Published Date : 2019年10月17日19:39
架空のクラウドソーシング案件に挑戦してみる(3-1)
Try a Fictional Crowdsourcing Deal(3-2)
This blog has an English translation
架空のお仕事をしてみる企画(3-2)です。
It's a project to try a fictitious job(3-2).
仮に自分がフリーランスで、 ある依頼者から適当な仕事を振られてみたら、 果たしてクリアできるのか?といった企画。
If i am a freelance programmer, When a client assigns a suitable job, Can I clear it? That's the plan.
この企画は架空のものですが、日本のクラウドソーシング市場に氾濫しているよくある案件と値段と工数を参考にしてます。
This project is a fictitious one, but it is based on common cases, prices and man-hours flooding the Japanese crowdsourcing market.
取り敢えず前回の続き
For the moment, Let's continue the last time
クラスファイルは作ったので、メインPYと便利な関数群の作成開始。
Now that i have created the class file, we start creatting the mainpy and the useful functions.
ファイル構成は以下の通り
The file structure is as follows
dirctory
site001
data
settings.csv
scripts
collect_utils.py
collect.py
chromedriver.exe
crowler.py
まずはcrawler.pyから作ります。
Let's start with crawler.py.
crawler.py
import argparse
import sys
sys.path.append('.')
from site001.collect import Collect
def crawler_py():
usage = f'usage: {__file__} [-h] url waysnumber'
parser = argparse.ArgumentParser(usage=usage)
parser.add_argument('url', type=str, help="URL you want to crawl")
parser.add_argument('waysnum', type=int, help="Choose between (round trip -> 0) and (one way -> 1)")
opt = parser.parse_args()
base_url = opt.url
ways_num = opt.waysnum
if ways_num == 2:
print('Please make it 1 or 2 for now.')
sys.exit()
collect_ = Collect(base_url, ways_num)
collect_.main()
if __name__=='__main__':
crawler_py()
crawler.pyの説明
crawler.py description
usage = f'usage: {__file__} [-h] url waysnumber'
parser = argparse.ArgumentParser(usage=usage)
parser.add_argument('url', type=str, help="URL you want to crawl")
parser.add_argument('waysnum', type=int, help="Choose between (round trip -> 0) and (one way -> 1)")
opt = parser.parse_args()
base_url = opt.url
ways_num = opt.waysnum
if ways_num != 0 and ways_num != 1:
print('Please make it 1 or 2 for now.')
sys.exit()
コマンドラインから引数としてURL、行き方(数値)を受け取り、必要に応じて使い方の説明をできるようにする。
It takes a URL and choice of one way or round trip(Number) as arguments from the command line and provides instructions on how to use them as needed.
import sys
sys.path.append('.')
これは現在のダイレクトリにPythonパスを通すという意味。こうすることで、自作のモジュールを扱えるようになる。
This means passing the Python path to the current directory. This allows you to work with your own modules.
if ways_num != 0 and ways_num != 1:
print('Please make it 1 or 2 for now.')
sys.exit()
これは周遊に関してはいらないと判断したので、作成しませんでした。 なので、一応の安全弁のようなものです。
I didn't make this because i thought i didn't need it for the excursion. So it's like a safety valve.
collect_ = Collect(base_url, ways_num)
collect_.main()
if __name__=='__main__':
crawler_py()
実際のコンテンツ収集役のインスタンス作成と実行。
Create instance and run the actual content collector.
続いてcollect_utils.pyの作成
Then we create collect_utils.py.
collect_utils.py
import calendar
from datetime import datetime
from datetime import timedelta
import csv
from selenium.webdriver import Chrome,ChromeOptions
def set_web_driver(url):
options = ChromeOptions()
driver_path = "chromedriver.exe"
# 下をコメントアウトすると、ヘッドレスモードで検証できます。
# You can verify in headless mode by commenting out below.
# options.add_argument('--headless')
options.add_argument('--incognito')
# If you are using chromedriver _ binary
# driver = Chrome(options=options)
driver = Chrome(driver_path, options=options)
base_url = url
driver.get(base_url)
return driver
def read_file():
with open('site001/data/settings.csv','r') as f:
reader = csv.DictReader(f)
settings_file = [row for row in reader]
return settings_file
def write_file(file_name, header,contents):
with open(f'site001/data/{file_name}.csv','w',newline='') as f:
writer = csv.DictWriter(f, fieldnames=header)
writer.writeheader()
for c in contents:
writer.writerow(c)
def check_date(date_text):
ymd = date_text.split('/')
if date_text == '':
return False
elif len(ymd) < 3:
return False
else:
try:
nymd = datetime(int(ymd[0]), int(ymd[1]), int(ymd[2]))
ndate = datetime.now()
if nymd < ndate:
return False
elif nymd >= ndate and nymd <= ndate + timedelta(days=333):
return True
else:
return False
except:
return False
def get_date():
today = datetime.today()
week_num, lastday = calendar.monthrange(today.year, today.month)
if today.month == 12:
if today.day == 1:
next_month_day = lastday
else:
next_month_day = today.day - 1
nextmonth = 1
today_year = today.year + 1
else:
if today.day == 1:
next_month_day = lastday
else:
next_month_day = today.day - 1
nextmonth = today.month + 1
today_year = today.year
start = f'{today_year}/{today.month:02d}/{today.day+1:02d}'
end = f'{today_year}/{nextmonth:02d}/{next_month_day+1:02d}'
return start,end
collect_utils.pyの説明
collect_utils.py description
import calendar
from datetime import datetime
from datetime import timedelta
import csv
from selenium.webdriver import Chrome,ChromeOptions
def set_web_driver(url):
options = ChromeOptions()
driver_path = "chromedriver.exe"
# 下をコメントアウトすると、ヘッドレスモードで検証できます。
# You can verify in headless mode by commenting out below.
# options.add_argument('--headless')
options.add_argument('--incognito')
# If you are using chromedriver _ binary
# driver = Chrome(options=options)
driver = Chrome(driver_path, options=options)
base_url = url
driver.get(base_url)
return driver
お馴染みのset_web_driverなので説明は簡潔に。 クロールの準備運動です。
This is the familiar set_web_driver, so the description should be brief. It's a preparatory exercise for crawling.
