Published Date : 2019年5月26日18:31
Deep Manzai Part 2 〜 後半戦 〜
前回の簡単なあらすじ
続き
| 1 | データ収集(Data Scraping) |
|---|---|
| 2 | 前処理(Preprocessing) |
| 3 | 分析(Analyizing) |
| 4 | Build Neural Network |
| 5 | Word2Vecを使う |
| 6 | LSTMによる文章生成 |
まとめて行う
前回の前処理で、気づく。
多分これ一度、文章生成 までやってから、
前処理のやり直しをして、 調整していったほうが いいのではないだろうか。と。
つーことで、 全て終わりまでやった後、
必要そうな前処理をして やり直す流れに変えます。
多分これ一度、文章生成 までやってから、
前処理のやり直しをして、 調整していったほうが いいのではないだろうか。と。
つーことで、 全て終わりまでやった後、
必要そうな前処理をして やり直す流れに変えます。
Neural Network
これからLSTMによる
文章生成などを 行っていきますが、
ニューラルネットワーク については、 簡単な概念しか説明しません。
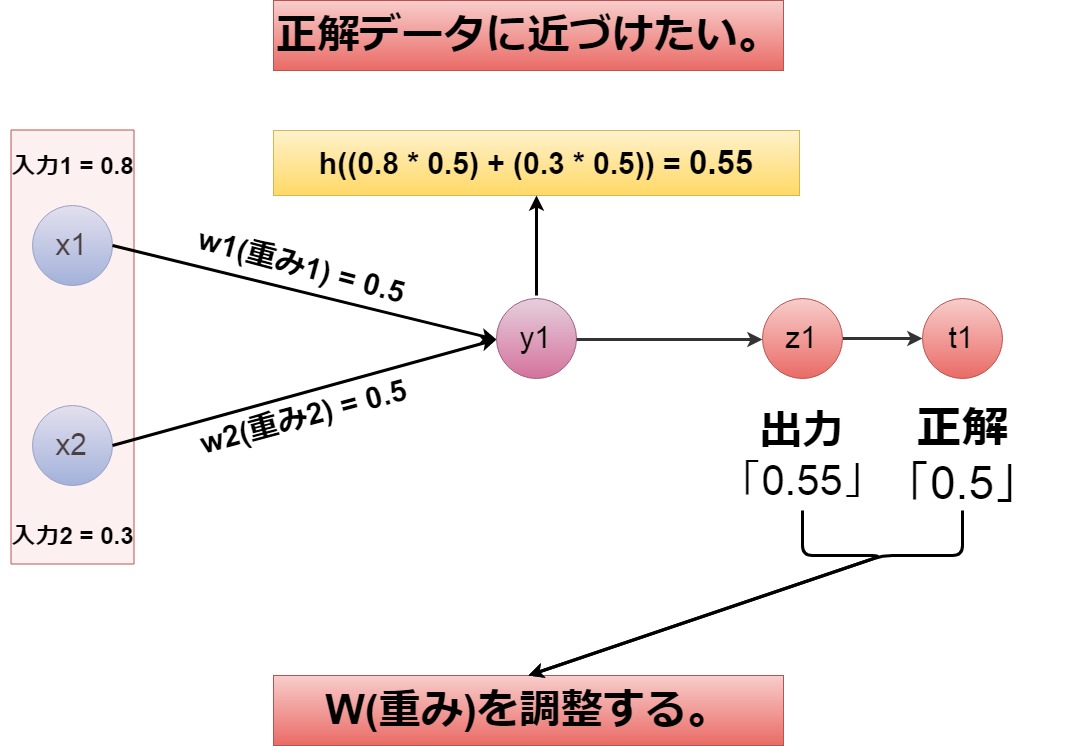
上の画像の説明が ニューラルネットワークを 組むことの本質だと 勝手に考えています。
つまり、最適なウェイト (重み)で
最適な解が 得られるようにすること。
至ってシンプルだと思います。
文章生成などを 行っていきますが、
ニューラルネットワーク については、 簡単な概念しか説明しません。
上の画像の説明が ニューラルネットワークを 組むことの本質だと 勝手に考えています。
つまり、最適なウェイト (重み)で
最適な解が 得られるようにすること。
至ってシンプルだと思います。
誤差逆伝播法と勾配降下法
では最適な重みを
計算するには
どうすればいいのか。
ここで、 勾配降下法が出てくる。
勾配降下法を 簡単に説明すると、
現在の出力値と 教師データが近い場合は、 出力値との誤差が小さくなる。
それ元に値を調べていく。
そして、どの方向に進めば 一番誤差が少ない値を 見つけることができるのかを 導くため、
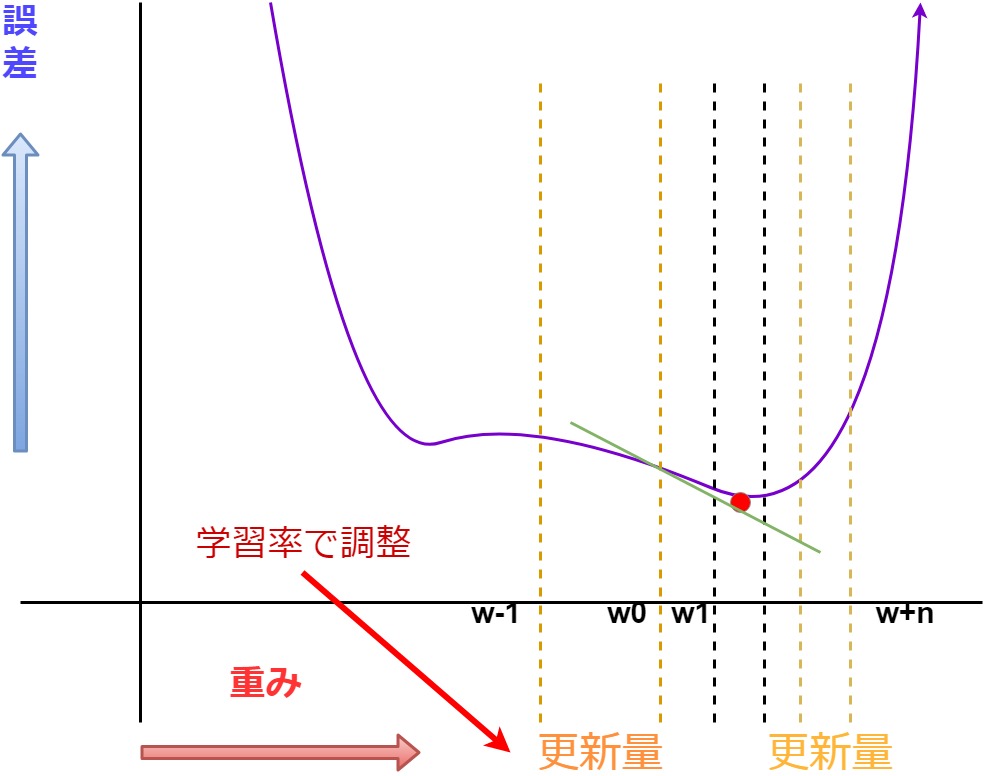
更新量という幅を決める。
更新量の範囲で 現在の誤差と重みを 微分して接線の傾きが 正か負かを見て、
誤差が減る方向に 重みの値を更新していく。
このときの更新量の幅が 重要になります。
何故なら、誤差のグラフは 「U」の文字のような 曲線になっており、 一番下の部分、
つまり、接線が水平に近くなる 箇所が一番誤差が少ない場所 になるので、
その手前で止まる、 もしくは通り過ぎた位置から 計算を行うと最小値が 見つからなくなってしまう。
その幅を決定付けるのが、 学習率(Learning Rate)になる。
そして、勾配降下法の 説明で出てきた「微分」
