Published Date : 2019年6月15日13:17
Deep Manzai Part 6 〜 番外編 〜
前回の簡単なあらすじ
前回はseq2seqの
改良版Attentionを使って、
ナイツの漫才限定で、
文章生成をChainerの
コードにて行いました。
コードはこちらの方のブログを そっくり使わせていただきました。 Attention Seq2Seqで対話モデルを実装してみた
改めて最高級のEnjoy感謝です!
コードはこちらの方のブログを そっくり使わせていただきました。 Attention Seq2Seqで対話モデルを実装してみた
改めて最高級のEnjoy感謝です!
若干の修正
さて、前回のモデルを使って
WEBアプリを作ってみましょうか。
と、その前に、 いくつか 「またまた何回目よ!何回目!」 の修正をしていきます。
と、その前に、 いくつか 「またまた何回目よ!何回目!」 の修正をしていきます。
修正点
1: MeCabからSudachiへ
CORESERVERで apt-getが使えないため。
Predictの際、 どのみち分かち書きが必要なため。
同じ分かち書きルールでなければ、 色々都合が悪い。
例えば、 「こんにちは世界。」
これを分かち書きするとして、 「”こんにちは”、”世界”、” 。”」 となったとします。
ー>「”こんにちは”」 ー>「”世界”」
と関連付けした結果が、
「”こんにち” 、”は”、 ”世界”、 ”。”」
ー>「”こんにち”」 ー>「”は”」
このようなケースが 発生する可能性があるため。
2: Dataの形態を変え、全台本を学習。
実は前回の台本では、 Tukkomi「なにかのセリフ」 Tukkomi「また別のセリフ」
と、役割が同じ人が 改行して続けざまに セリフを言うことが 多々発生していた為、
漫才の基本的な流れ 「フリ」ー> 「オチ」ー> 「フォロー」。 を維持できなっかたのです。
そこで、役割が同じ人の セリフは一行にまとめて
ちゃんと一問一答のような 形式に揃えました。
要は「ツッコミ」「ボケ」 「ツッコミ」「ボケ」 と必ず交互になるように 元の台本を整形していきます。
3: 全台本の学習
実は前回のナイツだけの学習だと、 損失値が最適な値付近になっても
数が少ない、 パターンが限られている。
この2つの影響で、 ナイツ漫才の答え合わせ的なことは できるのですが、
まったく未知の言葉への対応が できませんでした。
所謂「過学習」です。
やはりそれを回避するためには、 どうしてもある程度の 会話パターンを網羅した データが必要になってきます。
ということでここ数日間 学習時間とパラメーターの調整 にリソースを割かれていました。 (と言ってもbatch_sizeと batch_column_sizeだけですが)
まあ、ぐだぐだ言ってないで、 コードを書いてきます。
CORESERVERで apt-getが使えないため。
Predictの際、 どのみち分かち書きが必要なため。
同じ分かち書きルールでなければ、 色々都合が悪い。
例えば、 「こんにちは世界。」
これを分かち書きするとして、 「”こんにちは”、”世界”、” 。”」 となったとします。
ー>「”こんにちは”」 ー>「”世界”」
と関連付けした結果が、
「”こんにち” 、”は”、 ”世界”、 ”。”」
ー>「”こんにち”」 ー>「”は”」
このようなケースが 発生する可能性があるため。
2: Dataの形態を変え、全台本を学習。
実は前回の台本では、 Tukkomi「なにかのセリフ」 Tukkomi「また別のセリフ」
と、役割が同じ人が 改行して続けざまに セリフを言うことが 多々発生していた為、
漫才の基本的な流れ 「フリ」ー> 「オチ」ー> 「フォロー」。 を維持できなっかたのです。
そこで、役割が同じ人の セリフは一行にまとめて
ちゃんと一問一答のような 形式に揃えました。
要は「ツッコミ」「ボケ」 「ツッコミ」「ボケ」 と必ず交互になるように 元の台本を整形していきます。
3: 全台本の学習
実は前回のナイツだけの学習だと、 損失値が最適な値付近になっても
数が少ない、 パターンが限られている。
この2つの影響で、 ナイツ漫才の答え合わせ的なことは できるのですが、
まったく未知の言葉への対応が できませんでした。
所謂「過学習」です。
やはりそれを回避するためには、 どうしてもある程度の 会話パターンを網羅した データが必要になってきます。
ということでここ数日間 学習時間とパラメーターの調整 にリソースを割かれていました。 (と言ってもbatch_sizeと batch_column_sizeだけですが)
まあ、ぐだぐだ言ってないで、 コードを書いてきます。
データ改造計画
前回までの行為全体は一体
なんだったのだろうか。
まさにシーシュポスの岩
無念です。
なにはともあれ、データを 整形していきまっしょい。
まさにシーシュポスの岩
無念です。
なにはともあれ、データを 整形していきまっしょい。
# 前前前回あたりのスクレイピングしたJSONファイルを
# colabにアップロードしたら、読み込む。
# 別にこの作業はローカルでやっても無問題(モウマンタイ)。
import json
with open('daihon.json','r',encoding='utf-8') as f:
daihon_json=json.load(f)
# Boke Tukkomi mannaka その他不要な頭の部分をカットする関数。
import re
def check_role(lines):
try:
check_list=[re.search(r'^[^:]+: ',line).group() for line in lines]
if 'Tukkomi: ' in check_list and 'Boke: ' in check_list:
return True
except:
return False
# 役割がかぶる行を探して、一つの行にする関数。
def append_role_line(lines):
# 一番最初にわかりやすい文字を入れたリストを作成。
# この文字はなんでもいい。
list_=['<start>']
# 次の行も見ていくので、すべての行数から1を引いてループさせる。
for i in range(len(lines)-1):
