(office_list)

マルコフデータ作り
Create data for Markov models
さて、マルコフる前にちょっとだけ味付けします。
今回はサクッとMeCabで形態素解析。
Now, before we build the Markov model, we'll tweak the data a bit.
This time, morphological analysis is simply carried out by MeCab.
import MeCab
tagger = MeCab.Tagger()
# 形態素に分かち書きする関数を用意。
# Provide a function to write a word to a morpheme.
def parse_text(text):
# 全角スペース(ノーマルのスペース2個分)を半角スペースに直す(ノーマルのスペース)
# Convert a full-pitch space (2 normal spaces) into a half-pitch space (normal space)
text = text.replace('\u3000',' ')
# 形態素解析をして、分かち書きにする。
# Morphological analysis is carried out to write the words.
parsed_text = tagger.parse(text)
# 表層系だけ取り出す。
# Only the words of the surface are extracted.
parsed_text = [pt.split('\t')[0] for pt in parsed_text.split('\n') if pt != 'EOS' and pt != '']
return parsed_text
そのままだと、あまり変化が無いので、 実際の日本で使われている会社の名前の一部が、 良い感じにシャッフルして出てくるようにしていきます。
As it is, there is not much change. So, I will try to shuffle out some of the names of companies that are actually used in Japan.
とりあえず、形態素した漢字とフリガナをリストにする。
First of all, I will make a list of morpheme kanji and reading.
name_list1 = office_list['事業所名'].apply(parse_text).tolist() print(name_list1)
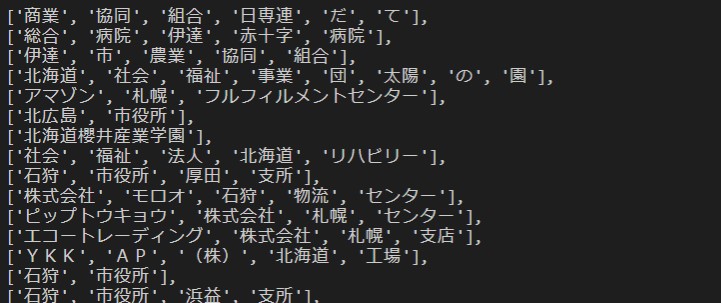
name_list2 = office_list['事業所名カナ'].apply(parse_text).tolist() print(name_list2)
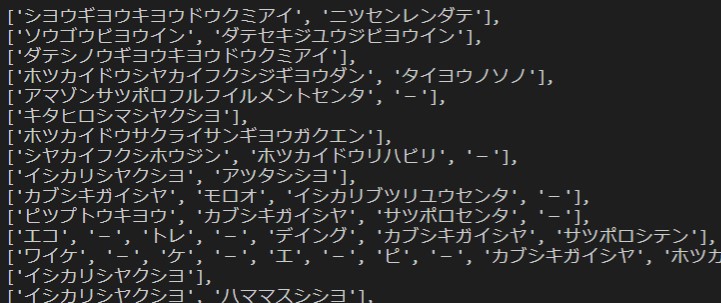
それではデータの仕上げです。
Let's finish up the data.
import random
new_office_list = []
for i,n1 in enumerate(name_list1):
n2 = name_list2[i]
# ランダムにシャッフル。
# Random shuffle.
random.shuffle(n1)
random.shuffle(n2)
# それぞれ交互にリストに追加したいが、長さがバラバラなので、二回同じことをする。
# I want to add them to the list alternately, but the length is different, so I do the same thing twice.
for n in n1:
new_office_list.append(n)
for n in n2:
new_office_list.append(n)
できたものはこんな感じ。
The result looks like this.
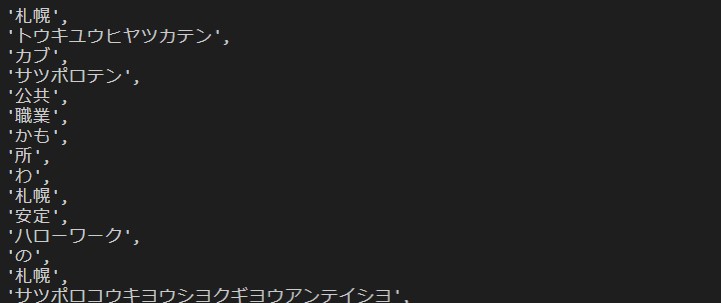
# これを適度な長さの文にして、改行で区切った一つの文章にする。
# This is reduced to a reasonably long sentence, separated by newlines.
new_text_data = []