これが「誤差逆伝播法」 になります。
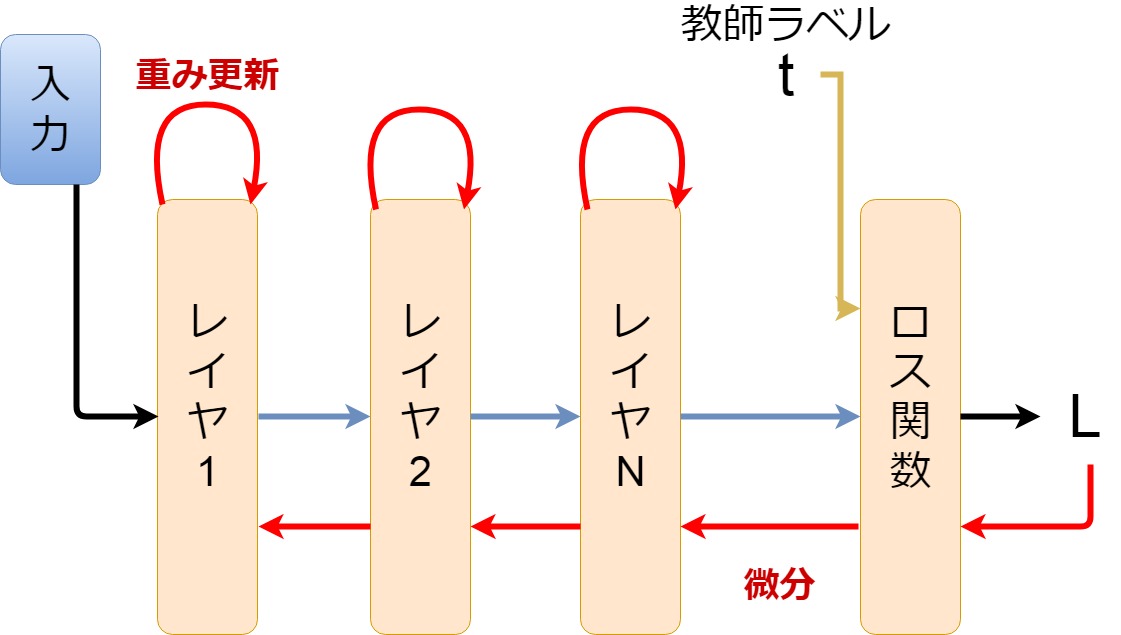
ニューラルネットワークの 層を幾つも重ね、 教師データと出力の 比較を行い、
何度もニューラルネットワーク を行き来して、
最適解となる重み (データの重要度)を求め、
このセットをまた繰り返し、 入力値に対して、 正解であろう出力値を導き出す。
ニューラルネットワーク内 の組み合わせ、 損失関数などの 組み合わせなどを決めて、
所謂「学習」を行っていきます。
以上。 超超超、簡単に。
超超超超簡単に。 ニューラルネットワークと ディープラーニングを 説明しました。
ちなみに内容は こちらの本を参考にしました。

ゼロから作るDeep Learning ❷ ―自然言語処理編
Deep Learningで自然言語処理を 1からやってみたいかたはお勧めです。
Numpyとか基本的な ライブラリしか使いませんので、 基礎的な部分がみっちり身につきます。
ここで、 勾配降下法が出てくる。
勾配降下法を 簡単に説明すると、
現在の出力値と 教師データが近い場合は、 出力値との誤差が小さくなる。
それ元に値を調べていく。
そして、どの方向に進めば 一番誤差が少ない値を 見つけることができるのかを 導くため、
更新量という幅を決める。
更新量の範囲で 現在の誤差と重みを 微分して接線の傾きが 正か負かを見て、
誤差が減る方向に 重みの値を更新していく。
このときの更新量の幅が 重要になります。
何故なら、誤差のグラフは 「U」の文字のような 曲線になっており、 一番下の部分、
つまり、接線が水平に近くなる 箇所が一番誤差が少ない場所 になるので、
その手前で止まる、 もしくは通り過ぎた位置から 計算を行うと最小値が 見つからなくなってしまう。
その幅を決定付けるのが、 学習率(Learning Rate)になる。
そして、勾配降下法の 説明で出てきた「微分」
これが「誤差逆伝播法」 になります。
ニューラルネットワークの 層を幾つも重ね、 教師データと出力の 比較を行い、
何度もニューラルネットワーク を行き来して、
最適解となる重み (データの重要度)を求め、
このセットをまた繰り返し、 入力値に対して、 正解であろう出力値を導き出す。
ニューラルネットワーク内 の組み合わせ、 損失関数などの 組み合わせなどを決めて、
所謂「学習」を行っていきます。
以上。 超超超、簡単に。
超超超超簡単に。 ニューラルネットワークと ディープラーニングを 説明しました。
ちなみに内容は こちらの本を参考にしました。
ゼロから作るDeep Learning ❷ ―自然言語処理編
Deep Learningで自然言語処理を 1からやってみたいかたはお勧めです。
Numpyとか基本的な ライブラリしか使いませんので、 基礎的な部分がみっちり身につきます。
レッツコーディング
さてさて、
頭がこんがらがってきましたので、
コードを書いてすっきりしようZE!
