Published Date : 2019年7月15日8:06
Deep Manzai Part 9 〜 AIML 〜
This article has an English translation.
前回の簡単なあらすじ
A brief summary of the previous article.
Transformerと強化学習を組み合わせたら面白いのでは無いかと思い、強化学習について簡単な説明を行った。
I thought it would be interesting to combine Transformer and reinforcement learning, so I gave a brief explanation of reinforcement learning.
しかし、理解に時間が掛かるため、一旦学習を止めて、AIMLでチャットボットを作り、どうなるか確かめてみることに。
But understanding takes time, so I stopped learning and created a chat bot with AIML to see what happens.
以上が大体の話の流れです。
That's the general flow of the story.
AIML (Artificial Intelligence Markup Language)
AIML?
AIMLとは簡単に説明すると、 ルールベースで(決められたルールを元に) 会話を作るために設計されたマークアップ言語です。
AIML is simply a markup language designed to create rule-based, (Based on the established rules) conversations.
詳しい説明をしてくれている記事と、前々回お世話になったコードの説明をしてくれている記事のURLを以下に貼っておきます。
Here's the URL to the article that explains the details and the code you helped me with around the previous article.
今更ながら、AIML(Artificial Intelligence Markup Language)入門
AIが流行ってる今だからこそルールベースのチャットボットをAIMLで作ってみる【Python】その2
それではさっそくコードを書いていきます。
I'll write the code now. Let's get started!
収集するサイトのURLは明かしません。 何故なら、サーバーに負担をかけるからです。
I will not reveal the URL of the site to collect. Because it puts a strain on the server.
その代わり、今回はgithubに既に出来上がったAIMLファイルをアップしておきました。ご自由にお使い下さい。
Instead, I've uploaded an AIML file on github. Please feel free to use it.
https://github.com/akasatanahama772/manzai_data
データ前処理 -Data Preprocessing-
データを集め、前処理を行うところから開始します。
Start by collecting data and preprocessing it.
Scrapyのプロジェクトを作る為、適当な名前のフォルダを作って、そこに移動してください。
To create a Scrapy project, create a folder with an appropriate name and move it there.
$ cd Desktop $ scrapy startproject manzai $ cd manzai $ scrapy genspider manzai_daihon
前に行ったスクリプトと殆ど変化がありません。 なので、細かいところは下記の記事を参考にしてください。
It is almost the same as the previous script. Check out the article below for details.
Deep Manzai Part 1 〜 前半戦 〜Scrapy、自然言語処理、モーニング娘。
# -*- coding: utf-8 -*-
import scrapy
from manzai.items import ManzaiItem
class ManzaiDaihonSpider(scrapy.Spider):
name = 'manzai_daihon'
allowed_domains = ['spam.ham.bacon.com']
start_urls = ['http://spam.ham.bacon.com/']
def parse(self, response):
for i in range(114):
next_num=f'page/{i+1}'
next_page=response.urljoin(next_num)
if next_page:
item=ManzaiItem()
request=scrapy.Request(next_page,callback=self.get_link,dont_filter=True)
request.meta['item']=item
yield request
def get_link(self,response):
item=response.meta['item']
a_s=response.xpath('//div[@id="list"]/a')
hrefs=[a.xpath('@href').get() for a in a_s]
for href in hrefs:
if href:
request=scrapy.Request(href,callback=self.get_article,dont_filter=True)
request.meta['item']=item
yield request
def get_article(self,response):
item=response.meta['item']
if response.xpath('//h2/text()')[0].get()!='\n ':
item['title']=response.xpath('//h2/text()')[0].get()
else:
item['title']=response.xpath('//h1[@class="entry-title"]/text()').get().strip()
item['article']=[]
entry_content_divs=response.xpath('//div[@class="entry-content cf"]/div')
if len(entry_content_divs)>1:
for ecd in entry_content_divs:
if ecd.xpath('@class').get()=='tukkomi' or ecd.xpath('@class').get()=='boke' or ecd.xpath('@class').get()=='mannaka':
item['article'].append(ecd.xpath('@class').get()+': '+ecd.xpath('text()').get())
else:
p_s=entry_content_divs[0].xpath('//p')
for p in p_s:
p=p.xpath('text()').get()
try:
if ':' in p:
item['article'].append(p)
except:
pass
yield item
# スパイダーを実行。 # Run the spider. $ scrapy crawl manzai_daihon -o manzai_daihon.json
それでは台本を漫才だけに絞り込んで、さらに処理を進めていきます。
Then, we will focus the script on manzai and proceed further.
