Published Date : 2019年5月31日22:20
Deep Manzai Part 4
前回の簡単なあらすじ
準備体操
単語ごとの学習ではなく、
文章単位(一行単位)で
学習させるとどうなるか 試していきたいと思います。
使える環境が Colaboratory オンリーなので、 いつも通りセッテイング。
学習させるとどうなるか 試していきたいと思います。
使える環境が Colaboratory オンリーなので、 いつも通りセッテイング。
# マイドライブマウント
from google.colab import drive
drive.mount('/content/drive')
# マイドライブへ移動
cd /content/drive/My Drive/data
# 前回の台本を全て使って学習するとメモリクラッシュが頻発するので、
# とりあえず細かい前処理を行うため、分かち書きした台本全体のオブジェクトを取得。
import dill
with open('sudachi_daihon.pkl','rb') as f:
daihon=dill.load(f)
print(daihon[0])
# ---> [['どう', 'も', '四千頭身', 'です', '。', 'お', '願い', 'し', 'ます', '。'],......, ['どう', 'も', 'ありがとう', 'ござい', 'まし', 'た', '。']]
# titleだけの確認のための無駄な作業。
#(実際やってみて、メモリが想像以上に消費されるため、
# やもなくアホなことを繰り返す。)
import json
with open('daihon.json','r',encoding='utf-8') as f:
daihon_json=json.load(f)
titles=[d['title'] for d in daihon_json]
print(titles[0])
# ---> '四千頭身「正夢」'
# 両方の長さが合っているか確認。
print(len(daihon),len(titles))
# ---> 839 839
# OK
頭を悩ませる問題
さて、前もって色々試した後
この記事を書いている訳ですが、
実験の結果、 3つの問題が判明。
つーことで、
漫才師(しかも掛け合い重視)
に絞って学習していきます。
といっても839タイトル 調べるのは面倒くさいので、 Wikipedia様に頼りMASU!
実験の結果、 3つの問題が判明。
| 問題1 | メモリの大量消費によるクラッシュ |
|---|---|
| 問題2 | ピン芸だと「会話」として学習できない。(当然だけど忘れてた) |
| 問題3 | コントは動きの表現が多いので、正直学習が難しい。 |
といっても839タイトル 調べるのは面倒くさいので、 Wikipedia様に頼りMASU!
# サクッとスクレイピング。
import requests
from bs4 import BeautifulSoup
# Wikipediaの漫才師一覧から情報を取得。
res=requests.get('https://ja.wikipedia.org/wiki/%E6%BC%AB%E6%89%8D%E5%B8%AB%E4%B8%80%E8%A6%A7')
# HTMLパーサーにlxmlを指定し、整形しやすいようにする。
soup=BeautifulSoup(res.content,'lxml')
# 全liタグを取ってくる。
lis=soup.find_all('li')
# aタグが無いバージョンも考慮して、
# 漫才師リストの終わりも指定して、配列に格納。
manzaishi_list=[]
for li in lis:
try:
manzaishi_list.append(li.a.string)
except:
if li.string.startswith('「現代上方演芸人名鑑」'):
break
else:
manzaishi_list.append(li.string)
# 一応確認。
print(manzaishi_list)
# ---> ['アームストロング', '相方不在',........,'ワンハイスクール', 'ワンワンニャンニャン']
どれほど絞れるか実験
import re
# 漫才師の名前とタイトルに対応するインデックスを格納
manzaishi_indices=[]
for i,title in enumerate(titles):
for manzaishi in manzaishi_list:
try:
if re.search(manzaishi,title):
manzaishi_indices.append(i)
except:
pass
# 対応するタイトルを並び替える
manzaishi_titles=[titles[i] for i in manzaishi_indices]
print(manzaishi_titles)
# ---> ['トット「目玉焼き会議」',
'かまいたち「泉谷しげる」',
'我が家「ふっくら亭杉丸」',
'宮下草薙「ドライブ」',
.....................,
'アルコ&ピース平子「ヤンキーにかます瀬良明正」',
'東京ホテイソン「イルカショー」',
'カミナリ「夏の思い出」',
'アンタッチャブル柴田「動物脱走事件簿」']
print(len(titles),len(manzaishi_titles))
# ---> 839 445
# タイトルに対応する台本を並び替える
manzaishi_daihon=[daihon[i] for i in manzaishi_indices]
print(len(daihon),len(manzaishi_daihon))
# ---> 839 445
復活のKeras
前々回は複雑すぎたので、
シンプルにします。