まずは前回の下準備から 参りましょう!
コードを書いてすっきりしようZE!
まずは前回の下準備から 参りましょう!
# まずグーグルドライブをマウント
from google.colab import drive
drive.mount('/content/drive')
"""
Go to this URL in a browser: https://accounts.google.com/o/oauth2/auth?client_id=hogehogehogehogehoge...................
Enter your authorization code:
[ここにコードを入力してエンターキー]
"""
# JSONファイルをアップロードした場所に移動。
# マイドライブ内に適当なフォルダを作ってそこにJSONファイルをおいてくだちぃ。
cd /content/drive/My Drive/data
# ライブラリインポート
import pandas as pd
import json
import numpy as np
# jsonファイルの読み込み。
with open('./daihon.json','r',encoding='utf-8') as f:
daihon=json.load(f)
それではセリフを
形態素解析してから、
データフレームに
直していくことにします。
それでは、nagisa をインストールして 使っていきましょう。
それでは、nagisa をインストールして 使っていきましょう。
import re
import nagisa
import pandas as pd
import dill
# タイトルと芸名をまとめる。
titles=[d['title'] for d in daihon]
names=[t.split('「')[0] for t in titles]
# 分析に不要だと思われる記号類を取り除く準備
# 全体用
remove_words_all=lambda x: x.replace('Boke: ','').replace('mannaka: ','').replace('Tukkomi: ','').replace('?','').replace('。','').replace('!','').replace('…','').replace('…。','').replace('!?','').replace('「','').replace('」','').replace('【','').replace('】','').replace('『','').replace('』','').replace('・・・','').replace('~','').replace('(','').replace(')','').replace('、','')
# 分割用
remove_words=lambda x: x.replace('?','').replace('。','').replace('!','').replace('…','').replace('…。','').replace('!?','').replace('「','').replace('」','').replace('【','').replace('】','').replace('『','').replace('』','').replace('・・・','').replace('~','').replace('(','').replace(')','').replace('、','')
# スクレイピングしたJSONファイルから台本のセリフのみを抜き出し、1行ずつ改行でつなげ、一つの文字列にする。
scripts=list('\n'.join(remove_words_all(lines) for lines in d['article']) for d in daihon)
# 分割用
div_scripts=list('\n'.join(remove_words(lines) for lines in d['article']) for d in daihon)
# ボケと(トリオの場合にはmannakaがいる)ツッコミのセリフを分ける。
boke_lines=list(b.replace('Boke: ','') for b in [''.join(re.findall(r'Boke:[^\n]+\n',s)) for s in div_scripts])
mannaka_lines=list(b.replace('mannaka: ','') for b in [''.join(re.findall(r'mannaka:[^\n]+\n',s)) for s in div_scripts])
tukkomi_lines=list(b.replace('Tukkomi: ','') for b in [''.join(re.findall(r'Tukkomi:[^\n]+\n',s)) for s in div_scripts])
# 分かち書きする際に、例えば「四千頭身」が「四千」と「頭身」に分かれてしまうのを防ぐ。
# もう少し、シングルワードを加えていく。
# 台本をみながら独断と偏見で、しかもこれでも全体の2%という凶悪さ。
single_word=['どうも','ザ・バーディーズ','サッカーワールドカップ','サッカーW杯','お願い','お願いします','すいません','ありがとうございます',
'すごいっすね','でね','このまま','あのね','だから','80代','しょうもな','しょうもない','4人','かなと','やんか','なるんよ','たんかな','やないか',
'へんように','のよ','んやけど','てへんよ','やけに','おかえりなさい','タッちゃん','したはっ','くるんかーい','きたやん','いらん','とって','カリスマ美容師',
'美容師','なるほどな','ほんなら','ヘアスタイル','かしこまりました','いらっしゃいませ','木村拓哉','福士蒼汰','ベリーショート','モト冬樹','えっえっ','ショートカット',
'はやってる','モト冬樹','いや','すいません','全体的','だから','お赤飯','整髪料','ねん','これ','もうええわ','どうもありがとうございました','お姉ちゃん',
'よい子','めちゃくちゃ','数十倍','距離感','奇跡的','えいえい','んっ','えい','ダンスパーティー','神様','洋食屋','東京Walker','オムライス','温暖化',
'ポケットティッシュ','1回','ひょうたん島','お父さん','1か月','ちょっ','ちょっと','お金','お笑い','40年','ピン芸','2009年','M-1グランプリ','M-1',
'トップバッター','審査委員長','島田紳助','何回','6回','2012年','北野演芸館','ビートたけし','1年半','誰','医学部','国家試験','漫才師','自動車学校','学科',
'8回','9回','通り','三つ編み','オギャ~','14~15歳','25周年','関西弁','東京都','大阪府','通天閣','人前','スカイツリー','トテトテ','どっか','最先端',
'全問正解','1問','親しき中にも礼儀あり','こんにゃく','おじさん','与太小僧','他の人','お化け','メリーさん','一人称','貴様','びびって','女の人','肝の玉',
'エンドレスリピート','最先端','マジ卍','十二ひとえ','12枚','かごかい','いとをかし','コロ助','懐メロ','秋の田のかりほ','1つ','元カノ','ありがとうございました','2階',
'600','何度','気のせい','お手下げ','ドコドコドコドン','ブサイク','不細工','マックシェイク','失礼しま~す','ペチペチ星','5歳','週5','罰ゲーム','ペチンコ屋',
'パチンコ屋','ペチペチクイズ','10回','ホヤァ~ン','ペチペチダンス','だって','一回','一等','二等','3回','5年間','ジャスティン・ビーバー','よろしくお願いします','コロコロコミック','おなら']
# くっつける。
names=names+single_word
# 分かち書きができるように準備
nagisa_tagger=nagisa.Tagger(single_word_list=names)
# 分かち書きして、データフレームに直す下準備の関数
def nagisa_parse(text,nagisa_tagger):