# 役割の文字で分割して、次の判定に使う。
split_role_list=lines[i].split(': ')
split_role_list_next=lines[i+1].split(': ')
# きちんと役割が分けられていれば
# 2個に分割されているので、
# 判定材料に使う。
# 分けられていないならあきらめて、そのままリストに付け足していく。
if len(split_role_list)!=2 and len(split_role_list_next)!=2:
list_.append(split_role_list[0])
# きちんと役割が分けられていれば
else:
# 役割だけ抽出
role=split_role_list[0]
role_next=split_role_list_next[0]
# 付け足したリストの最後の行とかぶっていないか判定。
if not list_[-1].endswith(split_role_list[1]):
# かぶってなければ容赦なくアペンド
list_.append(split_role_list[1])
# 一つ目の行と次の行の役割が一緒なら、
if len(split_role_list_next)==2 and role==role_next:
# ほんで、次の行と文がかぶってなければ
if not list_[-1].endswith(split_role_list_next[1]):
# 文字列をくっつける
add_line=list_[-1]+split_role_list_next[1]
# そしてリストに付け足す。
list_[-1]=add_line
# 最終的に出来たリストを返してあげる。
return list_
# 2つの関数を使ってみる。
# 漫才師だけを使うため、タイトルを抽出。
titles=[d['title'] for d in daihon_json if check_role(d['article'])]
# 同じく台本部分を処理。
daihon=[d['article'] for d in daihon_json if check_role(d['article'])]
# 全台本の処理。
# これでも大分絞れてくる。
daihon=[append_role_line(d)[1:] for d in daihon]
# こんな感じ。 daihon[0] # => """ [ 'どうも四千頭身です。お願いします。', 'よろしくお願いします。', '突然なんだけどさ俺結構ね正夢見んのよ。', 'そうなの?どんな夢見るの?', 'ちょっと前になるけどサッカーワールドカップあったじゃない。', 'あったあった。', 'それの日本対コロンビア戦の日に日本がコロンビアに実際の試合どおりの2対1で勝つ夢を見てるの。', 'ホントに?ホントに。', 'ちゃんと香川と大迫が決めてんの。', 'そんなことある?', 'そんなことあるんだって。ビックリするのがさセネガル戦の日もポーランド戦の日もベルギー戦の日もその試合の結果とまったく同じ夢見てんの。', 'ウソだろそんなの。', 'ホントなんだって。', """
# 前回のコードです。
# しゃべくり漫才とされている方々のリストを
# Wikiから拝借して、
# 振り分ける。
import requests
from bs4 import BeautifulSoup
res=requests.get('https://ja.wikipedia.org/wiki/%E6%BC%AB%E6%89%8D%E5%B8%AB%E4%B8%80%E8%A6%A7')
soup=BeautifulSoup(res.content,'lxml')
lis=soup.find_all('li')
manzaishi_list=[]
for li in lis:
try:
manzaishi_list.append(li.a.string)
except:
if li.string.startswith('「現代上方演芸人名鑑」'):
break
else:
manzaishi_list.append(li.string)
manzaishi_indices=[]
import re
for i,title in enumerate(titles):
for manzaishi in manzaishi_list:
try:
if re.search(manzaishi,title):
manzaishi_indices.append(i)
except:
pass
manzaishi_titles=[titles[i] for i in manzaishi_indices]
manzaishi_daihon=[daihon[i] for i in manzaishi_indices]
# エンコーダーに渡す辞書と
# デコーダーに渡す辞書を作成。
# 別に辞書にしなくてもいいけど
# 後々タイトルごと、漫才師ごとに
# 分けて作業したい場合に重宝するかなと
# 自分はしませんでしたが。
encode_seq={}
decode_seq={}
for idx,md in enumerate(manzaishi_daihon):
encode_seq[manzaishi_titles[idx]]=[]
decode_seq[manzaishi_titles[idx]]=[]
for i,m in enumerate(md):
if i%2==0:
encode_seq[manzaishi_titles[idx]].append(m)
else:
decode_seq[manzaishi_titles[idx]].append(m)
# まあ二度手間になりますが、一応テキストファイルとして保存したい人はどうぞ。
for mt in manzaishi_titles:
with open(f'data/manzai_encode/{mt}.txt','w',encoding='utf-8') as f:
f.write('\n'.join(encode_seq[mt]))
with open(f'data/manzai_decode/{mt}.txt','w',encoding='utf-8') as f:
f.write('\n'.join(decode_seq[mt]))