# 分かち書きされたものを3つずつ合わせて、語彙数が3つになるようにする。
# Add three words at a time so that you have three words.
# それ以上でも以下でもいい、自由にやればよい。
# You can do more or less freely.
for l in range(0,len(new_office_list),3):
new_text_data.append(' '.join(new_office_list[l:l+3]))
実食
cause to try
# マルコフる
# Import Library to Create Markov Models
# Install with pip if you don't have this library. [pip install markovify]
import markovify
# 非常に簡単ワンライン
# It's very easy to build a model. You can write in one line.
office_name_model = markovify.NewlineText('\n'.join(new_text_data))
# 100回メイクセンテンス
# Run 100 times.
for _ in range(100):
predicted_office_name = office_name_model.make_sentence()
# Noneとして予測されない値も出てくるので、それを考慮する。
# If a statement cannot be created, it returns None and ignores it.
if predicted_office_name == None:
pass
else:
print(''.join(predicted_office_name.split()))
結果発表
Results
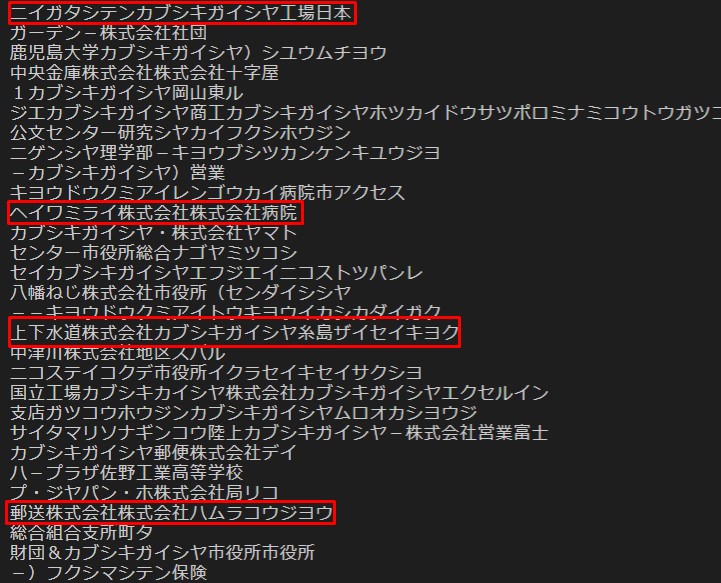
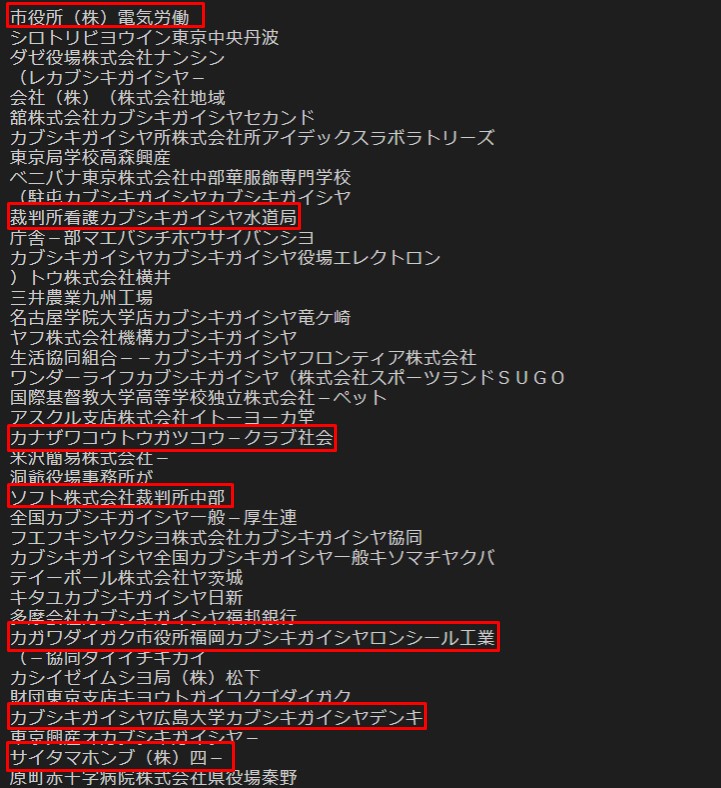
いや、株式会社なのか大学なのか市役所なのか水道局なのか銀行なのか財務局なのかどっちやねん。 株式会社つけ過ぎ問題が発生しております。
No, it's either a stock company, university, city hall, waterworks bureau, bank or finance bureau. There is a problem with overcharging.
