Published Date : 2019年5月28日7:41
Deep Manzai Part 3
前回の簡単なあらすじ
文脈
以前、どこかの外国の人達が
日本語の言語処理に挑戦。
日本人のバイトを使って コーパスを集め、
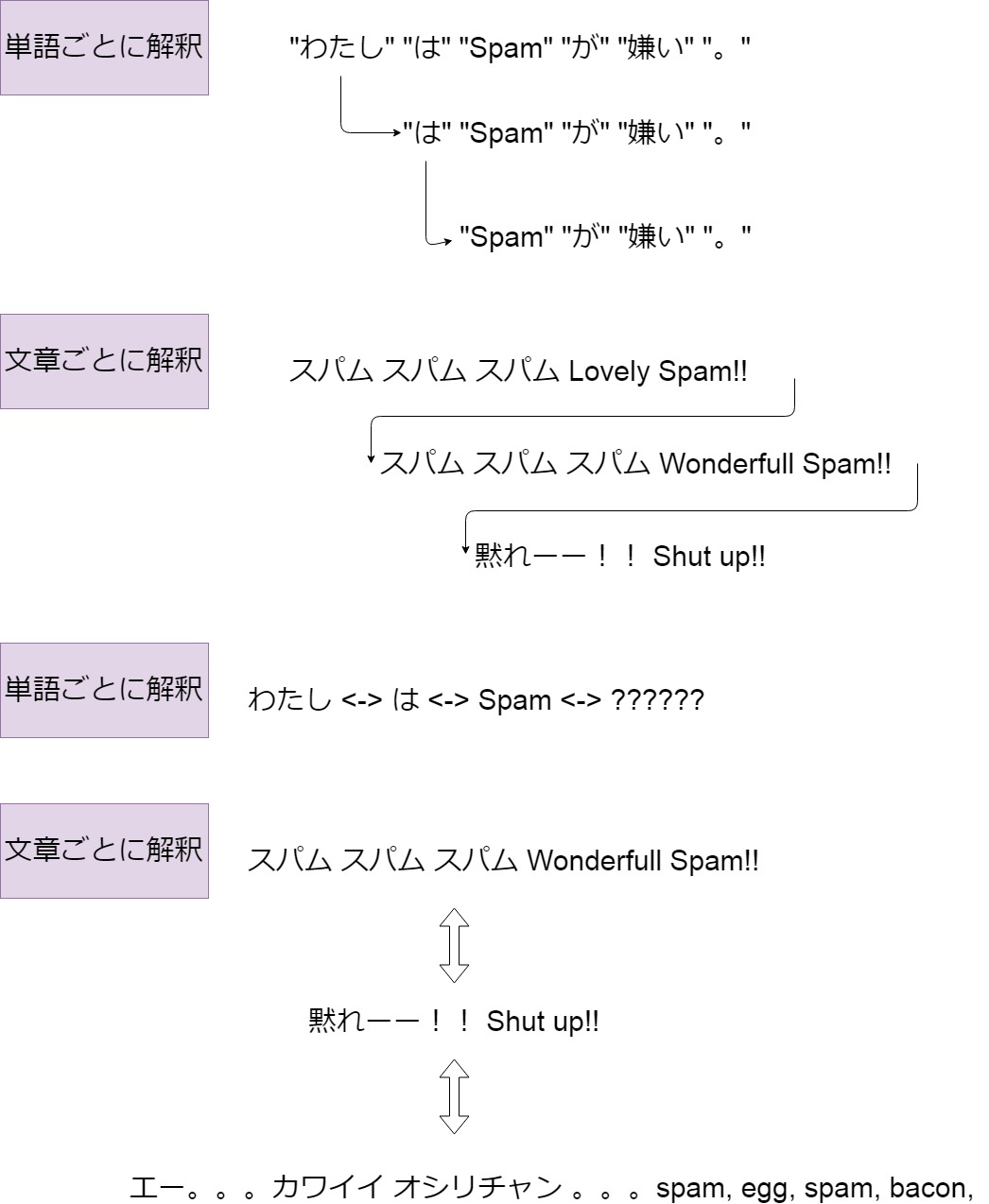
今まで単語ベースで 処理していたものを 文章ベースで解析したところ それなりの精度が出た。
「前後の文脈を考慮した学習が 大事かもね。それにしても日本人は 秘密主義が多くて、日本語の 情報を仕入れるの苦労したよ。 HAHAHA!」
という本人達の談話がセットになった 記事を読んだことを思い出しました。
ですが、その記事が見当たりません...