# 僕はピックル!
import dill
for mt in manzaishi_titles:
with open(f'data/manzai_encode/{mt}.pkl','wb',encoding='utf-8') as f:
dill.dump('\n'.join(encode_seq[mt]),f)
with open(f'data/manzai_decode/{mt}.pkl','wb',encoding='utf-8') as f:
dill.dump('\n'.join(decode_seq[mt]),f)
# 呼び出しをかける。
# こっからSudachiぃを使っていくのでColabに移動して
# ファイルをアップロードするか
# ローカルでSudachiぃをセットアップしてくだちぃ。
# テキストファイルバージョンで書いていきます。
# ピックルした人、もしくはそのままローカルで
# Sudachiぃを使う人はコードを適当に変更してくだちぃ
import os
import glob
enc_dir='text/manzai_encode'
dec_dir='text/manzai_decode'
enc_=[]
dec_=[]
for l in sorted(glob.glob(enc_dir+'/*.txt')):
with open(l,'r',encoding='utf-8') as f:
enc_.append(f.readlines())
for l in sorted(glob.glob(dec_dir+'/*.txt')):
with open(l,'r',encoding='utf-8') as f:
dec_.append(f.readlines())
# 以下colabでの作業前提
!cd drive/'My Drive'/data/
# 何故か一度セッションが切れると
# マイドライブにレポジトリが置かれていても
# インストールされていないことになるので
# めんどくさいが
# 一連の儀式を始める。
# 辞書は一度置いてしまえば大丈夫らしい。謎使用。
!pip install -e git+git://github.com/WorksApplications/SudachiPy@develop#egg=SudachiPy
import sys
sys.path.append('src/sudachipy')
import json
from sudachipy import config
from sudachipy import dictionary
from sudachipy import tokenizer
with open(config.SETTINGFILE, 'r', encoding='utf-8') as f:
settings = json.load(f)
# MeCabぅ、やっぱりSudachiぃが分かち書くんだよ!
# 分かち書きしてくれるオブジェクトを作成。
tokenizer_obj = dictionary.Dictionary(settings).create()
# よしなに、単語を分けてくれるモードを指定。
mode = tokenizer.Tokenizer.SplitMode.C
# 分かち書きをする処理を関数にする。
def sudachi_parse(text,tokenizer_obj,mode):
tokens=tokenizer_obj.tokenize(mode,text)
return [token.surface() for token in tokens]
# 分かち書きリストをエンコードようデコードように分ける。
enc_sudachi=[[sudachi_parse(en.replace('\n',''),tokenizer_obj,mode) for en in enc] for enc in enc_]
dec_sudachi=[[sudachi_parse(de.replace('\n',''),tokenizer_obj,mode) for de in dec] for dec in dec_]
# 合体させる。一億年と二千年前から~~あ...たと合体し...。(酷いCMだったね。)
enc_dec=[list(map(list,zip(enc,dec_sudachi[i])))for i,enc_ in enumerate(enc_sudachi)]
# 保存しておくか。
with open('append_data.pkl','wb') as f:
dill.dump(enc_dec,f)
子供チャレンジ
さあ赤ペン先生の添削の時間だ!
ビシバシ文章の間違いを正していくぜ!
覚悟しな!ヒャッハー!
例のごとくこの人の ブログのコードです。
デコーダー部分だけ若干の変更です。
何度も何度も。 っサンキュですっ!!