import requests
from bs4 import BeautifulSoup
# Wikipediaの漫才師一覧から情報を取得。
# Get information from Wikipedia's list of manzaishi.
res=requests.get('https://ja.wikipedia.org/wiki/%E6%BC%AB%E6%89%8D%E5%B8%AB%E4%B8%80%E8%A6%A7')
# HTMLパーサーにlxmlを指定し、整形しやすいようにする。
# Specify lxml for the HTML parser to make formatting easier.
soup=BeautifulSoup(res.content,'lxml')
# 全liタグを取ってくる。
# Fetch all the li tags.
lis=soup.find_all('li')
# aタグが無いバージョンも考慮して、漫才師リストの終わりも指定して、配列に格納。
# The end of the manzaishi list is also specified and stored in the array, considering the version without the a tag.
manzaishi_list=[]
for li in lis:
try:
manzaishi_list.append(li.a.string)
except:
if li.string.startswith('「現代上方演芸人名鑑」'):
break
else:
manzaishi_list.append(li.string)
import dill
# BS4のオブジェクトをストリング型に直す。(このままではPickle化できないため)
# Convert the BS4 object to a string type. (You can't Pickle it.)
manzaishi_list=[str(ml) for ml in manzaishi_list]
# 保存する。
# Save.
with open('manzaishi_list.pkl','wb') as f:
dill.dump(manzaishi_list,f)
AIMLファイルに直していく。
Convert to an AIML file.
import json
import dill
# クロールして取ってきたJSONファイルを読み込む。
# Read the JSON file that was crawled.
with open('daihon.json','r',encoding='utf-8') as f:
daihon=json.load(f)
# Wikipediaから収集した漫才師リストを読み込む。
# It reads the list of manzaishi gathered from Wikipedia.
with open('manzaishi_list.pkl','rb') as f:
manzaishi_list=dill.load(f)
# タイトルだけに分ける。
# divide into titles only.
titles=[d['title'] for d in daihon]
# タイトルから漫才師の名前だけ抜き取る。
# Only the name of the manzaishi is extracted from the title.
splited_titles=[title.split('「')[0] for title in titles]
# 漫才の台本を抜き取る。
# The script of manzai is picked out.
manzaishi_daihon=[daihon[i] for i,st in enumerate(splited_titles) if st in manzaishi_list]
# セリフの応答を対にして、リストの中にリストが入るようにする。
# Pairing the dialogue responses so that the list is included in the list.
req_res=[]
for md in manzaishi_daihon:
m_role=[m.split(': ')[0] for m in md['article']]
temp=[]
for i in range(1,len(m_role)):
if i-1==0:
try:
temp.append(md['article'][i-1].split(': ')[1])
except:
temp.append(md['article'][i-1])
temp_length=len(temp)
if i>0 and m_role[i-1]==m_role[i]:
try:
temp[temp_length-1]+=md['article'][i].split(': ')[1]
except:
temp[temp_length-1]+=md['article'][i]
else:
try:
temp.append(md['article'][i].split(': ')[1])
except:
temp.append(md['article'][i])
req_res.append(temp)
# 中身はこんな感じ。
# The inside looks like this.
In [10]: req_res[0]
Out[11]:
['いらっしゃいませ。こちらの指輪なんか新作で非常に人気ですね~。一
見派手ですけどつけてるうちになじんできますんで。今日のお客様みたい
なカジュアルな服にも似合うと思いますよ。つけてみますか?',
'あ~大丈夫です。自分でつけるやつじゃないんで。',
'あ~転売ですか?',
'あっ違いますね。あの~ちょっと彼女にプレゼントであげようかなと思
ったんですけど。',
.............................
.............................]
漫才師の台本を用意できたら、後はAIMLファイルに直す関数を作り実行するだけ。
Once you have prepared a Manzaishi script, all you have to do is create and execute a function to convert it into an AIML file.
import xml.etree.ElementTree as ET
def make_aiml_simple(req_res):
# 前後で文脈が合うように、一つずつズラして対になるようにリスト化する。
# List them one by one in pairs so that the context matches.
enc_dec=[[rr[i-1],rr[i]] for rr in req_res for i in range(1,len(rr))]
aiml = ET.Element('aiml',{'version':'1.0.1' ,'encoding':'utf-8'})
for text_ in enc_dec:
category = ET.SubElement(aiml, 'category')
pattern = ET.SubElement(category, 'pattern')
pattern.text = ' '.join(list(text_[0]))
template = ET.SubElement(category, 'template')
template.text = text_[1]
return aiml
aiml=make_aiml_simple(req_res)
aiml_tree=ET.ElementTree(element=aiml)
aiml_tree.write('manzai_aiml.xml', encoding='utf-8', xml_declaration=True)
ここまでできたら、動くかどうか試してみる。 Python用のAIMLモジュールをインストールしていなければ以下のコマンドを打つ。
I'll see if it works. If you don't have the AIML module for Python installed, type the following command.