def read_file():
with open('site001/data/settings.csv','r') as f:
reader = csv.DictReader(f)
settings_file = [row for row in reader]
return settings_file
CSVファイルを辞書形式にして読み込む。
import a CSV file in a dictionary format.
def write_file(file_name, header,contents):
with open(f'site001/data/{file_name}.csv','w',newline='') as f:
writer = csv.DictWriter(f, fieldnames=header)
writer.writeheader()
for c in contents:
writer.writerow(c)
クロールして集めたデータをCSVファイルとして書き込む。
Write crawled data as a CSV file.
def check_date(date_text):
ymd = date_text.split('/')
if date_text == '':
return False
elif len(ymd) < 3:
return False
else:
try:
nymd = datetime(int(ymd[0]), int(ymd[1]), int(ymd[2]))
ndate = datetime.now()
if nymd < ndate:
return False
elif nymd >= ndate and nymd <= ndate + timedelta(days=333):
return True
else:
return False
except:
return False
日付が有効か確認する。 与えられた日付のテキストを分割する。 最初に空文字か長さが足りないかの判定をする。 正しく年月日が揃っていたら、作業日の日付より過去になっていないか、 指定日があまりにも未来過ぎないかの判定をして、真偽値を返す。
Make sure the date is valid. Split text for a given date. First, it is judged whether it is empty or not. If the dates are aligned correctly, it is determined whether the work date is in the past or the specified date is not too late, and a boolean value is returned.
def get_date():
today = datetime.today()
week_num, lastday = calendar.monthrange(today.year, today.month)
if today.month == 12:
if today.day == 1:
next_month_day = lastday
else:
next_month_day = today.day - 1
nextmonth = 1
today_year = today.year + 1
else:
if today.day == 1:
next_month_day = lastday
else:
next_month_day = today.day - 1
nextmonth = today.month + 1
today_year = today.year
start = f'{today_year}/{today.month:02d}/{today.day+1:02d}'
end = f'{today_year}/{nextmonth:02d}/{next_month_day+1:02d}'
return start,end
これは日付が有効でなかった時に発動する関数。 今日の日付を取得して、Python標準搭載のCalenderモジュールでその月の最終日を計算する。 あとは年の計算をして、開始日と終了日に1を足し、Javascriptで扱えるように「/」をエスケープさせた文字列を返してあげる。
This function is invoked when the date is not valid. Get today's date and calculate the last day of the month in the standard Python Calender module. It then calculates the year, adds 1 to the start and end dates, and returns a string escaped with a "/" so Javascript can handle it.
実食
Let it work
準備ができたら、crawler.pyを動かす。
When ready, run crawler.py
dirctory
site001
data
settings.csv
scripts
collect_utils.py
collect.py
chromedriver.exe
crowler.py
python crawler.py https://spamhamspam.spam 1
settings.csvの中身は以下のようになる。
The contents of settings.csv are as follows.
site001/data/settings.csv
dep,des,start,end 新千歳,羽田,, 羽田,新千歳,2019/11/21,2019/12/20
取れたデータの中身は以下のようになる。
Here's what the data looks like.
往復-羽田-新千歳-20191017/10-19(土)_12-20.csv
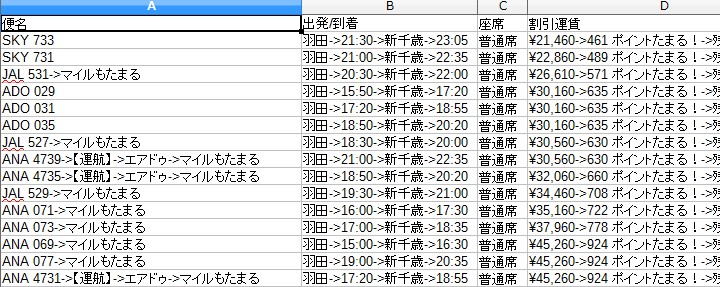
片道-新千歳-羽田-20191017/10-19(土).csv
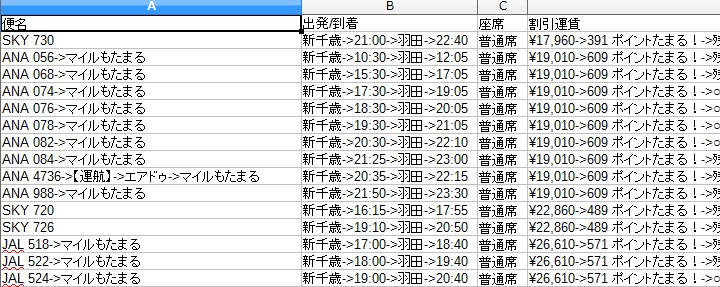
あとは出発時間の並び替えやその他操作できる項目と、周遊の際のスクレイピングの機能の追加は各自好きに実装してくだちぃ。
You can also rearrange your departure times and add other features you can controls. Please implement the additional excrusion scraping function as you like.
次回は残りの5つのサイトのクローラー作成といきたいところですが、めんどくさいので気分次第です。
Next time, I plan to create crawlers for the remaining 5 sites. But it's hard to implement them, so i feel like it will depend on my mood.
See You Next Page!