因みにサンキューです の元ネタはくりぃむしちゅ〜の オールナイトニッポンです。
いつもいつも、さんきゅーです! 斯様に思います。
例のごとくこの人の ブログのコードです。
デコーダー部分だけ若干の変更です。
何度も何度も。 っサンキュですっ!!
因みにサンキューです の元ネタはくりぃむしちゅ〜の オールナイトニッポンです。
いつもいつも、さんきゅーです! 斯様に思います。
from copy import deepcopy
import chainer
import numpy as np
import datetime
from chainer import Chain, Variable, cuda, optimizer, optimizers, serializers
import chainer.functions as F
import chainer.links as L
if chainer.cuda.available and chainer.cuda.cudnn_enabled:
xp = cuda.cupy
else:
xp = np
class DataConverter:
def __init__(self, batch_col_size):
# クラスの初期化
# :param batch_col_size: 学習時のミニバッチ単語数サイズ
self.vocab = {"<eos>":0, "<unknown>": 1} # 単語辞書
self.batch_col_size = batch_col_size
def load(self, data):
# 学習時に、教師データを読み込んでミニバッチサイズに対応したNumpy配列に変換する
# :param data: 対話データ
# 単語辞書の登録
self.vocab = {"<eos>":0, "<unknown>": 1} # 単語辞書を初期化
for d in data:
sentences = [d[0][0], d[1][0]] # 入力文、返答文
for sentence in sentences:
sentence_words = self.sentence2words(sentence) # 文章を単語に分解する
for word in sentence_words:
if word not in self.vocab:
self.vocab[word] = len(self.vocab)
# 教師データのID化と整理
queries, responses = [], []
for d in data:
query, response = d[0][0], d[1][0] # エンコード文、デコード文
queries.append(self.sentence2ids(sentence=query, train=True, sentence_type="query"))
responses.append(self.sentence2ids(sentence=response, train=True, sentence_type="response"))
self.train_queries = xp.vstack(queries)
self.train_responses = xp.vstack(responses)
def sentence2words(self,sentence):
sentence_words = deepcopy(sentence)
sentence_words.append("<eos>")
return sentence_words
def sentence2ids(self, sentence, train=True, sentence_type="query"):
# 文章を単語IDのNumpy配列に変換して返却する
# :param sentence: 文章文字列
# :param train: 学習用かどうか
# :sentence_type: 学習用でミニバッチ対応のためのサイズ補填方向をクエリー・レスポンスで変更するため"query"or"response"を指定
# :return: 単語IDのNumpy配列
ids = [] # 単語IDに変換して格納する配列
sentence_words = self.sentence2words(sentence) # 文章を単語に分解する
for word in sentence_words:
if word in self.vocab: # 単語辞書に存在する単語ならば、IDに変換する
ids.append(self.vocab[word])
else: # 単語辞書に存在しない単語ならば、<unknown>に変換する
ids.append(self.vocab["<unknown>"])
# 学習時は、ミニバッチ対応のため、単語数サイズを調整してNumpy変換する
if train:
if sentence_type == "query": # クエリーの場合は前方にミニバッチ単語数サイズになるまで-1を補填する
while len(ids) > self.batch_col_size: # ミニバッチ単語サイズよりも大きければ、ミニバッチ単語サイズになるまで先頭から削る
ids.pop(0)
ids = xp.array([-1]*(self.batch_col_size-len(ids))+ids, dtype="int32")
elif sentence_type == "response": # レスポンスの場合は後方にミニバッチ単語数サイズになるまで-1を補填する
while len(ids) > self.batch_col_size: # ミニバッチ単語サイズよりも大きければ、ミニバッチ単語サイズになるまで末尾から削る
ids.pop()
ids = xp.array(ids+[-1]*(self.batch_col_size-len(ids)), dtype="int32")
else: # 予測時は、そのままNumpy変換する
ids = xp.array([ids], dtype="int32")
return ids
def ids2words(self, ids):
# 予測時に、単語IDのNumpy配列を単語に変換して返却する
# :param ids: 単語IDのNumpy配列
# :return: 単語の配列
words = [] # 単語を格納する配列
for i in ids: # 順番に単語IDを単語辞書から参照して単語に変換する
