Published Date : 2019年6月23日20:52
Deep Manzai Part 7
前回の簡単なあらすじ
前回は
seq2seqの
改良版Attentionを使った、
Chainerの応答文 生成モデルを
WEBアプリにしました。
コードはこちらの方のブログを そっくり使わせていただきました。 Attention Seq2Seqで対話モデルを実装してみた
改めて謝謝多謝メルシーボークーです!
Chainerの応答文 生成モデルを
WEBアプリにしました。
コードはこちらの方のブログを そっくり使わせていただきました。 Attention Seq2Seqで対話モデルを実装してみた
改めて謝謝多謝メルシーボークーです!
Transformerより先にすること
さて、前回は諸事情があり、
Chainerを使いました。
しかし今回Transformerと Beamsearchをするにあたって、 Githubを漁った結果、
Keras版を最初に見つけてしまい、 データの前処理と、 オリジナルソースコードに合わせて 調整するのに時間が かかってしまったので、
(データ処理が英語を 前提としてるので、 毎回頭を悩ませる。)
今回はKerasでやっていきます。
そしてprototype demoとして 作った前回のWEBアプリも、 環境を変えて作り直しです。
CORESERVERで 頑張っていきたかったのですが、
諸々の事情により、 やっぱりHerokuかAWSに デプロイしようかと 思っております。はい。
しかし今回Transformerと Beamsearchをするにあたって、 Githubを漁った結果、
Keras版を最初に見つけてしまい、 データの前処理と、 オリジナルソースコードに合わせて 調整するのに時間が かかってしまったので、
(データ処理が英語を 前提としてるので、 毎回頭を悩ませる。)
今回はKerasでやっていきます。
そしてprototype demoとして 作った前回のWEBアプリも、 環境を変えて作り直しです。
CORESERVERで 頑張っていきたかったのですが、
諸々の事情により、 やっぱりHerokuかAWSに デプロイしようかと 思っております。はい。
再びスクレイピング
さて、今回使わせて頂いたコード、
attention-is-all-you-need-keras
最大級でイェーイェーイェー感謝をします。
そして、前回等ではやらなかった Validation Dataも 用意しなくてはならなくなりました。
そこで、前前前回あたりで 使用データのスクレイピングをしましたが、
大分時間が経っているので、 もう一度、新たに台本を取得して 検証用に使用したいと思います。
そして、学習モデルに汎用性をもたせるため、 新しく加わった台本を取得していきます。
下記の過去記事を参考にしてくだちぃ。
記事27
記事28
取得した後の前処理は こちらの記事を参考にしてくだちぃ。
そして、前回等ではやらなかった Validation Dataも 用意しなくてはならなくなりました。
そこで、前前前回あたりで 使用データのスクレイピングをしましたが、
大分時間が経っているので、 もう一度、新たに台本を取得して 検証用に使用したいと思います。
そして、学習モデルに汎用性をもたせるため、 新しく加わった台本を取得していきます。
下記の過去記事を参考にしてくだちぃ。
記事27
記事28
取得した後の前処理は こちらの記事を参考にしてくだちぃ。
もういくつ寝るとお正月
なんと気付いたら
今年の半分が終わっています。
ああ、儚い。。。
それではオリジナルソースのデータの形状と 既存訓練用データの形状を
合わせる必要があるので、 何回も似たような 作業の繰り返しDESU。
まず先に訓練用データの前処理と、 次に検証用データを作っていきます。
それではオリジナルソースのデータの形状と 既存訓練用データの形状を
合わせる必要があるので、 何回も似たような 作業の繰り返しDESU。
まず先に訓練用データの前処理と、 次に検証用データを作っていきます。
まずは訓練用データの整形
# 前回作った台本データを取り出す。
import dill
with open('data/append_data.pkl','rb') as f:
append_data=dill.load(f)
# 一応確認
"""
print(append_data[0])
[[['どう', 'も', '~', '2', '丁', '拳銃', 'です', 'よろしく', 'お', '願い', 'し', 'ます', '。', 'どう', 'も', 'ビートルズ', 'です', '。']],
[['似', 'てる', '似', 'てる', 'わ', 'お前', 'は', '。', '4', '人', '中', '2人', 'に', '似', 'てる', 'よ', 'お前', '。', 'ややこしい', '顔', 'し', 'てる', 'わ', '。']]]
"""
# ビルトインモジュール reを使って、余計な記号を取り除く
# 数字も全て0に統一する。
import re
split_mark_pattern=re.compile(r'[\(、。・_;:」…「^)℃(!?,!\?\.\[\]『』【】《》\)*\n<>]')
split_digit=re.compile(r'[\d]+')
# 一行ずつパターンにマッチした記号と数字を処理する関数
def split_marks(x):
try:
x=split_mark_pattern.sub('',x)
x=split_digit.sub('0',x)
return x
except:
return x
# オリジナルのデータ構造に合わせる。
data=[[split_marks(' '.join(ad[0][0]))+'.',split_marks(' '.join(ad[1][0]))+'.'] for ad in append_data]
# 一応確認
"""
data[0]
['どう も ~ 0 丁 拳銃 です よろしく お 願い し ます どう も ビートルズ です .',
'似 てる 似 てる わ お前 は 0 人 中 0人 に 似 てる よ お前 ややこしい 顔 し てる わ .']
"""
続いて検証用データの整形
新たにスクレイピングした
JSONファイルに、
前回あたりの
前処理を施していく。
繰り返しになってしまいますが、 どうせColabにアップロードするので、 Colab上で処理したほうが良いです。
Sudachiぃも別の処理で 使うことになるのでね!
とういうことで、Google MyDriveに 適当なフォルダを作って、 検証用データを適当な名前にして、 アップロードしてくだちぃ。
こちらの append_data.pklまでの 処理が終わったら (勿論別の名前で処理をする)
(例えば「append_valid_data」みたいな感じ)
上のコードを実行して、 同じようなデータ形式にしてくだちぃ。
繰り返しになってしまいますが、 どうせColabにアップロードするので、 Colab上で処理したほうが良いです。
Sudachiぃも別の処理で 使うことになるのでね!