とまあ、こんな感じでゆるいものはものの10分ぐらいで作れてしまうのです。
Well, it takes about 10 minutes to make something loose like this.
これをHerokuにアップして、遊べるようにしました。 上のナビバーに仕込んであります。
I uploaded this to Heroku so that I can play with it. This is the top Navi Bar.
Herokuへのアップロードの方法は、このマルコフアプリの作り方と、前前回あたりの記事を参考にしてくだちぃ。
How to upload to Heroku is based on this How to Create Markov app and previous posts.
でもちょっとだけアプリにするためのコードを書いておきます。
But I'll write a little bit of code to make it an app.
アプリにするため、モデルをJSONファイルとしてエクスポート。
Export the model as a JSON file to make it an app.
model_json = office_name_model.to_json()
import json
with open('model.json','w') as f:
json.dump(model_json)
ロードして使う時は以下のようにする。
Here's how to load and use it.
import json
import markovify
with open('model.json','r') as f:
model_json = json.load(f)
reconstituted_model = markovify.Text.from_json(model_json)
for _ in range(100):
predicted_name = reconstituted_model.make_sentence()
if predicted_name == None:
pass
else:
print(''.join(predicted_name.split()))
Flaskで書いた簡単なコードと、HTMLファイルのコードです。
The simple code in Flask and the code in the HTML file.
templates/main.html
<!DOCTYPE html>
<html lang="jp-ja">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Create Office Name</title>
<!-- bootstrap の css link -->
<link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.3.0/css/bootstrap.min.css" integrity="sha384-PDle/QlgIONtM1aqA2Qemk5gPOE7wFq8+Em+G/hmo5Iq0CCmYZLv3fVRDJ4MMwEA" crossorigin="anonymous">
</head>
<body>
<div class="container text-center">
<h3 style="text-align:center; padding: 3rem 0 0 0;">Imaginative name of a Japanese office</h3>
<div class="form-group" style="padding: 0 3rem 0 3rem;">
<form action="generate" method="get">
<!-- Jinja2 の For Loop -->
<input type="submit" class="btn btn-primary" style="margin: 2rem 0 0 0;" value="Create a name for a Japanese office">
</form>
</div>
<br>
<div class="container text-left border border-primary" style="padding:3rem;">
<!-- Jinja2 の For Loop -->
{% for o_n in office_name %}
<p>{{o_n}}</p>
{% endfor %}
</div>
</div>
<!-- bootstrap の javascript link -->
<script src="https://code.jquery.com/jquery-3.3.1.slim.min.js" integrity="sha384-q8i/X+965DzO0rT7abK41JStQIAqVgRVzpbzo5smXKp4YfRvH+8abtTE1Pi6jizo" crossorigin="anonymous"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/popper.js/1.14.7/umd/popper.min.js" integrity="sha384-UO2eT0CpHqdSJQ6hJty5KVphtPhzWj9WO1clHTMGa3JDZwrnQq4sF86dIHNDz0W1" crossorigin="anonymous"></script>
<script src="https://stackpath.bootstrapcdn.com/bootstrap/4.3.0/js/bootstrap.min.js" integrity="sha384-7aThvCh9TypR7fIc2HV4O/nFMVCBwyIUKL8XCtKE+8xgCgl/PQGuFsvShjr74PBp" crossorigin="anonymous"></script>
</body>
</html>
./main.py
from flask import Flask, render_template, request
import os
import json
import markovify
app = Flask(__name__)
@app.route('/')
def index():
return render_template('main.html')
@app.route('/generate', methods=['GET'])
def main():
with open('model.json','r') as f:
model_json = json.load(f)
reconstituted_model = markovify.Text.from_json(model_json)
office_name = []
for _ in range(10):
predicted_name = reconstituted_model.make_sentence()
if predicted_name == None:
pass
else:
office_name.append(''.join(predicted_name.split()))
return render_template('main.html',office_name=office_name)
if __name__ == "__main__":
# Herokuからポート番号を取得するようにする。
# Get the port number from Heroku.
port = int(os.getenv("PORT"))
app.run(host='0.0.0.0', port=port, debug=True)
Procfile
web: gunicorn main:app --preload --timeout 10 --max-requests 1200 --log-file=-
おわりに
Conclusion
時間があればもっとちゃんとしたものを勉強して作ってみたいです。
If I have time, I want to learn more and make it.
長々とお付き合い頂きありがとうございます。
Thank you for reading this long blog.
See You Next Page!