words.append(list(self.vocab.keys())[list(self.vocab.values()).index(i)])
return words
class LSTMEncoder(Chain):
def __init__(self, vocab_size, embed_size, hidden_size):
# Encoderのインスタンス化
# :param vocab_size: 使われる単語の種類数
# :param embed_size: 単語をベクトル表現した際のサイズ
# :param hidden_size: 隠れ層のサイズ
super(LSTMEncoder, self).__init__(
xe = L.EmbedID(vocab_size, embed_size, ignore_label=-1),
eh = L.Linear(embed_size, 4 * hidden_size),
hh = L.Linear(hidden_size, 4 * hidden_size)
)
def __call__(self, x, c, h):
# Encoderの計算
# :param x: one-hotな単語
# :param c: 内部メモリ
# :param h: 隠れ層
# :return: 次の内部メモリ、次の隠れ層
e = F.tanh(self.xe(x))
return F.lstm(c, self.eh(e) + self.hh(h))
# Attention Model + LSTMデコーダークラス
class AttLSTMDecoder(Chain):
def __init__(self, vocab_size, embed_size, hidden_size):
# Attention ModelのためのDecoderのインスタンス化
# :param vocab_size: 語彙数
# :param embed_size: 単語ベクトルのサイズ
# :param hidden_size: 隠れ層のサイズ
super(AttLSTMDecoder, self).__init__(
ye = L.EmbedID(vocab_size, embed_size, ignore_label=-1), # 単語を単語ベクトルに変換する層
eh = L.Linear(embed_size, 4 * hidden_size), # 単語ベクトルを隠れ層の4倍のサイズのベクトルに変換する層
hh = L.Linear(hidden_size, 4 * hidden_size), # Decoderの中間ベクトルを隠れ層の4倍のサイズのベクトルに変換する層
fh = L.Linear(hidden_size, 4 * hidden_size), # 順向きEncoderの中間ベクトルの加重平均を隠れ層の4倍のサイズのベクトルに変換する層
bh = L.Linear(hidden_size, 4 * hidden_size), # 順向きEncoderの中間ベクトルの加重平均を隠れ層の4倍のサイズのベクトルに変換する層
he = L.Linear(hidden_size, embed_size), # 隠れ層サイズのベクトルを単語ベクトルのサイズに変換する層
ey = L.Linear(embed_size, vocab_size) # 単語ベクトルを語彙数サイズのベクトルに変換する層
)
def __call__(self, y, c, h, f, b):
# Decoderの計算
# :param y: Decoderに入力する単語
# :param c: 内部メモリ
# :param h: Decoderの中間ベクトル
# :param f: Attention Modelで計算された順向きEncoderの加重平均
# :param b: Attention Modelで計算された逆向きEncoderの加重平均
# :return: 語彙数サイズのベクトル、更新された内部メモリ、更新された中間ベクトル
e = F.tanh(self.ye(y)) # 単語を単語ベクトルに変換
c, h = F.lstm(c, self.eh(e) + self.hh(h) + self.fh(f) + self.bh(b)) # 単語ベクトル、Decoderの中間ベクトル、順向きEncoderのAttention、逆向きEncoderのAttentionを使ってLSTM
t = self.ey(F.tanh(self.he(h))) # LSTMから出力された中間ベクトルを語彙数サイズのベクトルに変換する
return t, c, h
# Attentionモデルクラス
class Attention(Chain):
def __init__(self, hidden_size):
# Attentionのインスタンス化
# :param hidden_size: 隠れ層のサイズ
super(Attention, self).__init__(
fh = L.Linear(hidden_size, hidden_size), # 順向きのEncoderの中間ベクトルを隠れ層サイズのベクトルに変換する線形結合層
bh = L.Linear(hidden_size, hidden_size), # 逆向きのEncoderの中間ベクトルを隠れ層サイズのベクトルに変換する線形結合層
hh = L.Linear(hidden_size, hidden_size), # Decoderの中間ベクトルを隠れ層サイズのベクトルに変換する線形結合層
hw = L.Linear(hidden_size, 1), # 隠れ層サイズのベクトルをスカラーに変換するための線形結合層
)
self.hidden_size = hidden_size # 隠れ層のサイズを記憶
def __call__(self, fs, bs, h):
# Attentionの計算
# :param fs: 順向きのEncoderの中間ベクトルが記録されたリスト
# :param bs: 逆向きのEncoderの中間ベクトルが記録されたリスト
# :param h: Decoderで出力された中間ベクトル
# :return: 順向きのEncoderの中間ベクトルの加重平均と逆向きのEncoderの中間ベクトルの加重平均
batch_size = h.data.shape[0] # ミニバッチのサイズを記憶