text=text.split('\n')
wakati_list=[nagisa_tagger.tagging(t) for t in text]
wakati_words=[wakati.words for wakati in wakati_list]
wakati_postags=[wakati.postags for wakati in wakati_list]
wakati_zip=[list(map(list,zip(w,wakati_postags[i]))) for i,w in enumerate(wakati_words)]
wakati_comb=[j for z in wakati_zip for j in z]
return wakati_comb
# 分かち書き 全体Ver
wakati_comb=[nagisa_parse(s,nagisa_tagger) for s in scripts]
# 分かち書き 各役割ごとVer
boke_wakati_comb=[nagisa_parse(s,nagisa_tagger) for s in boke_lines]
mannaka_wakati_comb=[nagisa_parse(s,nagisa_tagger) for s in mannaka_lines]
tukkomi_wakati_comb=[nagisa_parse(s,nagisa_tagger) for s in tukkomi_lines]
# キーをタイトルに、バリューをデータフレームにした辞書にする。
wakati_dfs_dict=dict((titles[i],pd.DataFrame(w,columns=['words','postags'])) for i,w in enumerate(wakati_comb))
# 役割ごと
# これはタイトル数と合わないので普通にデータフレームする
boke_wakati_dfs_dict=list(pd.DataFrame(w,columns=['words','postags']) for w in boke_wakati_comb)
mannaka_wakati_dfs_dict=list(pd.DataFrame(w,columns=['words','postags']) for w in mannaka_wakati_comb)
tukkomi_wakati_dfs_dict=list(pd.DataFrame(w,columns=['words','postags']) for w in tukkomi_wakati_comb)
# 次からすぐ取り出せるようにピックル化しておく。
with open('wakati_dfs_dict.pkl','wb') as f:
dill.dump(wakati_dfs_dict,f)
with open('boke_wakati_dfs_dict.pkl','wb') as f:
dill.dump(boke_wakati_dfs_dict,f)
with open('mannaka_wakati_dfs_dict.pkl','wb') as f:
dill.dump(mannaka_wakati_dfs_dict,f)
with open('tukkomi_wakati_dfs_dict.pkl','wb') as f:
dill.dump(tukkomi_wakati_dfs_dict,f)
# 中身を見る
wakati_dfs_dict[titles[0]]
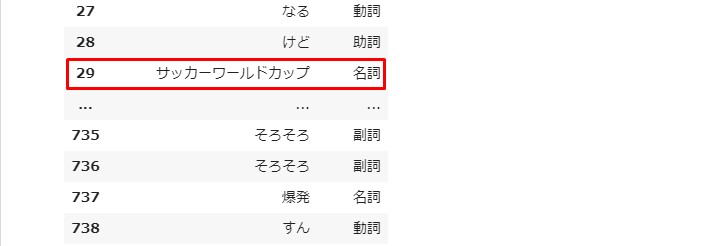
全て名詞になってるっぽいけど、
コロコロコミック、
一つにまとめて欲しい言葉が ちゃんと纏まっている。
このまま一気に文章生成まで突っ走ります。
コードはこの人のサイト を丸写しです。
Keras勉強しなきゃな。。。
とにかく、この人に 最高級のENJOY感謝です。
コード コード コード
import tensorflow as tf import random import numpy.random as nr import sys import h5py import keras import math from keras.layers.core import Activation from keras.layers.core import Dense from keras.layers.core import Dropout from keras.layers.core import Flatten from keras.layers.core import Masking from keras.models import Sequential from keras.layers import Input from keras.models import Model from keras.layers.recurrent import SimpleRNN from keras.layers.recurrent import LSTM from keras.layers.embeddings import Embedding from keras.callbacks import EarlyStopping from keras.callbacks import ReduceLROnPlateau from keras.layers.normalization import BatchNormalization from keras.initializers import glorot_uniform from keras.initializers import uniform from keras.initializers import orthogonal from keras.initializers import TruncatedNormal from keras.optimizers import RMSprop from keras import regularizers from keras.constraints import maxnorm, non_neg from keras.utils.data_utils import get_file from keras.utils import np_utils # 一行のNumpy配列に直す。 mat=np.concatenate([np.array(wakati_dfs_dict[title]['words'].tolist()) for title in titles]) # 単語を全て一意の値に直す。 # setは重複しているワードを一つにまとめてくれる。 words = sorted(list(set(mat))) # 単語がキーで、インデックスがバリューの辞書。 word_indices = dict((w, i) for i, w in enumerate(words)) # インデックスがキーで、単語がバリューの辞書。 indices_word = dict((i, w) for i, w in enumerate(words))
# 単語IDでトレーニングデータと教師データを作っていく。
mat_urtext = np.zeros((len(mat), 1), dtype=int)
for i in range(0, len(mat)):
if mat[i] in word_indices :
if word_indices[mat[i]] != 0 : # 0パディング対策
mat_urtext[i, 0] = word_indices[mat[i]]
else :
mat_urtext[i, 0] = len(words)
data = []
target = []
len_seq = len(mat_urtext)-maxlen
for i in range(0, len_seq):
data.append(mat_urtext[i:i+maxlen, :])
target.append(mat_urtext[i+maxlen, :])
x = np.array(data).reshape(len(data), maxlen, 1)
t = np.array(target).reshape(len(data), 1)
# 元データを訓練用と評価用に分割しない
z = list(zip(x, t))
nr.seed(12345)
nr.shuffle(z) # シャッフル
x, t = zip(*z)