とういうことで、Google MyDriveに 適当なフォルダを作って、 検証用データを適当な名前にして、 アップロードしてくだちぃ。
こちらの append_data.pklまでの 処理が終わったら (勿論別の名前で処理をする)
(例えば「append_valid_data」みたいな感じ)
上のコードを実行して、 同じようなデータ形式にしてくだちぃ。
単語のID化
# オリジナルソースから一つのクラス、一つの関数だけ取り出します。
import h5py
import numpy as np
import os, sys, time, random
# token_listはすべての分かち書きした単語のリスト。
# 今回は訓練用と検証用4つ文用意する。
class TokenList:
def __init__(self, token_list):
self.id2t = ['<PAD>', '<UNK>', '<S>', '</S>'] + token_list
self.t2id = {v:k for k,v in enumerate(self.id2t)}
def id(self, x): return self.t2id.get(x, 1)
def token(self, x): return self.id2t[x]
def num(self): return len(self.id2t)
def startid(self): return 2
def endid(self): return 3
# ID化した単語のベクトルの長さをMaxlengthで指定して、
# 余ったところに<PAD>を埋める。
def pad_to_longest(xs, tokens, max_len=999):
longest = min(len(max(xs, key=len))+2, max_len)
X = np.zeros((len(xs), longest), dtype='int32')
X[:,0] = tokens.startid()
for i, x in enumerate(xs):
x = x[:max_len-2]
for j, z in enumerate(x):
X[i,1+j] = tokens.id(z)
X[i,1+len(x)] = tokens.endid()
return X
# 実際に必要なトークンを作っていく。
# 訓練用
encode_lines=[d[0] for d in data]
decode_lines=[d[1] for d in data]
encwordlist=[enc for encode_line in encode_lines for enc in encode_line.strip().split() if enc!='']
decwordlist=[enc for encode_line in decode_lines for enc in encode_line.strip().split() if enc!='']
itokens=TokenList(encwordlist)
otokens=TokenList(decwordlist)
# 検証用
valid_encode=[vd[0] for vd in valid_data]
valid_decode=[vd[1] for vd in valid_data]
valid_enc_word_list=[enc for encode_line in valid_encode for enc in encode_line.strip().split() if enc!='']
valid_dec_word_list=[enc for encode_line in valid_decode for enc in encode_line.strip().split() if enc!='']
valid_itokens=TokenList(valid_enc_word_list)
valid_otokens=TokenList(valid_dec_word_list)
# ちなみにIDが100以下を表示させるとこうなる
[k for k,v in itokens.t2id.items() if v<=100]
['<PAD>', '<UNK>', '<S>', '</S>', '歯茎']
# 訓練用データと検証用データを作成する。
# 訓練用データの構造を再確認。
"""
data[0]
['どう も ~ 0 丁 拳銃 です よろしく お 願い し ます どう も ビートルズ です .',
'似 てる 似 てる わ お前 は 0 人 中 0人 に 似 てる よ お前 ややこしい 顔 し てる わ .']
"""
# 訓練用データを作成する。
Xs = [[], []]
for ss in data:
for seq, xs in zip(ss, Xs):
xs.append(list(seq.split(' ')))
X, Y = pad_to_longest(Xs[0], itokens, 200), pad_to_longest(Xs[1], otokens, 200)
# 確認。
"""
X[0]
array([ 2, 169397, 169521, 169773, 169734, 121467, 57989, 169728,
169015, 169753, 169619, 169553, 169725, 1, 169397, 169521,
92557, 169728, 1, 3, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0],
dtype=int32)
"""
#検証用データの再確認
"""
valid_data[0]
['おい もう やめろ って 血 と か 出 てる から この 辺 に し とけ って .',
'うっせえ おめえ すっこん でろ よ おめえ は もう 連れ で も 何 で も ねえ から な .']
"""
# 検証用データを作成する。
Xs = [[], []]
for ss in validi_data:
for seq, xs in zip(ss, Xs):
xs.append(list(seq.split(' ')))
Xvalid, Yvalid = pad_to_longest(Xs[0], valid_itokens, 200), pad_to_longest(Xs[1], valid_otokens, 200)
# 確認
"""
Xvalid[0]
array([ 2, 61105, 61360, 54670, 61480, 1, 60043, 61432, 61516,
60064, 61284, 61334, 60914, 48675, 61412, 61526, 58512, 61480,
61531, 3, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0], dtype=int32)
"""
# 一気に確認
"""
print('seq 1 words:', itokens.num())
print('seq 2 words:', otokens.num())
print('train shapes:', X.shape, Y.shape)
print('valid shapes:', Xvalid.shape, Yvalid.shape)
seq 1 words: 169803
seq 2 words: 161226
train shapes: (15533, 200) (15533, 200)
valid shapes: (5470, 200) (5470, 200)
"""
# セッションクラッシュに備えて
# 必要なものは全てセーブしておく。
import dill
# tokens
with open('data/itokens.pkl','wb') as f:
dill.dump(itokens,f)
with open('data/otokens.pkl','wb') as f:
dill.dump(otokens,f)
with open('data/valid_itokens.pkl','wb') as f:
dill.dump(valid_itokens,f)
with open('data/valid_otokens.pkl','wb') as f:
dill.dump(valid_otokens,f)
# data
with open('data/train_data.pkl','wb') as f:
dill.dump(data,f)
with open('data/validation_data.pkl','wb') as f:
dill.dump(valid_data,f)
# train,validation data
with open('data/Xvalid.pkl','wb') as f:
dill.dump(Xvalid,f)
with open('data/Yvalid.pkl','wb') as f:
dill.dump(Yvalid,f)
with open('data/Xtrain.pkl','wb') as f:
dill.dump(X,f)
with open('data/Ytrain.pkl','wb') as f:
dill.dump(Y,f)
Transformer
どうせ学習には時間が掛かります。
一気にコードを載せて、学習中に
ある程度の説明を書いていこうかと思います。
自分も二重に学習中ですので、ちょうどいいかと。
自分も二重に学習中ですので、ちょうどいいかと。
"""
本来であれば、この*で全てをインポートはよろしくないのですが
(名前の衝突が起きてしまう)
例えばmodelというメソッドが存在していて、
ある変数名にmodelをつけて、文字列’Model’を代入してしまったとする。
そうするとインポートしたmodelメソッドは文字列’Model’に上書きされて
それを使うときにエラーを起こす。
ぶっちゃけ面倒くさいので変えないでいます。
あとで修正します。
"""
import random, os, sys
import numpy as np
import tensorflow as tf
from tqdm import tqdm
from keras.models import *
from keras.layers import *