ws = [] # ウェイトを記録するためのリストの初期化
sum_w = Variable(xp.zeros((batch_size, 1), dtype='float32')) # ウェイトの合計値を計算するための値を初期化
# Encoderの中間ベクトルとDecoderの中間ベクトルを使ってウェイトの計算
for f, b in zip(fs, bs):
w = F.tanh(self.fh(f)+self.bh(b)+self.hh(h)) # 順向きEncoderの中間ベクトル、逆向きEncoderの中間ベクトル、Decoderの中間ベクトルを使ってウェイトの計算
w = F.exp(self.hw(w)) # softmax関数を使って正規化する
ws.append(w) # 計算したウェイトを記録
sum_w += w
# 出力する加重平均ベクトルの初期化
att_f = Variable(xp.zeros((batch_size, self.hidden_size), dtype='float32'))
att_b = Variable(xp.zeros((batch_size, self.hidden_size), dtype='float32'))
for f, b, w in zip(fs, bs, ws):
w /= sum_w # ウェイトの和が1になるように正規化
# ウェイト * Encoderの中間ベクトルを出力するベクトルに足していく
att_f += F.reshape(F.batch_matmul(f, w), (batch_size, self.hidden_size))
att_b += F.reshape(F.batch_matmul(b, w), (batch_size, self.hidden_size))
return att_f, att_b
# Attention Sequence to Sequence Modelクラス
class AttSeq2Seq(Chain):
def __init__(self, vocab_size, embed_size, hidden_size, batch_col_size):
# Attention + Seq2Seqのインスタンス化
# :param vocab_size: 語彙数のサイズ
# :param embed_size: 単語ベクトルのサイズ
# :param hidden_size: 隠れ層のサイズ
super(AttSeq2Seq, self).__init__(
f_encoder = LSTMEncoder(vocab_size, embed_size, hidden_size), # 順向きのEncoder
b_encoder = LSTMEncoder(vocab_size, embed_size, hidden_size), # 逆向きのEncoder
attention = Attention(hidden_size), # Attention Model
decoder = AttLSTMDecoder(vocab_size, embed_size, hidden_size) # Decoder
)
self.vocab_size = vocab_size
self.embed_size = embed_size
self.hidden_size = hidden_size
self.decode_max_size = batch_col_size # デコードはEOSが出力されれば終了する、出力されない場合の最大出力語彙数
# 順向きのEncoderの中間ベクトル、逆向きのEncoderの中間ベクトルを保存するためのリストを初期化
self.fs = []
self.bs = []
def encode(self, words, batch_size):
# Encoderの計算
# :param words: 入力で使用する単語記録されたリスト
# :param batch_size: ミニバッチのサイズ
# :return:
# 内部メモリ、中間ベクトルの初期化
c = Variable(xp.zeros((batch_size, self.hidden_size), dtype='float32'))
h = Variable(xp.zeros((batch_size, self.hidden_size), dtype='float32'))
# 順向きのEncoderの計算
for w in words:
c, h = self.f_encoder(w, c, h)
self.fs.append(h) # 計算された中間ベクトルを記録
# 内部メモリ、中間ベクトルの初期化
c = Variable(xp.zeros((batch_size, self.hidden_size), dtype='float32'))
h = Variable(xp.zeros((batch_size, self.hidden_size), dtype='float32'))
# 逆向きのEncoderの計算
for w in reversed(words):
c, h = self.b_encoder(w, c, h)
self.bs.insert(0, h) # 計算された中間ベクトルを記録
# 内部メモリ、中間ベクトルの初期化
self.c = Variable(xp.zeros((batch_size, self.hidden_size), dtype='float32'))
self.h = Variable(xp.zeros((batch_size, self.hidden_size), dtype='float32'))
def decode(self, w):
# Decoderの計算
# :param w: Decoderで入力する単語
# :return: 予測単語
att_f, att_b = self.attention(self.fs, self.bs, self.h)
t, self.c, self.h = self.decoder(w, self.c, self.h, att_f, att_b)
return t
def reset(self):
# インスタンス変数を初期化する
# Encoderの中間ベクトルを記録するリストの初期化
self.fs = []
self.bs = []
# 勾配の初期化
self.zerograds()
def __call__(self, enc_words, dec_words=None, train=True):