x = np.array(x).reshape(len(data), maxlen, 1)
t = np.array(t).reshape(len(data), 1)
print(x.shape, t.shape)
x_train = x
t_train = t
x_train = np.array(data).reshape(len(data), maxlen, 1)
t_train = np.array(target).reshape(len(data), 1)
print(x_train.shape, t_train.shape)
# 予測用クラス生成。
# ロス関数は二値交差エントロピー(Binary Crossentropy)。
# 最適化するためのアルゴリズム、optimizerはRMSprop。
# RMSpropはAdaGradの改善版。
# 学習率が0に十分近くなってしまった次元に関しては、
# まだ坂があってもほとんど更新されなくなってしまうことがある。
# その改善策として提案されたのがRMSprop。
class Prediction :
def __init__(self, maxlen, n_hidden, input_dim, vec_dim, output_dim):
self.maxlen = maxlen
self.n_hidden = n_hidden
self.input_dim = input_dim
self.output_dim = output_dim
self.vec_dim = vec_dim
def create_model(self):
model = Sequential()
print('#3')
model.add(Embedding(self.input_dim, self.vec_dim, input_length=self.maxlen, trainable=True,
embeddings_initializer=uniform(seed=20170719)))
model.add(BatchNormalization(axis=-1))
print('#4')
model.add(Masking(mask_value=0, input_shape=(self.maxlen, self.vec_dim)))
model.add(LSTM(self.n_hidden, batch_input_shape=(None, self.maxlen, self.vec_dim),
kernel_initializer=glorot_uniform(seed=20170719),
recurrent_initializer=orthogonal(gain=1.0, seed=20170719)
))
print('#5')
model.add(BatchNormalization(axis=-1))
print('#6')
model.add(Dense(self.output_dim, activation='sigmoid', use_bias=True,
kernel_initializer=glorot_uniform(seed=20170719)))
model.compile(loss="binary_crossentropy", optimizer="RMSprop", metrics=['binary_accuracy'])
return model
def train(self, x_train, t_train, batch_size, epochs, emb_param) :
early_stopping = EarlyStopping(monitor='loss', patience=4, verbose=1)
print('#2', t_train.shape)
model = self.create_model()
print('#7')
model.fit(x_train, t_train, batch_size=batch_size, epochs=epochs, verbose=1,
shuffle=True, callbacks=[early_stopping], validation_split=0.0)
return model
# 頻度別に予測クラスを作る。
# 頻度分類用
class Prediction_freq :
def __init__(self, maxlen, n_hidden, input_dim, vec_dim, output_dim):
self.maxlen = maxlen
self.n_hidden = n_hidden
self.input_dim = input_dim
self.output_dim = output_dim
self.vec_dim = vec_dim
#self.t_dim = t_dim
def create_model(self):
model = Sequential()
print('#3')
model.add(Embedding(self.input_dim, self.vec_dim, input_length=self.maxlen))
model.add(BatchNormalization(axis=-1))
print('#4')
model.add(Masking(mask_value=0, input_shape=(self.maxlen, self.vec_dim)))
model.add(LSTM(self.n_hidden, batch_input_shape=(None, self.maxlen, self.vec_dim)))
print('#5')
model.add(BatchNormalization(axis=-1))
print('#6')
model.add(Dense(self.output_dim, activation='sigmoid'))
return model
# 単語推定用
class Prediction_words :
def __init__(self, maxlen, n_hidden, input_dim, vec_dim, output_dim):
self.maxlen = maxlen
self.n_hidden = n_hidden
self.input_dim = input_dim
self.vec_dim = vec_dim
self.output_dim = output_dim
def create_model(self):
model = Sequential()
print('#3')
model.add(Embedding(self.input_dim, self.vec_dim, input_length=self.maxlen, trainable=True,
embeddings_initializer=uniform(seed=20170719)))
model.add(BatchNormalization(axis=-1))
print('#4')
model.add(Masking(mask_value=0, input_shape=(self.maxlen, self.vec_dim)))
model.add(LSTM(self.n_hidden, batch_input_shape=(None, self.maxlen, self.vec_dim)))
print('#5')
model.add(BatchNormalization(axis=-1))
print('#6')
model.add(Dense(self.output_dim, activation='softmax'))
return model
n_upper = 400000 # 学習対象単語の出現頻度上限
n_split = 300 # 分類しきい値
n_lower = 0 # 学習対象単語の出現頻度下限
n_pattern = 0
vec_dim = 400
epochs = 31
batch_size = 200
input_dim = len(words)+1
output_dim = 1
n_hidden = int(vec_dim*1.5) # 隠れ層の次元
prediction = Prediction(maxlen, n_hidden, input_dim, vec_dim, output_dim)
emb_param = 'param_classify_by_freq_'+str(n_pattern)+'_'+str(n_lower)+'_'+str(n_split)+'_'+str(n_upper)+'.hdf5' # パラメーター名
