Published Date : 2019年5月20日7:46
Deep Manzai Part 1 〜 前半戦 〜
Abstract
今回は漫才(MANZAI)を、
Pythonで挑戦したい
と思います。
とは言っても、 今の自分で 思いつく事といったら、 文章生成(Text Generator)、 クラスタリング(clustering)、 感情分析(Sentiment Analysis) くらいしか思いつきませんが、 ひとまず見切り発車で やっていこうと思います。
とは言っても、 今の自分で 思いつく事といったら、 文章生成(Text Generator)、 クラスタリング(clustering)、 感情分析(Sentiment Analysis) くらいしか思いつきませんが、 ひとまず見切り発車で やっていこうと思います。
三億番煎じ
数多の戦士達が
Pythonを使って
Deep Learningをしてきました。
同時に自然言語処理 (Natural Language Processing)
テキストマイニング (Text mining) もやり尽くされています。
そんな三億番煎じ目 くらいの記事なので、
車輪の再発明 (reinventing the wheel) は行わず、
堂々と偉大な先人の知恵を お借りしていこうかと思います。
同時に自然言語処理 (Natural Language Processing)
テキストマイニング (Text mining) もやり尽くされています。
そんな三億番煎じ目 くらいの記事なので、
車輪の再発明 (reinventing the wheel) は行わず、
堂々と偉大な先人の知恵を お借りしていこうかと思います。
やりたいこと
| 1 | データ収集(Data Scraping) |
|---|---|
| 2 | 前処理(Preprocessing) |
| 3 | 分析(Analyizing) |
| 4 | Build Neural Network |
| 5 | Word2Vecを使う |
| 6 | LSTMによる文章生成 |
データ収集
Scraping
早くコードを書けよ
ぐだぐだ言ってねーで
コードを書けよ!
さーせん。コード神。 すぐに取り掛かりMASU!
さーせん。コード神。 すぐに取り掛かりMASU!
中島〜またスクレイピングかよ
# Scrapyのプロジェクトを作るぜ! scrapy startproject manzai # 光の速さで移動しろ! cd manzai # Spiderを作るぜ!spider man spider man ~ # お嬢ちゃん。プロジェクト名と同じ名前は避けるんだな。 scrapy genspider manzai_daihon spamhameggbaconspam.com
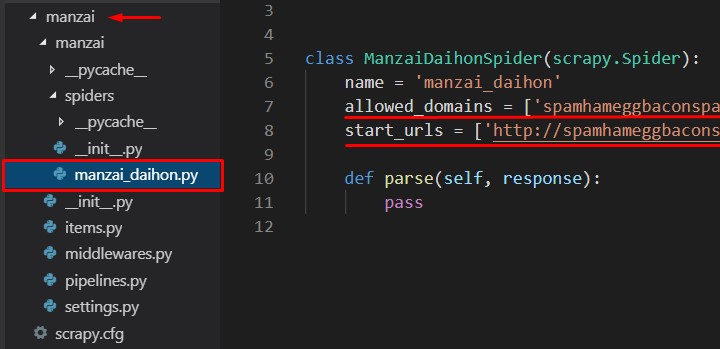
取り敢えず相手サーバーに、
迷惑がかかるといけないので、
具体的なURLは避けますが、
MANZAIのスクリプト(台本) と言えばここなので、 普通に探せるかなと。