# 順伝播の計算を行う関数
# :param enc_words: 発話文の単語を記録したリスト
# :param dec_words: 応答文の単語を記録したリスト
# :param train: 学習か予測か
# :return: 計算した損失の合計 or 予測したデコード文字列
enc_words = enc_words.T
if train:
dec_words = dec_words.T
batch_size = len(enc_words[0]) # バッチサイズを記録
self.reset() # model内に保存されている勾配をリセット
enc_words = [Variable(xp.array(row, dtype='int32')) for row in enc_words] # 発話リスト内の単語をVariable型に変更
self.encode(enc_words, batch_size) # エンコードの計算
t = Variable(xp.array([0 for _ in range(batch_size)], dtype='int32')) # をデコーダーに読み込ませる
loss = Variable(xp.zeros((), dtype='float32')) # 損失の初期化
ys = [] # デコーダーが生成する単語を記録するリスト
# デコーダーの計算
if train: # 学習の場合は損失を計算する
for w in dec_words:
y = self.decode(t) # 1単語ずつをデコードする
t = Variable(xp.array(w, dtype='int32')) # 正解単語をVariable型に変換
loss += F.softmax_cross_entropy(y, t) # 正解単語と予測単語を照らし合わせて損失を計算
return loss
else: # 予測の場合はデコード文字列を生成する
for i in range(self.decode_max_size):
y = self.decode(t)
y = xp.argmax(y.data) # 確率で出力されたままなので、確率が高い予測単語を取得する
ys.append(y)
t = Variable(xp.array([y], dtype='int32'))
if y == 0: # EOSを出力したならばデコードを終了する
break
return ys
さあ、学習の時間だ
EMBED_SIZE = 100
HIDDEN_SIZE = 100
BATCH_SIZE = 3108 # ミニバッチ学習のバッチサイズ数
BATCH_COL_SIZE = 24
EPOCH_NUM = 1000 # エポック数
N = len(data) # 教師データの数
# 教師データの読み込み
data_converter = DataConverter(batch_col_size=BATCH_COL_SIZE) # データコンバーター
data_converter.load(data) # 教師データ読み込み
# 単語数
vocab_size = len(data_converter.vocab)
# モデルの宣言
model = AttSeq2Seq(vocab_size=vocab_size, embed_size=EMBED_SIZE, hidden_size=HIDDEN_SIZE, batch_col_size=BATCH_COL_SIZE)
# model load
# serializers.load_npz('attention_batch3108_bc_24_manzai_model.model', model)
if xp == cuda.cupy:
chainer.cuda.get_device(0).use()
model.to_gpu(0)
#else:
# model.to_cpu()
model.reset()
opt = optimizers.Adam()
opt.setup(model)
opt.add_hook(optimizer.GradientClipping(5))
print("Train")
st = datetime.datetime.now()
for epoch in range(EPOCH_NUM):
# ミニバッチ学習
perm = np.random.permutation(N) # ランダムな整数列リストを取得
total_loss = 0
for i in range(0, N, BATCH_SIZE):
enc_words = data_converter.train_queries[perm[i:i+BATCH_SIZE]]
dec_words = data_converter.train_responses[perm[i:i+BATCH_SIZE]]
model.reset()
loss = model(enc_words=enc_words, dec_words=dec_words, train=True)
loss.backward()
loss.unchain_backward()
total_loss += loss.data
opt.update()
if (epoch+1)%10 == 0:
ed = datetime.datetime.now()
#jptime=ed.strftime('%H:%M:%S')
jptime=f'{ed.hour+9}:{ed.minute}:{ed.second}'
print("epoch:\t{}\ttotal loss:\t{}\ttime:\t{}\ttime:\t{}".format(epoch+1, total_loss, ed-st, jptime))
st = datetime.datetime.now()
if total_loss<1.0:
serializers.save_npz('attention_batch3108_bc_24_manzai_model.model', model)
break
if total_loss<1.0:
serializers.save_npz('attention_batch3108_bc_24_manzai_model.model', model)
# ColaboratoryのGPUメモリ15GBも目一杯利用する形に
# バッチサイズとバッチカラムサイズを調整。
# もっとも速く、損失値も減りやすいようにした、つもり。
BATCH_SIZE = 3108