print(emb_param)
row = x_train.shape[0]
x_train = x_train.reshape(row, maxlen)
model = prediction.train(x_train, t_train, batch_size, epochs, emb_param)
model.save_weights(emb_param) # 学習済みパラメーターセーブ
score = model.evaluate(x_train, t_train, batch_size=batch_size, verbose=1)
print("score:", score)
vec_dim = 400
epochs = 100
batch_size = 200
input_dim = len(words)+1
#unk_dim = len(words_unk)+1
output_dim = input_dim
n_sigmoid = 1
n_hidden = int(vec_dim*1.5) # 隠れ層の次元
# 頻度分類用
prediction_freq = Prediction_freq(maxlen, n_hidden, input_dim, vec_dim, n_sigmoid)
print('頻度分類用ニューラルネット_0活性化')
model_classify_freq_0 = prediction_freq.create_model()
print('頻度分類用ニューラルネット_1活性化')
model_classify_freq_1 = prediction_freq.create_model()
print('頻度分類用ニューラルネット_2活性化')
model_classify_freq_2 = prediction_freq.create_model()
print('頻度分類用ニューラルネット_3活性化')
model_classify_freq_3 = prediction_freq.create_model()
print('頻度分類用ニューラルネット_4活性化')
model_classify_freq_4 = prediction_freq.create_model()
print('頻度分類用ニューラルネット_5活性化')
model_classify_freq_5 = prediction_freq.create_model()
print()
# 単語予測用
prediction_words = Prediction_words(maxlen, n_hidden, input_dim, vec_dim, output_dim)
print('単語分類用ニューラルネット(0_10)活性化')
model_words_0_10 = prediction_words.create_model()
print('単語分類用ニューラルネット(10-28)活性化')
model_words_10_28 = prediction_words.create_model()
print('単語分類用ニューラルネット(28-100)活性化')
model_words_28_100 = prediction_words.create_model()
print('単語分類用ニューラルネット(100-300)活性化')
model_words_100_300 = prediction_words.create_model()
print('単語分類用ニューラルネット(300-2000)活性化')
model_words_300_2000 = prediction_words.create_model()
print('単語分類用ニューラルネット(2000-15000)活性化')
model_words_2000_15000 = prediction_words.create_model()
print('単語分類用ニューラルネット(15000-400000)活性化')
model_words_15000_400000 = prediction_words.create_model()
print()
# パラメーターセーブ
print('頻度分類用ニューラルネット_0パラメーターセーブ')
model_classify_freq_0.save_weights('param_classify_by_freq_0_0_300_400000.hdf5')
print('頻度分類用ニューラルネット_1パラメーターセーブ')
model_classify_freq_1.save_weights('param_classify_by_freq_1_0_28_300.hdf5')
print('頻度分類用ニューラルネット_2パラメーターセーブ')
model_classify_freq_2.save_weights('param_classify_by_freq_2_0_10_28.hdf5')
print('頻度分類用ニューラルネット_3パラメーターセーブ')
model_classify_freq_3.save_weights('param_classify_by_freq_3_28_100_300.hdf5')
print('頻度分類用ニューラルネット_4パラメーターセーブ')
model_classify_freq_4.save_weights('param_classify_by_freq_4_300_2000_400000.hdf5')
print('頻度分類用ニューラルネット_5パラメーターセーブ')
model_classify_freq_5.save_weights('param_classify_by_freq_5_2000_15000_400000.hdf5')
print()
print('単語分類用ニューラルネット(0-10)パラメーターセーブ')
model_words_0_10.save_weights('param_words_0_0_10.hdf5')
print('単語分類用ニューラルネット(10-28)パラメーターセーブ')
model_words_10_28.save_weights('param_words_1_10_28.hdf5')
print('単語分類用ニューラルネット(28-100)パラメーターセーブ')
model_words_28_100.save_weights('param_words_2_28_100.hdf5')
print('単語分類用ニューラルネット(100-300)パラメーターセーブ')
model_words_100_300.save_weights('param_words_3_100_300.hdf5')
print('単語分類用ニューラルネット(300-2000)パラメーターセーブ')
model_words_300_2000.save_weights('param_words_4_300_2000.hdf5')
print('単語分類用ニューラルネット(2000-15000)パラメーターセーブ')
model_words_2000_15000.save_weights('param_words_5_2000_15000.hdf5')
print('単語分類用ニューラルネット(15000-400000)パラメーターセーブ')
model_words_15000_400000.save_weights('param_words_6_15000_400000.hdf5')
print()
n_init = 6000
# 単語
x_validation = x_train[n_init, :, :]
x_validation = x_validation.T
row = x_validation.shape[0] # 評価データ数
x_validation = x_validation.reshape(row, maxlen)
text_gen = '' # 生成テキスト
for i in range(0, maxlen) :
text_gen += indices_word[x_validation[0, i]]
print(text_gen)
print()
# 正解データ
text_correct = ''
for j in range(0, 4) :
x_correct = x_train[n_init+j*maxlen, :, :]
x_correct = x_correct.T
x_correct = x_correct.reshape(row, maxlen)