なにはともあれ、つーことで、 文脈で学習をすれば 何かしら得られるのでは ないかという淡い期待が膨らむ。
そしてこれも30億番煎じ ぐらいやり尽くされている と思いますが、 ひたすらチャレンジ。
日本人のバイトを使って コーパスを集め、
今まで単語ベースで 処理していたものを 文章ベースで解析したところ それなりの精度が出た。
「前後の文脈を考慮した学習が 大事かもね。それにしても日本人は 秘密主義が多くて、日本語の 情報を仕入れるの苦労したよ。 HAHAHA!」
という本人達の談話がセットになった 記事を読んだことを思い出しました。
ですが、その記事が見当たりません...
なにはともあれ、つーことで、 文脈で学習をすれば 何かしら得られるのでは ないかという淡い期待が膨らむ。
そしてこれも30億番煎じ ぐらいやり尽くされている と思いますが、 ひたすらチャレンジ。
gensim
Sudachiぃ復活!
MeCabぅ、Sudachiぃが分かちするんだよ。
つーことでSudachiぃ復活です。
詳しいセットアップと Colaboratory云々はこちらで。
以下、Colaboratoryで Sudachiが使える前提で コードを書いていきます。
つーことでSudachiぃ復活です。
詳しいセットアップと Colaboratory云々はこちらで。
以下、Colaboratoryで Sudachiが使える前提で コードを書いていきます。
# JSONファイルを読み込むためにインポート
import json
# Sudachiぃを使えるようにインポート
from sudachipy import config
from sudachipy import dictionary
from sudachipy import tokenizer
# 必要な設定ファイルを読み込む
with open(config.SETTINGFILE, 'r', encoding='utf-8') as f:
settings = json.load(f)
# 形態素をするためのオブジェクトを作成
tokenizer_obj = dictionary.Dictionary(settings).create()
# 台本の読み込み。
# おそらくダイレクトリの場所は ./src/sudachipy の中なので、
# 2つ前の(../../)ダイレクトリを指定。
with open('../../daihon.json','r',encoding='utf-8') as f:
daihon=json.load(f)
# タイトルを抜き出す。
titles=[d['title'] for d in daihon]
# できるだけ、長い名詞をつなげる。
mode = tokenizer.Tokenizer.SplitMode.C
# Sudachiぃで分かち書きをする関数。
def parse_text_by_line(text,mode):
tokens_list=[]
for line in text:
line=line.replace('Boke: ','').replace('mannaka: ','').replace('Tukkomi: ','')
tokens=tokenizer_obj.tokenize(mode,line)
tokens_list.append([token.surface() for token in tokens])
return tokens_list
# タイトルごと、一行ずつ分かち書きリストにする。すごく時間がかかる。
sudachi_daihon=[parse_text_by_line(d['article'],mode) for d in daihon]
# 時間がかかった分、愛着をもってピックル。
import dill
with open('../../sudachi_daihon.pkl','wb') as f:
dill.dump(sudachi_daihon,f)
# 一行ずつのリストにする。
lines=[' '.join(s) for sd in sudachi_daihon for s in sd]
# あとでgensimで取り扱えるようにするためテキストファイルにする。
for line in lines:
with open('../../lines.txt','a') as f:
f.write(line+'\n')
TaggedLineDocument
TaggedLineDocument
の簡単な説明。
1: 読み込むのは一行が改行された テキストファイル。
2: 分かち書きしとく。
以上。
Let's コーディング。
1: 読み込むのは一行が改行された テキストファイル。
2: 分かち書きしとく。
以上。
Let's コーディング。
# ライブラリインポート
import numpy as np
import pandas as pd
from gensim.models.doc2vec import Doc2Vec
from gensim.models.deprecated.doc2vec import TaggedLineDocument
# 一応の流れ。
sentence_model=TaggedLineDocument('../../lines.txt')
# model = Doc2Vec(alpha=0.025, min_alpha=0.025,dm=1,min_count=10)
# model.build_vocab(sentence_model)
# 簡単短縮
model = Doc2Vec(corpus_file='../../lines.txt',dm=1,vector_size=300,window=20,min_count=10,workers=6)
# トレーニング開始。
model.train(sentence_model,epochs=20,total_examples=len(lines))
# セーーーブ!!!
model.save('sentence_model.model')
# 試してみる
radom_choice=np.random.choice(len(lines))
for i,m in enumerate(model.docvecs.most_similar(radom_choice)):
print('*********************************************************************************')
print(f'original line: {lines[radom_choice]} and indices is : {radom_choice}')
print(f'similar top {i+1} is : {lines[m[0]]} and indices is : {m[0]} and similar is : {m[1]}')
print('*********************************************************************************')
print('*********************************************************************************')
if radom_choice!=0 or random_choice!=len(lines):
print(f'original line before: {lines[radom_choice-1]} and indices is : {radom_choice-1}')
print()
print(f'original line after: {lines[radom_choice+1]} and indices is : {radom_choice+1}')
print('\nNext\n')

ちゃんとできてる?