from keras.callbacks import *
from keras.initializers import *
class LayerNormalization(Layer):
def __init__(self, eps=1e-6, **kwargs):
self.eps = eps
super(LayerNormalization, self).__init__(**kwargs)
def build(self, input_shape):
self.gamma = self.add_weight(name='gamma', shape=input_shape[-1:], initializer=Ones(), trainable=True)
self.beta = self.add_weight(name='beta', shape=input_shape[-1:], initializer=Zeros(), trainable=True)
super(LayerNormalization, self).build(input_shape)
def call(self, x):
mean = K.mean(x, axis=-1, keepdims=True)
std = K.std(x, axis=-1, keepdims=True)
return self.gamma * (x - mean) / (std + self.eps) + self.beta
def compute_output_shape(self, input_shape):
return input_shape
# It's safe to use a 1-d mask for self-attention
class ScaledDotProductAttention():
def __init__(self, attn_dropout=0.1):
self.dropout = Dropout(attn_dropout)
def __call__(self, q, k, v, mask): # mask_k or mask_qk
temper = tf.sqrt(tf.cast(tf.shape(k)[-1], dtype='float32'))
attn = Lambda(lambda x:K.batch_dot(x[0],x[1],axes=[2,2])/temper)([q, k]) # shape=(batch, q, k)
if mask is not None:
mmask = Lambda(lambda x:(-1e+9)*(1.-K.cast(x, 'float32')))(mask)
attn = Add()([attn, mmask])
attn = Activation('softmax')(attn)
attn = self.dropout(attn)
output = Lambda(lambda x:K.batch_dot(x[0], x[1]))([attn, v])
return output, attn
class MultiHeadAttention():
# mode 0 - big martixes, faster; mode 1 - more clear implementation
def __init__(self, n_head, d_model, dropout, mode=0):
self.mode = mode
self.n_head = n_head
self.d_k = self.d_v = d_k = d_v = d_model // n_head
self.dropout = dropout
if mode == 0:
self.qs_layer = Dense(n_head*d_k, use_bias=False)
self.ks_layer = Dense(n_head*d_k, use_bias=False)
self.vs_layer = Dense(n_head*d_v, use_bias=False)
elif mode == 1:
self.qs_layers = []
self.ks_layers = []
self.vs_layers = []
for _ in range(n_head):
self.qs_layers.append(TimeDistributed(Dense(d_k, use_bias=False)))
self.ks_layers.append(TimeDistributed(Dense(d_k, use_bias=False)))
self.vs_layers.append(TimeDistributed(Dense(d_v, use_bias=False)))
self.attention = ScaledDotProductAttention()
self.w_o = TimeDistributed(Dense(d_model))
def __call__(self, q, k, v, mask=None):
d_k, d_v = self.d_k, self.d_v
n_head = self.n_head
if self.mode == 0:
qs = self.qs_layer(q) # [batch_size, len_q, n_head*d_k]
ks = self.ks_layer(k)
vs = self.vs_layer(v)
def reshape1(x):
s = tf.shape(x) # [batch_size, len_q, n_head * d_k]
x = tf.reshape(x, [s[0], s[1], n_head, s[2]//n_head])
x = tf.transpose(x, [2, 0, 1, 3])
x = tf.reshape(x, [-1, s[1], s[2]//n_head]) # [n_head * batch_size, len_q, d_k]
return x
qs = Lambda(reshape1)(qs)
ks = Lambda(reshape1)(ks)
vs = Lambda(reshape1)(vs)
if mask is not None:
mask = Lambda(lambda x:K.repeat_elements(x, n_head, 0))(mask)
head, attn = self.attention(qs, ks, vs, mask=mask)
def reshape2(x):
s = tf.shape(x) # [n_head * batch_size, len_v, d_v]
x = tf.reshape(x, [n_head, -1, s[1], s[2]])
x = tf.transpose(x, [1, 2, 0, 3])
x = tf.reshape(x, [-1, s[1], n_head*d_v]) # [batch_size, len_v, n_head * d_v]
return x
head = Lambda(reshape2)(head)
elif self.mode == 1:
heads = []; attns = []
for i in range(n_head):
qs = self.qs_layers[i](q)
ks = self.ks_layers[i](k)
vs = self.vs_layers[i](v)
head, attn = self.attention(qs, ks, vs, mask)
heads.append(head); attns.append(attn)
head = Concatenate()(heads) if n_head > 1 else heads[0]
attn = Concatenate()(attns) if n_head > 1 else attns[0]
outputs = self.w_o(head)
outputs = Dropout(self.dropout)(outputs)
return outputs, attn
class PositionwiseFeedForward():
def __init__(self, d_hid, d_inner_hid, dropout=0.1):
self.w_1 = Conv1D(d_inner_hid, 1, activation='relu')
self.w_2 = Conv1D(d_hid, 1)
self.layer_norm = LayerNormalization()
self.dropout = Dropout(dropout)
def __call__(self, x):
output = self.w_1(x)
output = self.w_2(output)
output = self.dropout(output)
output = Add()([output, x])
return self.layer_norm(output)
class EncoderLayer():
def __init__(self, d_model, d_inner_hid, n_head, dropout=0.1):
self.self_att_layer = MultiHeadAttention(n_head, d_model, dropout=dropout)
self.pos_ffn_layer = PositionwiseFeedForward(d_model, d_inner_hid, dropout=dropout)
self.norm_layer = LayerNormalization()
def __call__(self, enc_input, mask=None):
output, slf_attn = self.self_att_layer(enc_input, enc_input, enc_input, mask=mask)
output = self.norm_layer(Add()([enc_input, output]))
output = self.pos_ffn_layer(output)
return output, slf_attn
class DecoderLayer():
def __init__(self, d_model, d_inner_hid, n_head, dropout=0.1):