for i in range(0, maxlen) :
text_correct += indices_word[x_correct[0, i]]
print('正解')
print(text_correct)
print()
"""
THE 過学習
# 生成
でもいいあれ公文書だから書き換えちゃいけないわけでも安倍さんも大変安倍さん大ピンチだよだって支持率がどんどん落ちちゃってるからこれだけじゃないからね安倍
# 正解
でもいいあれ公文書だから書き換えちゃいけないわけでも安倍さんも大変安倍さん大ピンチだよだって支持率がどんどん落ちちゃってるからこれだけじゃないからね安倍ない話言うてあげてええ~すべらない話あれ絶対おもろいあるやろ1個か2個あるやん関西人はすべらない話言うてあげて言うてあげていいからて歌を歌いながらケーキを持ってくるやつああ~全部言ってしまったオーケーですどこがだよいきます天使のような悪魔のなぜマッチのミッドナイト・シャッフルをこのも食ってろ誠に残念ですが審査の結果あなたにお金を貸すことはできません返していただきますじゃあさよならもう1回やり直そう私達まだやって行けそうな
Epoch 1/31
611722/611722 [==============================] - 352s 576us/step - loss: 0.0041 - binary_accuracy: 1.0000 <ーー
Epoch 2/31
611722/611722 [==============================] - 350s 572us/step - loss: 1.0006e-07 - binary_accuracy: 1.0000
Epoch 3/31
611722/611722 [==============================] - 354s 578us/step - loss: 1.0000e-07 - binary_accuracy: 1.0000
Epoch 4/31
611722/611722 [==============================] - 351s 574us/step - loss: 1.0000e-07 - binary_accuracy: 1.0000
Epoch 5/31
611722/611722 [==============================] - 350s 572us/step - loss: 1.0000e-07 - binary_accuracy: 1.0000
Epoch 6/31
611722/611722 [==============================] - 350s 572us/step - loss: 1.0000e-07 - binary_accuracy: 1.0000
Epoch 7/31
611722/611722 [==============================] - 349s 571us/step - loss: 1.0000e-07 - binary_accuracy: 1.0000 <ーー
Epoch 00007: early stopping
611722/611722 [==============================] - 98s 160us/step
score: [1.0000001537946446e-07, 1.0] <ーー
"""
# 応答文生成
for k in range (0, 100) :
# 単語予測
# 300
ret_0 = model_classify_freq_0.predict(x_validation, batch_size=batch_size, verbose=0) # 評価結果
ret_0 = ret_0.reshape(row, n_sigmoid)
flag_0 = ret_0[0, 0]
# 最大値インデックス
if flag_0 < 0.5 : # 300未満
ret_1 = model_classify_freq_1.predict(x_validation, batch_size=batch_size, verbose=0) # 評価結果
ret_1 = ret_1.reshape(row, n_sigmoid)
flag_1 = ret_1[0, 0]
if flag_1 < 0.5 : # 28未満
ret_2 = model_classify_freq_2.predict(x_validation, batch_size=batch_size, verbose=0) # 評価結果
ret_2 = ret_2.reshape(row, n_sigmoid)
flag_2 = ret_2[0, 0]
if flag_2< 0.5 : # 10未満
pred_freq = 0
ret = model_words_0_10.predict(x_validation, batch_size=batch_size, verbose=0)
else : # 10以上28未満
pred_freq = 1
ret = model_words_10_28.predict(x_validation, batch_size=batch_size, verbose=0)
else : # 28以上
ret_3 = model_classify_freq_3.predict(x_validation, batch_size=batch_size, verbose=0) # 評価結果
ret_3 = ret_3.reshape(row, n_sigmoid)
flag_3 = ret_3[0, 0]
if flag_3 < 0.5 : # 28以上100未満
pred_freq = 2
ret = model_words_28_100.predict(x_validation, batch_size=batch_size, verbose=0)
else : # 100以上300未満
pred_freq = 3
ret = model_words_100_300.predict(x_validation, batch_size=batch_size, verbose=0)
else : # 300以上
ret_4 = model_classify_freq_4.predict(x_validation, batch_size=batch_size, verbose=0) # 評価結果
ret_4 = ret_4.reshape(row, n_sigmoid)
flag_4 = ret_4[0, 0]
if flag_4 < 0.5 : # 300以上2000未満
pred_freq = 4
ret = model_words_300_2000.predict(x_validation, batch_size=batch_size, verbose=0)
else : # 2000以上
ret_5 = model_classify_freq_5.predict(x_validation, batch_size=batch_size, verbose=0) # 評価結果
ret_5 = ret_5.reshape(row, n_sigmoid)
flag_5 = ret_5[0, 0]
if flag_5 < 0.5 : # 2000以上15000未満
pred_freq = 5
ret = model_words_2000_15000.predict(x_validation, batch_size=batch_size, verbose=0)
else : # 15000以上
pred_freq = 6
ret = model_words_15000_400000.predict(x_validation, batch_size=batch_size, verbose=0)
ret_word = ret.argmax(1)[0]
print(pred_freq, '\t', indices_word[ret_word])
text_gen += indices_word[ret_word] # 生成文字を追加
x_validation[0, 0:maxlen-1] = x_validation[0, 1:maxlen]
x_validation[0, maxlen-1] = ret_word # 1文字シフト
print()
print(text_gen)
"""
1 ショショーゴ
4 あっかわいい
4 エキゾチック
4 expres
4 至る所
4 至る所
3 ドレス
3 う~んう
3 悲