私はこの台本ページを 作ってくれてる人を尊敬してます。
自分にゃ無理です。
多分好きなナイツですら、 始めの掛け合い2行ぐらいで 眠ります。
MANZAIのスクリプト(台本) と言えばここなので、 普通に探せるかなと。
私はこの台本ページを 作ってくれてる人を尊敬してます。
自分にゃ無理です。
多分好きなナイツですら、 始めの掛け合い2行ぐらいで 眠ります。
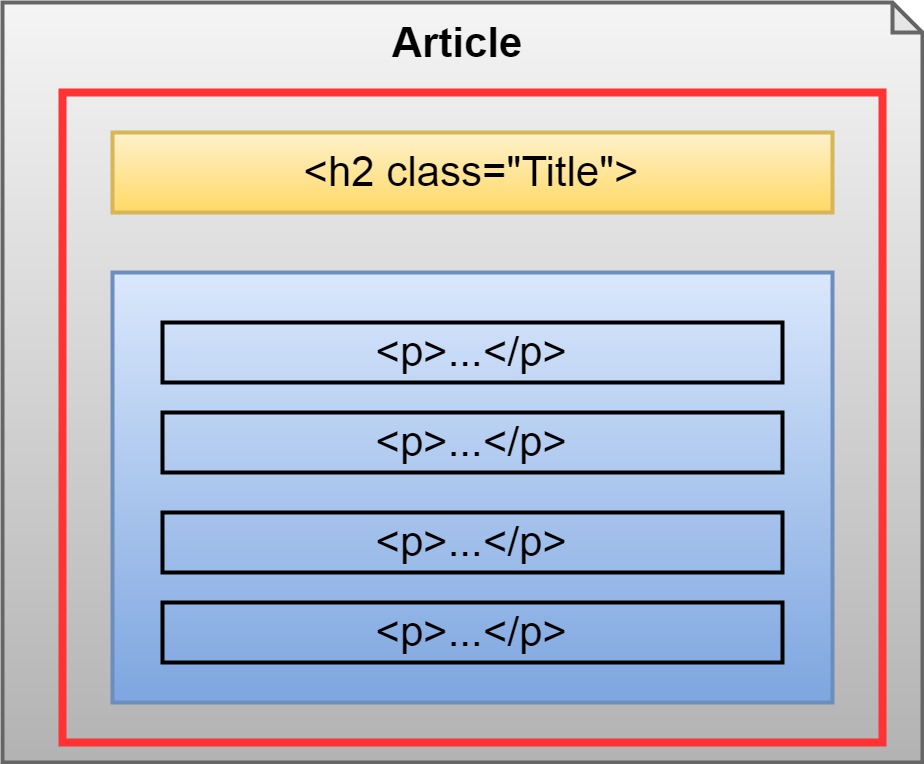
HTML構造
HTMLの構造ですが、
画像みてくれ、 そのほうが早い。
画像みてくれ、 そのほうが早い。

簡単に略すと、
下のページ送りは
上のURLと対応してる。
一つの記事はDiVタグのリスト。 その中のaタグに記事URLがある。
Scraping処理としては、 ページを送りつつ、 記事のURLに飛び、
MANZAIの台本をGETだぜ!
の、繰り返しでR。
一つの記事はDiVタグのリスト。 その中のaタグに記事URLがある。
Scraping処理としては、 ページを送りつつ、 記事のURLに飛び、
MANZAIの台本をGETだぜ!
の、繰り返しでR。
ぼちぼちコードを書いていきマス。
レッツスパイダーといきたい ところをぐっと我慢して、
まず先にsettings.pyと items.pyを編集しましょう。
レッツスパイダーといきたい ところをぐっと我慢して、
まず先にsettings.pyと items.pyを編集しましょう。
settings.py と items.py
日本語が扱えるように、
サーバーの負担を減らすため、
キャッシュをとり、 次回からの処理を速くするため、
記事を保存するため、
そして、地球の平和を守るために 我々は2つのPythonファイルを 編集しなければならない!
キャッシュをとり、 次回からの処理を速くするため、
記事を保存するため、
そして、地球の平和を守るために 我々は2つのPythonファイルを 編集しなければならない!
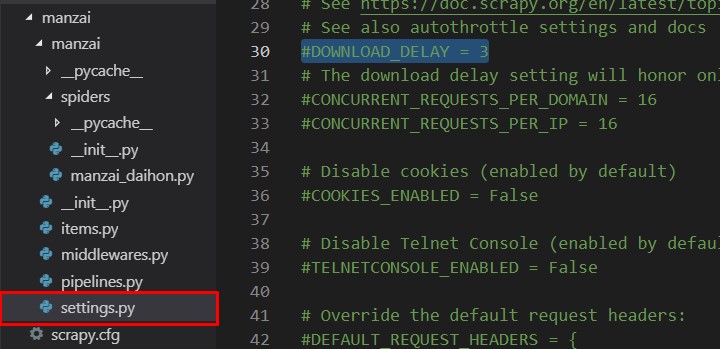
まずはsettings.pyの編集。
# ダウンロード間隔を設ける(必須!) -> #DOWNLOAD_DELAY = 3 # コメントアウトする。#を消す。 -> DOWNLOAD_DELAY = 3 # キャッシュ有効化 -> #HTTPCACHE_ENABLED = True # コメントアウトする。#を消す。 -> HTTPCACHE_ENABLED = True # 日本語を扱えるようにする(必須!) # 以下の呪文を付け足す。 FEED_EXPORT_ENCODING='utf-8'
お次はitems.pyの編集。
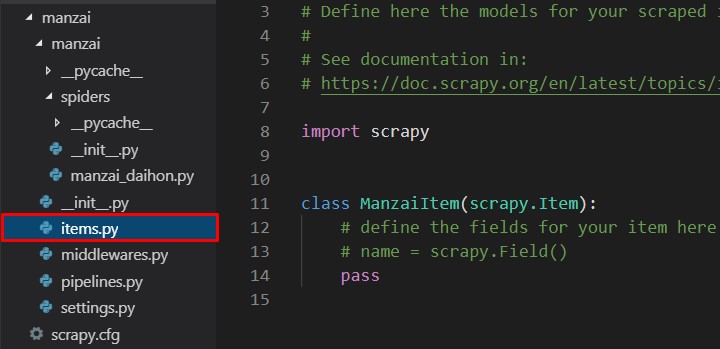
class ManzaiItem(scrapy.Item): # コメントとpassを消して、以下を挿入。 title = scrapy.Field() article = scrapy.Field()
Lets Spider
コードの弾幕薄いぞ!