self.self_att_layer = MultiHeadAttention(n_head, d_model, dropout=dropout)
self.enc_att_layer = MultiHeadAttention(n_head, d_model, dropout=dropout)
self.pos_ffn_layer = PositionwiseFeedForward(d_model, d_inner_hid, dropout=dropout)
self.norm_layer1 = LayerNormalization()
self.norm_layer2 = LayerNormalization()
def __call__(self, dec_input, enc_output, self_mask=None, enc_mask=None, dec_last_state=None):
if dec_last_state is None: dec_last_state = dec_input
output, slf_attn = self.self_att_layer(dec_input, dec_last_state, dec_last_state, mask=self_mask)
x = self.norm_layer1(Add()([dec_input, output]))
output, enc_attn = self.enc_att_layer(x, enc_output, enc_output, mask=enc_mask)
x = self.norm_layer2(Add()([x, output]))
output = self.pos_ffn_layer(x)
return output, slf_attn, enc_attn
def GetPosEncodingMatrix(max_len, d_emb):
pos_enc = np.array([
[pos / np.power(10000, 2 * (j // 2) / d_emb) for j in range(d_emb)]
if pos != 0 else np.zeros(d_emb)
for pos in range(max_len)
])
pos_enc[1:, 0::2] = np.sin(pos_enc[1:, 0::2]) # dim 2i
pos_enc[1:, 1::2] = np.cos(pos_enc[1:, 1::2]) # dim 2i+1
return pos_enc
def GetPadMask(q, k):
'''
shape: [B, Q, K]
'''
ones = K.expand_dims(K.ones_like(q, 'float32'), -1)
mask = K.cast(K.expand_dims(K.not_equal(k, 0), 1), 'float32')
mask = K.batch_dot(ones, mask, axes=[2,1])
return mask
def GetSubMask(s):
'''
shape: [B, Q, K], lower triangle because the i-th row should have i 1s.
'''
len_s = tf.shape(s)[1]
bs = tf.shape(s)[:1]
mask = K.cumsum(tf.eye(len_s, batch_shape=bs), 1)
return mask
class SelfAttention():
def __init__(self, d_model, d_inner_hid, n_head, layers=6, dropout=0.1):
self.layers = [EncoderLayer(d_model, d_inner_hid, n_head, dropout) for _ in range(layers)]
def __call__(self, src_emb, src_seq, return_att=False, active_layers=999):
if return_att: atts = []
mask = Lambda(lambda x:K.cast(K.greater(x, 0), 'float32'))(src_seq)
x = src_emb
for enc_layer in self.layers[:active_layers]:
x, att = enc_layer(x, mask)
if return_att: atts.append(att)
return (x, atts) if return_att else x
class Decoder():
def __init__(self, d_model, d_inner_hid, n_head, layers=6, dropout=0.1):
self.layers = [DecoderLayer(d_model, d_inner_hid, n_head, dropout) for _ in range(layers)]
def __call__(self, tgt_emb, tgt_seq, src_seq, enc_output, return_att=False, active_layers=999):
x = tgt_emb
self_pad_mask = Lambda(lambda x:GetPadMask(x, x))(tgt_seq)
self_sub_mask = Lambda(GetSubMask)(tgt_seq)
self_mask = Lambda(lambda x:K.minimum(x[0], x[1]))([self_pad_mask, self_sub_mask])
enc_mask = Lambda(lambda x:GetPadMask(x[0], x[1]))([tgt_seq, src_seq])
if return_att: self_atts, enc_atts = [], []
for dec_layer in self.layers[:active_layers]:
x, self_att, enc_att = dec_layer(x, enc_output, self_mask, enc_mask)
if return_att:
self_atts.append(self_att)
enc_atts.append(enc_att)
return (x, self_atts, enc_atts) if return_att else x
class DecoderPerStep(Layer):
def __init__(self, decoder):
super().__init__()
self.layers = decoder.layers
def call(self, inputs):
(x, src_seq, enc_output), tgt_embs = inputs[:3], inputs[3:]
enc_mask = K.cast(K.greater(src_seq, 0), 'float32')
llen = tf.shape(tgt_embs[0])[1]
col_mask = K.cast(K.equal(K.cumsum(K.ones_like(tgt_embs[0], dtype='int32'), axis=1), llen), dtype='float32')
rs = [x]
for i, dec_layer in enumerate(self.layers):
tgt_emb = tgt_embs[i] + x * col_mask
x, _, _ = dec_layer(x, enc_output, enc_mask=enc_mask, dec_last_state=tgt_emb)
rs.append(x)
return rs
def compute_output_shape(self, ishape):
return [ishape[0] for _ in range(len(self.layers)+1)]
class ReadoutDecoderCell(Layer):
def __init__(self, o_word_emb, pos_emb, decoder, target_layer, **kwargs):
self.o_word_emb = o_word_emb
self.pos_emb = pos_emb
self.decoder = decoder
self.target_layer = target_layer
super().__init__(**kwargs)
def call(self, inputs, states, constants, training=None):
(tgt_curr_input, tgt_pos_input, dec_mask), dec_output = states[:3], list(states[3:])
enc_output, enc_mask = constants
time = K.max(tgt_pos_input)
col_mask = K.cast(K.equal(K.cumsum(K.ones_like(dec_mask), axis=1), time), dtype='int32')
dec_mask = dec_mask + col_mask
tgt_emb = self.o_word_emb(tgt_curr_input)
if self.pos_emb: tgt_emb = tgt_emb + self.pos_emb(tgt_pos_input, pos_input=True)
x = tgt_emb
xs = []
cc = K.cast(K.expand_dims(col_mask), dtype='float32')
for i, dec_layer in enumerate(self.decoder.layers):
dec_last_state = dec_output[i] * (1-cc) + tf.einsum('ijk,ilj->ilk', x, cc)
x, _, _ = dec_layer(x, enc_output, dec_mask, enc_mask, dec_last_state=dec_last_state)