小分け
例のごとく、
「ボケ」「ツッコミ」「真ん中」 に分けます。
「ボケ」「ツッコミ」「真ん中」 に分けます。
# ボケと(トリオの場合にはmannakaがいる)ツッコミのセリフを分ける。
import re
boke_lines=[]
for d in daihon:
for line in d['article']:
try:
boke_lines.append(re.search(r'Boke:[^\n]+',line).group().replace('Boke: ',''))
except:
pass
mannaka_lines=[]
for d in daihon:
for line in d['article']:
try:
mannaka_lines.append(re.search(r'mannaka:[^\n]+',line).group().replace('mannaka: ',''))
except:
pass
tukkomi_lines=[]
for d in daihon:
for line in d['article']:
try:
tukkomi_lines.append(re.search(r'Tukkomi:[^\n]+',line).group().replace('Tukkomi: ',''))
except:
pass
# テキストファイルに保存。
for boke in boke_lines:
with open('../../boke_lines.txt','a') as f:
f.write(boke+'\n')
for mannaka in mannaka_lines:
with open('../../mannaka_lines.txt','a') as f:
f.write(mannaka+'\n')
for tukkomi in tukkomi_lines:
with open('../../tukkomi_lines.txt','a') as f:
f.write(tukkomi+'\n')
# それぞれDoc2Vecを使い学習。
boke_sentence=TaggedLineDocument('../../boke_lines.txt')
mannaka_sentence=TaggedLineDocument('../../mannaka_lines.txt')
tukkomi_sentence=TaggedLineDocument('../../tukkomi_lines.txt')
boke_model = Doc2Vec(corpus_file='../../boke_lines.txt',dm=1,vector_size=300,window=20,min_count=10,workers=6)
mannaka_model = Doc2Vec(corpus_file='../../mannaka_lines.txt',dm=1,vector_size=300,window=20,min_count=10,workers=6)
tukkomi_model = Doc2Vec(corpus_file='../../tukkomi_lines.txt',dm=1,vector_size=300,window=20,min_count=10,workers=6)
boke_model.save('../../boke_model.model')
mannaka_model.save('../../mannaka_model.model')
tukkomi_model.save('../../tukkomi_model.model')
# 試してみる
radom_choice=np.random.choice(len(tukkomi_lines))
for i,m in enumerate(tukkomi_model.docvecs.most_similar(radom_choice)):
print('*********************************************************************************')
print(f'original line: {tukkomi_lines[radom_choice]} and indices is : {radom_choice}')
print(f'similar top {i+1} is : {tukkomi_lines[m[0]]} and indices is : {m[0]} and similar is : {m[1]}')
print('*********************************************************************************')
print('*********************************************************************************')
if radom_choice!=0 or random_choice!=len(tukkomi_lines):
print(f'original line before: {tukkomi_lines[radom_choice-1]} and indices is : {radom_choice-1}')
print()
print(f'original line after: {tukkomi_lines[radom_choice+1]} and indices is : {radom_choice+1}')
print('\nNext\n')
こんな感じ

# さらに遊ぶ
random_choice_tukkomi=np.random.choice(len(tukkomi_lines))
random_choice_boke=np.random.choice(len(boke_lines))
tukkomi_line=tukkomi_lines[random_choice_tukkomi]
boke_line=boke_lines[random_choice_boke]
for i,m in enumerate(tukkomi_model.docvecs.most_similar(random_choice_tukkomi)):
if i==0:
print(tukkomi_lines[m[0]])
for i,m in enumerate(boke_model.docvecs.most_similar(random_choice_boke)):
if i==0:
print(boke_lines[m[0]])
print()
print(tukkomi_line)
print(boke_line)
print(tukkomi_lines[random_choice_tukkomi+1])
こんな感じ

次回へ続く
まあ時間がないので
駆け足適当に書いてます。
あまり真に受けないように。
次回は以前Kerasでやったことを、 文章ベースにすり替えるだけです。
どうなることやら。
See You Next Page!
次回は以前Kerasでやったことを、 文章ベースにすり替えるだけです。
どうなることやら。
See You Next Page!