1 手焼け
4 クールズ
6 下げる
6 場面
5 折半
5 重く
5 当たらん
3 茶色
2 デッデケデデデ
3 取り消す
5 らしい
6 起き上がる
6 プププ
6 情勢
5 無理やわ
4 可愛
0 合え
1 与太小僧
1 完熟フレッシュ
4 ニシバヤシ
0 ガ~ン
0 流れだし
1 トコトコ
5 面長
2 もらわん
2 まず~い
2 送り返し
0 空前
5 詳し
5 あん
5 マクダーナー
6 巻き込ま
1 田渕
4 言い渡さ
6 巻き込ま
3 オオカミ
3 音出
3 よけれ
3 追っ掛け
2 せきこむ
2 キャラメルマシーン
2 すめ
4 楳図
6 何渡し
5 ゲロゲロゲロゲロ
5 まっけ
3 フコイダン
5 話ずれ
5 話ずれ
5 揃え
5 親やる
4 イ
4 引き取る
4 引き取る
4 女性
4 アンタツッコミ
4 すげえ入っ
4 すげえ入っ
4 無口
4 よこせ
4 無口
4 ネコゼ
4 グルグルグルグル
4 島
6 握り心地
4 鳥羽
4 多心
4 まくっ
5 目つぶらさ
6 タチカルタス
0 反
0 ベニア
2 歯用
0 とく
0 湯掛け
0 牛角
6 とけ
5 くそっ
6 踏み込ん
2 好謙
4 あらえっ
4 はるばる
4 痛み
5 なしいら
4 卑怯
4 鑑賞
4 どうせろくな
4 詰め込ん
4 ためらい
1 経ち
4 包ま
"""
メモリクラッシュ
台本すべてだとメモリが足らず
クラッシュすることがある。
一応その対策として、 小分けにした「ボケ用」 「ツッコミ用」などを 小分けにして学習させる。
一応その対策として、 小分けにした「ボケ用」 「ツッコミ用」などを 小分けにして学習させる。
# ここを変える。
# 一行のNumpy配列に直す。
mat=np.concatenate(np.array([np.array(df['words'].tolist()) for df in boke_wakati_dfs_dict]))
# 単語を全て一意の値に直す。
# setは重複しているワードを一つにまとめてくれる。
words = sorted(list(set(mat)))
# 単語がキーで、インデックスがバリューの辞書。
word_indices = dict((w, i) for i, w in enumerate(words))
# インデックスがキーで、単語がバリューの辞書。
indices_word = dict((i, w) for i, w in enumerate(words))
words = sorted(list(set(mat)))
cnt = np.zeros(len(words))
print('total words:', len(words))
word_indices = dict((w, i) for i, w in enumerate(words)) # 単語をキーにインデックス検索
indices_word = dict((i, w) for i, w in enumerate(words)) # インデックスをキーに単語を検索
# 単語の出現数をカウント
for j in range(0, len(mat)):
cnt[word_indices[mat[j]]] += 1
# 出現頻度の少ない単語を「UNK」で置き換え
# 未知語一覧
words_unk = []
for k in range(0, len(words)):
if cnt[k]<=3 :
words_unk.append(words[k])
words[k] = 'UNK'
# words_unkはUNKに変換された単語のリスト
print('低頻度語数:', len(words_unk))
words = sorted(list(set(words)))
print('total words:', len(words))
# 単語をキーにインデックス検索
word_indices = dict((w, i) for i, w in enumerate(words))
# インデックスをキーに単語を検索
indices_word = dict((i, w) for i, w in enumerate(words))
maxlen = 40 # 入力語数
mat_urtext = np.zeros((len(mat), 1), dtype=int)
for i in range(0, len(mat)):
#row = np.zeros(len(words), dtype=np.float32)
if mat[i] in word_indices : # 出現頻度の低い単語のインデックスをUNKのそれに置き換え
if word_indices[mat[i]] != 0 : # 0パディング対策
mat_urtext[i, 0] = word_indices[mat[i]]
else :
mat_urtext[i, 0] = len(words)
else:
mat_urtext[i, 0] = word_indices['UNK']
print(mat_urtext.shape)
# 単語の出現数をもう一度カウント:UNK置き換えでwords_indeicesが変わっているため
cnt = np.zeros(len(words)+1)
for j in range(0, len(mat)):
cnt[mat_urtext[j, 0]] += 1
print(cnt.shape)
len_seq = len(mat_urtext)-maxlen
data = []
target = []
for i in range(0, len_seq):
data.append(mat_urtext[i:i+maxlen, :])
target.append(mat_urtext[i+maxlen, :])
x = np.array(data).reshape(len(data), maxlen, 1)
t = np.array(target).reshape(len(data), 1)
z = list(zip(x, t))
# シャッフル
nr.shuffle(z)
x, t = zip(*z)
x = np.array(x).reshape(len(data), maxlen, 1)
t = np.array(t).reshape(len(data), 1)
print(x.shape, t.shape)
# 訓練データ長
n_train = int(len(data)*0.9)
# 元データを訓練用と評価用に分割
x_train, x_validation = np.vsplit(x, [n_train])
# targetを訓練用と評価用に分割
t_train, t_validation = np.vsplit(t, [n_train])
vec_dim = 400
epochs = 100
batch_size = 200
input_dim = len(words)+1
output_dim = input_dim
n_hidden = int(vec_dim*1.5) # 隠れ層の次元
prediction = Prediction(maxlen, n_hidden, input_dim, vec_dim, output_dim)
# パラメーターファイル名
emb_param = 'boke_param_1.hdf5'
row = x_train.shape[0]
x_train = x_train.reshape(row, maxlen)
model = prediction.train(x_train, np_utils.to_categorical(t_train, output_dim), batch_size, epochs)
# 学習済みパラメーターセーブ
model.save_weights(emb_param)
row2 = x_validation.shape[0]
score = model.evaluate(x_validation.reshape(row2, maxlen),
np_utils.to_categorical(t_validation, output_dim), batch_size=batch_size, verbose=1)
print("score:", score)


次回へ続く
非常に学習に
時間がかかりましたが、
できたものは以上です。
次回は ちょっと視点を変えて、 挑戦していきます。
See You Next Page !
できたものは以上です。
次回は ちょっと視点を変えて、 挑戦していきます。
See You Next Page !