BATCH_COL_SIZE = 24
# そしてエポック数は1000に。
# 何故ならば、実は逆に時間短縮のためです。
EPOCH_NUM = 1000 # エポック数
# Colaboratoryは謎のセッション切れ、落ちるがあるので、
# 目的の損失値まで一旦下がるまで少しだけ待ち、
# 指定した損失値を下回れば自動で保存して、早々に脱出します。
# 再開時はこちらのコメントを外し、再学習していけばよろしいかと。
# serializers.load_npz('attention_batch3108_bc_24_manzai_model.model', model)
# 最初はこの部分を100とかにして、
if total_loss<100.0:
# モデルを安全にセーブした後、スパルタ学習に突入します。
if total_loss<1.0:
ちなみに、上の
batch_column_sizeの
追加根拠としては
# class AttSeq2Seq(Chain) 内部 # __init__(self, vocab_size, embed_size, hidden_size, batch_col_size) 内部 self.decode_max_size = batch_col_size # デコードはEOSが出力されれば終了する、出力されない場合の最大出力 # __call__(self, enc_words, dec_words=None, train=True) 内部 for i in range(self.decode_max_size): .................................. if y == 0: # EOSを出力したならばデコードを終了する
つまり、batch_col_sizeが大きければ、
適切なデコードを吐き出しやすくなりMASU。
つまり、
つまり、
# デコーダーに渡す応答分の単語数を計算。
from collections import Counter
c_o=Counter([len(d[1][0]) for d in data])
# 最大単語数
max([len(d[1][0]) for d in data])
# => 136
# マジかよ。。。
# 平均。
np.mean([len(d[1][0]) for d in data])
# => 12.971559101730904
# 単語数がでかすぎる行は切り捨てる。
# かなり開きがありそうなので、9割を占める単語数を割り出し。
sum_value=0
for i,k in enumerate(list(c_o.values())):
sum_value+=k
if sum_value/np.sum(list(c_o.values()))>0.9:
print(list(c_o.keys())[i])
break
# => 23
# ということで23に決定。
len(data[0][1][0])
# => 24
# おお。。。
#一発目が24だったので、24にしてから
#最速を求めるべく、batch_sizeを2048~4096くらいに微調整。
やっとWEBアプリ
さて、学習には時間がかかります。
その間にさっさと
アプリをつくりませう。
一旦学習が終わり、 モデルを保存したら、 モデルを置き換えるだけなので、
精度は悪いが、 先に作っておいた学習済みの モデルを使用します。
下の画像のモデルを使います。
今回の整形したデータではなく、 前回のデータです。
一旦学習が終わり、 モデルを保存したら、 モデルを置き換えるだけなので、
精度は悪いが、 先に作っておいた学習済みの モデルを使用します。
下の画像のモデルを使います。
今回の整形したデータではなく、 前回のデータです。
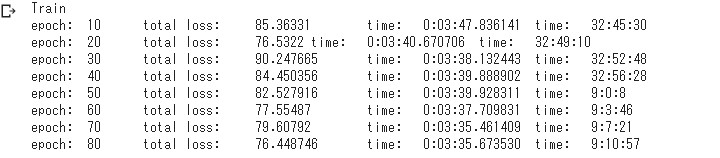
# パラメータはこんな感じ。 EMBED_SIZE = 100 HIDDEN_SIZE = 100 BATCH_SIZE = 4096 # ミニバッチ学習のバッチサイズ数 BATCH_COL_SIZE = 16 EPOCH_NUM = 1000 # エポック数 N = len(data) # 教師データの数
# モデルをローカルにダウンロードする。
from google.colab import files
# 名前は各々がつけた名前。
files.download('attention_batch4096_bc_16_manzai_model.model')
アプリの時間短縮
さあアプリを作りませう。
といきたいところですが、 このままPredict関数を 使ったやりかただと 応答文の作成に結構 時間がかかります。
平均7、8秒くらい。。。
なのでできるだけ 時間を短縮するため 一工夫します。
DataConverterを Predictメソッドで使用するのは
data_vocabのみです。
なので、これだけPickle化して ダウンロードしとけば、 2〜3秒の短縮になりやす。
data_converter.load(data) の部分が短縮になりやす。
といきたいところですが、 このままPredict関数を 使ったやりかただと 応答文の作成に結構 時間がかかります。
平均7、8秒くらい。。。
なのでできるだけ 時間を短縮するため 一工夫します。
DataConverterを Predictメソッドで使用するのは
data_vocabのみです。
なので、これだけPickle化して ダウンロードしとけば、 2〜3秒の短縮になりやす。
data_converter.load(data) の部分が短縮になりやす。
# Dataconverterの
# self.vocab
## ここだけ取り出して、Pickle
data_vocab = data_converter.vocab
with open('data_vocab.pkl','wb') as f:
dill.dump(data_vocab,f)
# ダウンロード
files.download('data_vocab.pkl')
次回へ続く
それではローカルで
Djangoプロジェクトを
立ち上げていきま。。。
長くなってしまったので、 切り分けます。
次回へ持ち越しDESU。
See You Next Page!
立ち上げていきま。。。
長くなってしまったので、 切り分けます。
次回へ持ち越しDESU。
See You Next Page!