xs.append(dec_last_state)
ff_output = self.target_layer(x)
out = K.cast(K.argmax(ff_output, -1), dtype='int32')
return out, [out, tgt_pos_input+1, dec_mask] + xs
class InferRNN(Layer):
def __init__(self, cell, return_sequences=False, go_backwards=False, **kwargs):
if not hasattr(cell, 'call'):
raise ValueError('`cell` should have a `call` method. ' 'The RNN was passed:', cell)
super().__init__(**kwargs)
self.cell = cell
self.return_sequences = return_sequences
self.go_backwards = go_backwards
def compute_output_shape(self, input_shape):
return (input_shape[0], input_shape[1], 1) if self.return_sequences else (input_shape[0], 1)
def __call__(self, inputs, initial_state=None, constants=None, **kwargs):
if initial_state is not None:
kwargs['initial_state'] = initial_state
if constants is not None:
kwargs['constants'] = constants
self._num_constants = len(constants)
return super().__call__(inputs, **kwargs)
def call(self, inputs, mask=None, training=None, initial_state=None, constants=None):
if isinstance(inputs, list):
if self._num_constants is None: initial_state = inputs[1:]
else: initial_state = inputs[1:-self._num_constants]
inputs = inputs[0]
input_shape = K.int_shape(inputs)
timesteps = input_shape[1]
kwargs = {}
def step(inputs, states):
constants = states[-self._num_constants:]
states = states[:-self._num_constants]
return self.cell.call(inputs, states, constants=constants, **kwargs)
last_output, outputs, states = K.rnn(step, inputs, initial_state, constants=constants,
go_backwards=self.go_backwards,
mask=mask, unroll=False, input_length=timesteps)
output = outputs if self.return_sequences else last_output
return output
def decode_batch_greedy(src_seq, encode_model, decode_model, start_mark, end_mark, max_len=128):
enc_ret = encode_model.predict_on_batch(src_seq)
bs = src_seq.shape[0]
target_one = np.zeros((bs, 1), dtype='int32')
target_one[:,0] = start_mark
d_model = decode_model.inputs[-1].shape[-1]
n_dlayers = len(decode_model.inputs) - 3
dec_outputs = [np.zeros((bs, 1, d_model)) for _ in range(n_dlayers)]
ended = [0 for x in range(bs)]
decoded_indexes = [[] for x in range(bs)]
for i in range(max_len-1):
outputs = decode_model.predict_on_batch([target_one, src_seq, enc_ret] + dec_outputs)
new_dec_outputs, output = outputs[:-1], outputs[-1]
for dec_output, new_out in zip(dec_outputs, new_dec_outputs):
dec_output[:,-1,:] = new_out[:,0,:]
dec_outputs = [np.concatenate([x, np.zeros_like(new_out)], axis=1) for x in dec_outputs]
sampled_indexes = np.argmax(output[:,0,:], axis=-1)
for ii, sampled_index in enumerate(sampled_indexes):
if sampled_index == end_mark: ended[ii] = 1
if not ended[ii]: decoded_indexes[ii].append(sampled_index)
if sum(ended) == bs: break
target_one[:,0] = sampled_indexes
return decoded_indexes
def decode_batch_beam_search(src_seq, topk, encode_model, decode_model, start_mark, end_mark, max_len=128, early_stop_mult=5):
N = src_seq.shape[0]
src_seq = src_seq.repeat(topk, 0)
enc_ret = encode_model.predict_on_batch(src_seq)
bs = src_seq.shape[0]
target_one = np.zeros((bs, 1), dtype='int32')
target_one[:,0] = start_mark
d_model = decode_model.inputs[-1].shape[-1]
n_dlayers = len(decode_model.inputs) - 3
dec_outputs = [np.zeros((bs, 1, d_model)) for _ in range(n_dlayers)]
final_results = []
decoded_indexes = [[] for x in range(bs)]
decoded_logps = [0] * bs
lastks = [1 for x in range(N)]
bests = {}
for i in range(max_len-1):
outputs = decode_model.predict_on_batch([target_one, src_seq, enc_ret] + dec_outputs)
new_dec_outputs, output = outputs[:-1], outputs[-1]
for dec_output, new_out in zip(dec_outputs, new_dec_outputs):
dec_output[:,-1,:] = new_out[:,0,:]
dec_outputs = [np.concatenate([x, np.zeros_like(new_out)], axis=1) for x in dec_outputs]
output = np.exp(output[:,0,:])
output = np.log(output / np.sum(output, -1, keepdims=True) + 1e-8)
next_dec_outputs = [x.copy() for x in dec_outputs]
next_decoded_indexes = [1 for x in range(bs)]
for ii in range(N):
base = ii * topk
cands = []
for k, wprobs in zip(range(lastks[ii]), output[base:,:]):
prev = base+k
if len(decoded_indexes[prev]) > 0 and decoded_indexes[prev][-1] == end_mark: continue
ind = np.argpartition(wprobs, -topk)[-topk:]
wsorted = [(k,x) for k,x in zip(ind, wprobs[ind])]
#wsorted = sorted(list(enumerate(wprobs)), key=lambda x:x[-1], reverse=True) # slow
for wid, wp in wsorted[:topk]:
wprob = decoded_logps[prev]+wp
if wprob < bests.get(ii, -1e5) * early_stop_mult: continue
cands.append( (prev, wid, wprob) )
cands.sort(key=lambda x:x[-1], reverse=True)
cands = cands[:topk]