$ pip install python-aiml
ユーザーからの入力で、応答の数とバリエーションを増やすための関数を作る。 その後にループさせて、応答文を試してみる。
Create a function to increase the number and variation of responses to user input. Then loop it and try the response.
import aiml
import time
def append_aiml(k):
tree_ = ET.ElementTree(file='manzai_aiml_test.xml')
root = tree_.getroot()
category = ET.SubElement(root, 'category')
pattern = ET.SubElement(category,'pattern')
print('\n覚えさせたい言葉を入力してくだちぃ。日本語限定です。')
text = input('Enter the words you want AIML to remember. It is limited to Japanese.> ')
pattern.text = ' '.join(list(text))
template=ET.SubElement(category,'template')
print('\nどんな言葉が返ってくるといいですか?日本語限定です。')
text = input('What kind of words should I get from AIML? It is limited to Japanese.> ')
template.text = text
tree_.write('manzai_aiml.xml', encoding='utf-8', xml_declaration=True)
print('\n言葉を覚えたよ。')
print('Okay. AIML learned the language.')
time.sleep(1)
print('\nAIMLのファイルをロードしているよ。')
print("loading a new AIML file.")
k = aiml.Kernel()
k.learn("manzai_aiml_test.xml")
return k
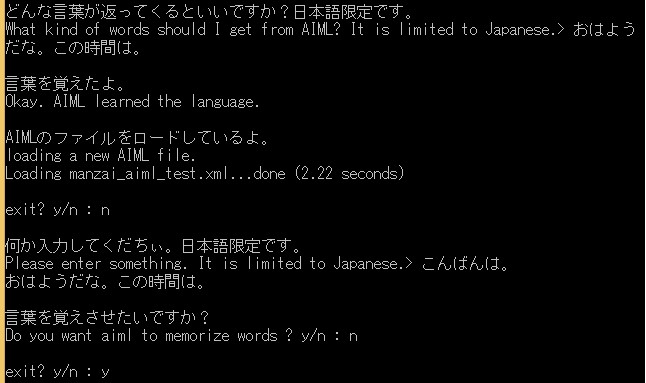
k = aiml.Kernel()
k.learn("manzai_aiml.xml")
while True:
ex = input("\nexit? y/n : ")
if ex=='y':
break
print('\n何か入力してくだちぃ。日本語限定です。')
response = input("Please enter something. It is limited to Japanese. > ")
print(k.respond(response))
print('\n言葉を覚えさせたいですか?')
learning = input('Do you want aiml to memorize words ? y/n : ')
if learning == 'y':
k=append_aiml(k)
else:
pass

MeCabを使う場合 -When using MeCab-
今回はMeCabを使って分かち書きする必要は無かったので、使っていませんが、もし、複雑なパターンや、条件分岐、細かい品詞の指定がしたければ、MeCab等の形態素解析のモジュールを使ってください。
I don't use MeCab because I didn't have to do this, but if you want to specify complex patterns, conditional branching, and fine parts of speech, use a morphological analysis module such as MeCab.
例えば、ユーザー辞書を使って漫才師の名前を登録する場合などに必要になってきます。(漫才師の名前は固有名詞として登録されていないことが多い)
For example, it is necessary to register the name of a manzaishi using a user dictionary. (Manzaishi's name is often not registered as a proper noun.)
今回はMacを使います。Windowsでも簡単にできますので、ネットで調べて実行してみてください。
I use Mac this time. You can do it easily on Windows, so please check it on the Internet and try it.
Windowsを使っている人は、この記事を読めば簡単にセットアップできます。
If you're running Windows, this article will help you set it up easily.
# home brewを使ってMeCabをインストール。 # Install MeCab using home brew. $ brew install mecab # 辞書もインストールしておく。 # I also install a dictionary. $ brew install mecab-ipadic # Pythonで使えるようにpipでモジュールをインストールする。 # Install the module with pip for use with Python. $ brew install swig $ pip install mecab-python3
# pandasを使ってユーザー辞書の素となるCSVファイルを作成する。
# Use pandas to create a CSV file that will serve as the basis for your custom dictionary.
import pandas as pd
columns=['表層形','左文脈ID','右文脈ID','コスト','品詞','品詞細分類1','品詞細分類2','品詞細分類3','活用形','活用型','原形','読み','発音']
# 必要な情報を入れておく。
# Fill in the necessary information.
user_dict=[[ml,-1,-1,1000,'名詞','固有名詞','*','*','*','*',ml,ml,ml] for ml in manzaishi_list]
df=pd.DataFrame(user_dict,columns=columns)
df.to_csv('user.csv',index=False)
# あとは以下のコマンドで登録完了。 # Then register with the following command. /usr/local/libexec/mecab/mecab-dict-index -d/usr/local/lib/mecab/dic/ipadic -f utf-8 -t utf-8 -u user.dic user.csv

# 作ったユーザー辞書を移動させる。 # Move the custom dictionary you created. $ mv user.dic /usr/local/lib/mecab/dic/ipadic/user.dic
# ユーザー辞書のパスを登録する。 # Register the path of the custom dictionary. $ sudo nano /usr/local/etc/mecabrc
; userdict = /home/foo/bar/user.date-icon -> userdict = /usr/loacal/lib/mecab/dic/ipadic/user.dic
# ユーザー辞書が反映されているか試してみる。 # Try to see if the custom dictionary is reflected. $ mecab 若井はんじ・けんじ

次回へ続く -To be continued next time-
後はこれをウェブアプリとしてデプロイさせれば完成です。 お疲れさまでした。
All you have to do is deploy it as a web app. Thank you for your hard work.
See You Next Page!