なにやってんの!
つーことで一気に全コード。
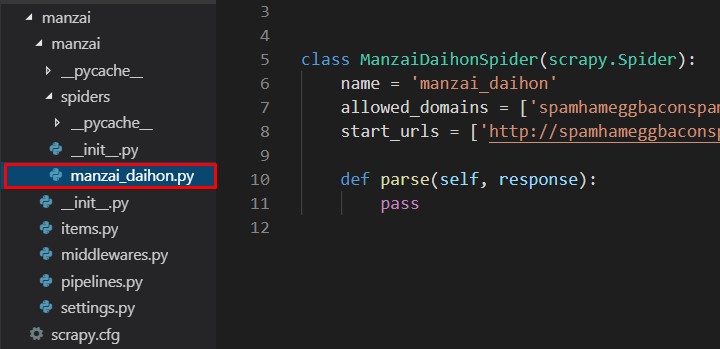
manzai_daiho.py
# -*- coding: utf-8 -*-
import scrapy
from manzai_daihon.items import ManzaiItem
class ManzaiDaihonSpider(scrapy.Spider):
name = 'manzai_daihon'
allowed_domains = ['spamhameggbaconspam.com']
start_urls = ['http://spamhameggbaconspam.com/']
def parse(self, response):
for i in range(103):
next_num=f'page/{i+1}'
next_page=response.urljoin(next_num)
if next_page:
item=ManzaiItem()
request=scrapy.Request(next_page,callback=self.get_link,dont_filter=True)
request.meta['item']=item
yield request
def get_link(self,response):
item=response.meta['item']
a_s=response.xpath('//div[@id="list"]/a')
hrefs=[a.xpath('@href').get() for a in a_s]
for href in hrefs:
if href:
request=scrapy.Request(href,callback=self.get_article,dont_filter=True)
request.meta['item']=item
yield request
def get_article(self,response):
item=response.meta['item']
if response.xpath('//h2/text()')[0].get()!='\n ':
item['title']=response.xpath('//h2/text()')[0].get()
else:
item['title']=response.xpath('//h1[@class="entry-title"]/text()').get().strip()
boke=response.xpath('//div[@class="boke"]/text()')
tukkomi=response.xpath('//div[@class="tukkomi"]/text()')
item['article']={}
if boke==[]:
m_divs=response.xpath('//ins[@class="adsbygoogle"]')
m_text=[]
for m_div in m_divs:
if m_div.xpath('following-sibling::p')!=[]:
m_text.append(m_div.xpath('following-sibling::p/text()'))
if len(m_text)>1:
for m in m_text[0]:
if item['article']=={}:
item['article']['manzai']=[]
item['article']['manzai'].append(m.get().replace('\u3000',' '))
else:
item['article']['manzai'].append(m.get().replace('\u3000',' '))
else:
m_tds=m_div.xpath('following-sibling::table//td/text()')
if m_tds!=[]:
item['article']['manzai']=[m_td.get() for m_td in m_tds]
else:
if tukkomi!=[]:
item['article']['boke']=[b.get() for b in boke]
item['article']['tukkomi']=[t.get() for t in tukkomi]
elif item['title']=='ある芸人1の台本' or item['title']=='ある芸人2の台本' or item['title']=='ある芸人3の台本':
item['article']['boke']=[t.get() for t in tukkomi]
item['article']['tukkomi']=[b.get() for b in boke]
else:
print('pin')
item['article']['pin']=[b.get() for b in boke]
yield item
後半へ続く
なんでこんな切りの悪い
ところで、後半へ続くかって?
気付いて無いかもしれないが、 今日は月曜日さ!
Blue Mondayさ! ははは!HAHAHA!はは...
それではまた次回。
See You Next Page !
気付いて無いかもしれないが、 今日は月曜日さ!
Blue Mondayさ! ははは!HAHAHA!はは...
それではまた次回。
See You Next Page !