lastks[ii] = len(cands)
for kk, zz in enumerate(cands):
prev, wid, wprob = zz
npos = base+kk
for k in range(len(next_dec_outputs)):
next_dec_outputs[k][npos,:,:] = dec_outputs[k][prev]
target_one[npos,0] = wid
decoded_logps[npos] = wprob
next_decoded_indexes[npos] = decoded_indexes[prev].copy()
next_decoded_indexes[npos].append(wid)
if wid == end_mark:
final_results.append( (ii, decoded_indexes[prev].copy(), wprob) )
if ii not in bests or wprob > bests[ii]: bests[ii] = wprob
if sum(lastks) == 0: break
dec_outputs = next_dec_outputs
decoded_indexes = next_decoded_indexes
return final_results
class Transformer:
def __init__(self, i_tokens, o_tokens, len_limit, d_model=256, \
d_inner_hid=512, n_head=4, layers=2, dropout=0.1, \
share_word_emb=False):
self.i_tokens = i_tokens
self.o_tokens = o_tokens
self.len_limit = len_limit
self.d_model = d_model
self.decode_model = None
self.readout_model = None
self.layers = layers
d_emb = d_model
self.src_loc_info = True
d_k = d_v = d_model // n_head
assert d_k * n_head == d_model and d_v == d_k
self.pos_emb = PosEncodingLayer(len_limit, d_emb) if self.src_loc_info else None
self.emb_dropout = Dropout(dropout)
self.i_word_emb = Embedding(i_tokens.num(), d_emb)
if share_word_emb:
assert i_tokens.num() == o_tokens.num()
self.o_word_emb = i_word_emb
else: self.o_word_emb = Embedding(o_tokens.num(), d_emb)
self.encoder = SelfAttention(d_model, d_inner_hid, n_head, layers, dropout)
self.decoder = Decoder(d_model, d_inner_hid, n_head, layers, dropout)
self.target_layer = TimeDistributed(Dense(o_tokens.num(), use_bias=False))
# using adamax or nadam
# 'adamax'
# 'nadam'
def compile(self, optimizer='adam', active_layers=999):
src_seq_input = Input(shape=(None,), dtype='int32')
tgt_seq_input = Input(shape=(None,), dtype='int32')
src_seq = src_seq_input
tgt_seq = Lambda(lambda x:x[:,:-1])(tgt_seq_input)
tgt_true = Lambda(lambda x:x[:,1:])(tgt_seq_input)
src_emb = self.i_word_emb(src_seq)
tgt_emb = self.o_word_emb(tgt_seq)
if self.pos_emb:
src_emb = add_layer([src_emb, self.pos_emb(src_seq)])
tgt_emb = add_layer([tgt_emb, self.pos_emb(tgt_seq)])
src_emb = self.emb_dropout(src_emb)
enc_output = self.encoder(src_emb, src_seq, active_layers=active_layers)
dec_output = self.decoder(tgt_emb, tgt_seq, src_seq, enc_output, active_layers=active_layers)
final_output = self.target_layer(dec_output)
def get_loss(y_pred, y_true):
y_true = tf.cast(y_true, 'int32')
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y_true, logits=y_pred)
mask = tf.cast(tf.not_equal(y_true, 0), 'float32')
loss = tf.reduce_sum(loss * mask, -1) / tf.reduce_sum(mask, -1)
loss = K.mean(loss)
return loss
def get_accu(y_pred, y_true):
mask = tf.cast(tf.not_equal(y_true, 0), 'float32')
corr = K.cast(K.equal(K.cast(y_true, 'int32'), K.cast(K.argmax(y_pred, axis=-1), 'int32')), 'float32')
corr = K.sum(corr * mask, -1) / K.sum(mask, -1)
return K.mean(corr)
loss = get_loss(final_output, tgt_true)
self.ppl = K.exp(loss)
self.accu = get_accu(final_output, tgt_true)
self.model = Model([src_seq_input, tgt_seq_input], final_output)
self.model.add_loss([loss])
self.model.compile(optimizer, None)
self.model.metrics_names.append('ppl')
self.model.metrics_tensors.append(self.ppl)
self.model.metrics_names.append('accu')
self.model.metrics_tensors.append(self.accu)
def make_src_seq_matrix(self, input_seqs):
if type(input_seqs[0]) == type(''): input_seqs = [input_seqs]
maxlen = max(map(len, input_seqs))
src_seq = np.zeros((len(input_seqs), maxlen+3), dtype='int32')
src_seq[:,0] = self.i_tokens.startid()
for i, seq in enumerate(input_seqs):
for ii, z in enumerate(seq):
src_seq[i,1+ii] = self.i_tokens.id(z)
src_seq[i,1+len(seq)] = self.i_tokens.endid()
return src_seq
def make_readout_decode_model(self, max_output_len=32):
src_seq_input = Input(shape=(None,), dtype='int32')
tgt_start_input = Input(shape=(1,), dtype='int32')
src_seq = src_seq_input
enc_mask = Lambda(lambda x:K.cast(K.greater(x, 0), 'float32'))(src_seq)
src_emb = self.i_word_emb(src_seq)
if self.pos_emb:
src_emb = add_layer([src_emb, self.pos_emb(src_seq)])
src_emb = self.emb_dropout(src_emb)
enc_output = self.encoder(src_emb, src_seq)
tgt_emb = self.o_word_emb(tgt_start_input)
tgt_seq = Lambda(lambda x:K.repeat_elements(x, max_output_len, 1))(tgt_start_input)
rep_input = Lambda(lambda x:K.repeat_elements(x, max_output_len, 1))(tgt_emb)
cell = ReadoutDecoderCell(self.o_word_emb, self.pos_emb, self.decoder, self.target_layer)
final_output = InferRNN(cell, return_sequences=True)(rep_input,
initial_state=[tgt_start_input, K.ones_like(tgt_start_input), K.zeros_like(tgt_seq)] + \
[rep_input for _ in self.decoder.layers],
constants=[enc_output, enc_mask])
final_output = Lambda(lambda x:K.squeeze(x, -1))(final_output)
self.readout_model = Model([src_seq_input, tgt_start_input], final_output)
def decode_sequence_readout_x(self, X, batch_size=32, max_output_len=64):
if self.readout_model is None: self.make_readout_decode_model(max_output_len)
target_seq = np.zeros((X.shape[0], 1), dtype='int32')
target_seq[:,0] = self.o_tokens.startid()
ret = self.readout_model.predict([X, target_seq], batch_size=batch_size, verbose=1)
return ret
def generate_sentence(self, rets, delimiter=''):
sents = []
for x in rets:
end_pos = min([i for i, z in enumerate(x) if z == self.o_tokens.endid()]+[len(x)])
rsent = [*map(self.o_tokens.token, x)][:end_pos]
sents.append(delimiter.join(rsent))
return sents
def decode_sequence_readout(self, input_seqs, delimiter=''):
if self.readout_model is None: self.make_readout_decode_model()
src_seq = self.make_src_seq_matrix(input_seqs)
target_seq = np.zeros((src_seq.shape[0],1), dtype='int32')
target_seq[:,0] = self.o_tokens.startid()
rets = self.readout_model.predict([src_seq, target_seq])
rets = self.generate_sentence(rets, delimiter)
if type(input_seqs[0]) is type('') and len(rets) == 1: rets = rets[0]
return rets
def make_fast_decode_model(self):
src_seq_input = Input(shape=(None,), dtype='int32')
src_emb = self.i_word_emb(src_seq_input)
if self.pos_emb: src_emb = add_layer([src_emb, self.pos_emb(src_seq_input)])
src_emb = self.emb_dropout(src_emb)
enc_output = self.encoder(src_emb, src_seq_input)
self.encode_model = Model(src_seq_input, enc_output)
self.decoder_pre_step = DecoderPerStep(self.decoder)
src_seq_input = Input(shape=(None,), dtype='int32')
tgt_one_input = Input(shape=(1,), dtype='int32')
enc_ret_input = Input(shape=(None, self.d_model))
dec_ret_inputs = [Input(shape=(None, self.d_model)) for _ in self.decoder.layers]
tgt_pos = Lambda(lambda x:tf.shape(x)[1])(dec_ret_inputs[0])
tgt_one = self.o_word_emb(tgt_one_input)
if self.pos_emb: tgt_one = add_layer([tgt_one, self.pos_emb(tgt_pos, pos_input=True)])
dec_outputs = self.decoder_pre_step([tgt_one, src_seq_input, enc_ret_input]+dec_ret_inputs)
final_output = self.target_layer(dec_outputs[-1])
self.decode_model = Model([tgt_one_input, src_seq_input, enc_ret_input]+dec_ret_inputs,
dec_outputs[:-1]+[final_output])
def decode_sequence_fast(self, input_seqs, batch_size=32, delimiter='', verbose=0):
if self.decode_model is None: self.make_fast_decode_model()
src_seq = self.make_src_seq_matrix(input_seqs)
start_mark, end_mark = self.o_tokens.startid(), self.o_tokens.endid()
max_len = self.len_limit
encode_model = self.encode_model
decode_model = self.decode_model
decode_batch = lambda x: decode_batch_greedy(x, encode_model, decode_model, start_mark, end_mark, max_len)
rets = []
rng = range(0, src_seq.shape[0], batch_size)
if verbose and src_seq.shape[0] > batch_size: rng = tqdm(rng, total=len(rng))
for iter in rng:
rets.extend( decode_batch(src_seq[iter:iter+batch_size]) )
rets = [delimiter.join(list(map(self.o_tokens.token, ret))) for ret in rets]
if type(input_seqs[0]) is type('') and len(rets) == 1: rets = rets[0]
return rets
def beam_search(self, input_seqs, topk=5, batch_size=8, length_penalty=1, delimiter='', verbose=0):
if self.decode_model is None: self.make_fast_decode_model()
src_seq = self.make_src_seq_matrix(input_seqs)
start_mark, end_mark = self.o_tokens.startid(), self.o_tokens.endid()
max_len = self.len_limit
encode_model = self.encode_model
decode_model = self.decode_model
decode_batch = lambda x: decode_batch_beam_search(x, topk, encode_model, decode_model,
start_mark, end_mark, max_len)
rets = {}
rng = range(0, src_seq.shape[0], batch_size)
if verbose and src_seq.shape[0] > batch_size: rng = tqdm(rng, total=len(rng))
for iter in rng:
for i, x, y in decode_batch(src_seq[iter:iter+batch_size]):
rets.setdefault(iter+i, []).append( (x, y/np.power(len(x)+1, length_penalty)) )
rets = {x:sorted(ys,key=lambda x:x[-1], reverse=True) for x,ys in rets.items()}
rets = [rets[i] for i in range(len(rets))]
rets = [[(delimiter.join(list(map(self.o_tokens.token, x))), y) for x, y in r] for r in rets]
if type(input_seqs[0]) is type('') and len(rets) == 1: rets = rets[0]
return rets
class PosEncodingLayer:
def __init__(self, max_len, d_emb):
self.pos_emb_matrix = Embedding(max_len, d_emb, trainable=False, \
weights=[GetPosEncodingMatrix(max_len, d_emb)])
def get_pos_seq(self, x):
mask = K.cast(K.not_equal(x, 0), 'int32')
pos = K.cumsum(K.ones_like(x, 'int32'), 1)
return pos * mask
def __call__(self, seq, pos_input=False):
x = seq
if not pos_input: x = Lambda(self.get_pos_seq)(x)
return self.pos_emb_matrix(x)
class AddPosEncoding:
def __call__(self, x):
_, max_len, d_emb = K.int_shape(x)
pos = GetPosEncodingMatrix(max_len, d_emb)
x = Lambda(lambda x:x+pos)(x)
return x
class LRSchedulerPerStep(Callback):
def __init__(self, d_model, warmup=4000):
self.basic = d_model**-0.5
self.warm = warmup**-1.5
self.step_num = 0
def on_batch_begin(self, batch, logs = None):
self.step_num += 1
lr = self.basic * min(self.step_num**-0.5, self.step_num*self.warm)
K.set_value(self.model.optimizer.lr, lr)
add_layer = Lambda(lambda x:x[0]+x[1], output_shape=lambda x:x[0])
# use this because keras may get wrong shapes with Add()([])
class QANet_ConvBlock:
def __init__(self, dim, n_conv=2, kernel_size=7, dropout=0.1):
self.convs = [SeparableConv1D(dim, kernel_size, activation='relu', padding='same') for _ in range(n_conv)]
self.norm = LayerNormalization()
self.dropout = Dropout(dropout)
def __call__(self, x):
for i in range(len(self.convs)):
z = self.norm(x)
if i % 2 == 0: z = self.dropout(z)
z = self.convs[i](z)
x = add_layer([x, z])
return x
class QANet_Block:
def __init__(self, dim, n_head, n_conv, kernel_size, dropout=0.1, add_pos=True):
self.conv = QANet_ConvBlock(dim, n_conv=n_conv, kernel_size=kernel_size, dropout=dropout)
self.self_att = MultiHeadAttention(n_head=n_head, d_model=dim,
d_k=dim//n_head, d_v=dim//n_head,
dropout=dropout, use_norm=False)
self.feed_forward = PositionwiseFeedForward(dim, dim, dropout=dropout)
self.norm = LayerNormalization()
self.add_pos = add_pos
def __call__(self, x, mask):
if self.add_pos: x = AddPosEncoding()(x)
x = self.conv(x)
z = self.norm(x)
z, _ = self.self_att(z, z, z, mask)
x = add_layer([x, z])
z = self.norm(x)
z = self.feed_forward(z)
x = add_layer([x, z])
return x
class QANet_Encoder:
def __init__(self, dim=128, n_head=8, n_conv=2, n_block=1, kernel_size=7, dropout=0.1, add_pos=True):
self.dim = dim
self.n_block = n_block
self.conv_first = SeparableConv1D(dim, 1, padding='same')
self.enc_block = QANet_Block(dim, n_head=n_head, n_conv=n_conv, kernel_size=kernel_size,
dropout=dropout, add_pos=add_pos)
def __call__(self, x, mask):
if K.int_shape(x)[-1] != self.dim:
x = self.conv_first(x)
for i in range(self.n_block):
x = self.enc_block(x, mask)
return x
取り敢えずやってみることの大事さ
誰が言ったか知らないが、
UNIX哲学よろしく、
中島聡氏曰く
でもないが、 何となく心に刻まれている。
こういうのって日本人の文化 考え方の土壌だと不利だよね。。。
いや、お前はただ人のコードパクってるだけやないか!
偉そうにガタガタ抜かしやがって。
あい、とぃまてぇーん。
ということで学習していきますか。
人も学ぶことをやめたら終わりだよ。。。
UNIX哲学よろしく、
中島聡氏曰く
でもないが、 何となく心に刻まれている。
こういうのって日本人の文化 考え方の土壌だと不利だよね。。。
いや、お前はただ人のコードパクってるだけやないか!
偉そうにガタガタ抜かしやがって。
あい、とぃまてぇーん。
ということで学習していきますか。
人も学ぶことをやめたら終わりだよ。。。
# どうしても我慢ならなかったのでここだけAdam指名
from keras.optimizers import Adam
# はいぱーぱらめーたーはクラッシュ注意の慎重作業。
d_model = 64
s2s = Transformer(itokens, otokens, len_limit=24, d_model=d_model, d_inner_hid=128, \
n_head=8, layers=2, dropout=0.1)
# セーブファイル名、modelsのダイレクトリはちゃんと作っておこう!
mfile = 'models/manzai.model.h5'
# オプティマイザー(最適化するもの)はAdam!なんかカッコイイね!
s2s.compile(Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=False))
# 要約が出るよ!
s2s.model.summary()
# これは学習済みの重みぱらめーたーを使って再学習させるときに使います。
# s2s.model.load_weights(mfile)
# 実食!ですが、バッチサイズにご用心
# ちょっと大きくするだけでクラッシュ祭りになる可能性大。
# あと、callbackを使えば、アーリーストッピングや、途中セーブを設定をできるYO!
s2s.model.fit([X, Y], None, batch_size=32, epochs=100, \
validation_data=([Xvalid, Yvalid], None))
# あたくしは終わったあとにセーブするザマス。
s2s.model.save_weights(mfile)
こんな感じで情報が出てきて、

学習結果が出ます。
loss(0に近いほうが良い)は損失値、
acc(1に近いほうが良い)は正解率です。

Predict
はい、ということで巨神兵並の
未完成さで、学習を早々に切り上げ、
遊んでみます。
「腐ってやがる。早すぎたんだ。」
遊んでみます。
「腐ってやがる。早すぎたんだ。」
for _ in range(10):
quest = input('> ')
rets = s2s.beam_search(sudachi_parse(split_marks(quest),tokenizer_obj,mode))
print(rets[0][0])
これで動くかどうか見てみましょう。

次回へ続く
ふう。。。
前回の結果よりも、
大分マシになっているのが
分かると思います。
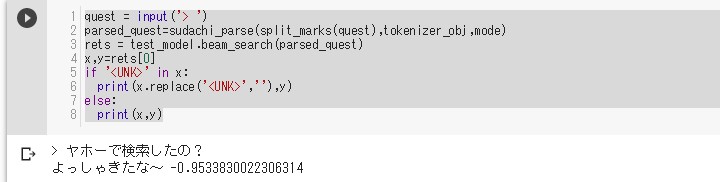
因みにUNK(Unknown) を消すとこんな感じ。
さて、Predictに 使っているメソッドに、
ビームサーチングがちらっと 写っているのが見えたかと思います。
ビームサーチについては 次回また説明します。
一先ず眠りたい。 全部凍らせたまま。 ZEROになろう!(損失値が)
また同じ話題が続いていく。。。
もう真っ白〜
君は、刻の涙を見る。
See You Next Page!
因みにUNK(Unknown) を消すとこんな感じ。
quest = input('> ')
parsed_quest=sudachi_parse(split_marks(quest),tokenizer_obj,mode)
rets = test_model.beam_search(parsed_quest)
x,y=rets[0]
if '<UNK>' in x:
print(x.replace('<UNK>',''),y)
else:
print(x,y)
さて、Predictに 使っているメソッドに、
ビームサーチングがちらっと 写っているのが見えたかと思います。
ビームサーチについては 次回また説明します。
一先ず眠りたい。 全部凍らせたまま。 ZEROになろう!(損失値が)
また同じ話題が続いていく。。。
もう真っ白〜
君は、刻の涙を見る。
See You Next Page!