# 必要なライブラリインポート # TPUを使えるように若干インポート方法を変える。 import numpy as np import sys from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense,LSTM,Activation from tensorflow.keras.optimizers import RMSprop import random
# メモリクラッシュ時に備えて、1タイトルにつき、一行ずつのNumpy配列にする。 scripts=np.array([np.array([' '.join(line) for line in lines]) for lines in manzaishi_daihon]) print(scripts[0]) # ---> array(['どう も トット です 。 よろしく お 願い し ます 。', 'あの こう 見え て 優柔不断 な ん です よ 。',............. print(scripts.shape) # ---> (445,) # 一回実験のため、タイトルを無視して一行ずつのリストを作成。 script_lines=np.concatenate(script) print(script_lines[0]) # ---> どう も トット です 。 よろしく お 願い し ます 。 print(script_lines.shape) # ---> (52736,) # 重複している文をまとめる。 docs = sorted(list(set(script_lines))) # 多分重複しているのは、「どうもありがとうございました。」「よろしくお願いします。」などの漫才定型文あたりだと思う。 print(len(docs),len(script_lines)) # ---> 46793 52736 # 文をキーにインデックス検索 doc_indices = dict((d, i) for i, d in enumerate(docs)) # インデックスをキーに文を検索 indices_doc = dict((i, d) for i, d in enumerate(docs)) print(indices_doc[100]) # ---> 1 個 下げ た ! print(doc_indices['1 個 下げ た !']) # ---> 100
学習イメージ
単純に次の文を予測するだけ。
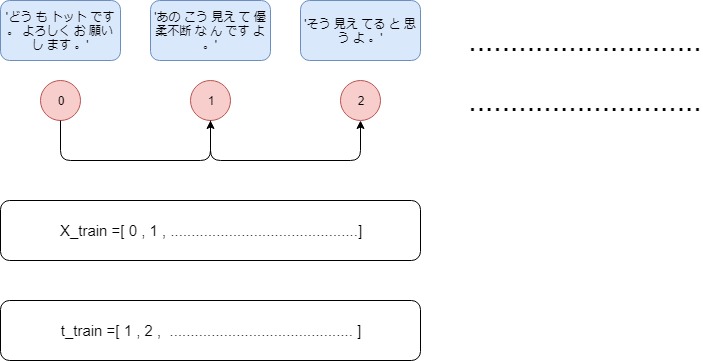
前後の文を予測してもいい。
とりあえずやってみる。
前後の文を予測してもいい。
とりあえずやってみる。
# maxlen は「どれだけの文か」なので、とりあえず9 maxlen=9 # stepは「どれだけ文をずらすか」なので、とりあえず3 step=3 # maxlenの分だけ格納。 sentences=[] # 次の文。 next_lines=[] # それぞれ格納していく。 for i in range(0, len(script_lines) - maxlen, step): sentences.append(script_lines[i:i+maxlen]) next_lines.append(script_lines[i+maxlen]) # 中身確認。 print(sentences[0]) # ---> ['どう も トット です 。 よろしく お 願い し ます 。'],...,'頭 の 中 で 味 を 想像 する って こと ?'] print(next_lines[0]) # ---> お前 なに ?
ベクトル化
# trueとfalseの並びにするための準備。
# 因みにここらへんでメモリ9GBに跳ね上がる。
X = np.zeros((len(sentences),maxlen,len(docs)), dtype=np.bool)
print(X.shape)
# ---> (17576, 9, 46793)
# trueとfalseの並びにするための準備。
y = np.zeros((len(sentences),len(docs)), dtype=np.bool)
print(y.shape)
# ---> (17576, 46793)
# ベクトル化
for i, sentence in enumerate(sentences):
for t, doc in enumerate(sentence):
X[i, t, doc_indices[doc]] = 1
y[i, doc_indices[next_lines[i]]] = 1
print(X[:3,:,:3])
# --->
# array([[[False, False, False],
# [False, False, False],
# [False, False, False],
# [False, False, False],
# [False, False, False],
# [False, False, False],
# [False, False, False],
# [False, False, False],
# [False, False, False]],
# .............................
モデル定義
model = Sequential()
model.add(LSTM(128, input_shape=(maxlen, len(docs))))
model.add(Dense(len(docs), activation='softmax'))
optimizer = RMSprop(lr=0.01)
model.compile(loss='categorical_crossentropy', optimizer=optimizer)
def sample(preds, temperature=1.0):
# helper function to sample an index from a probability array
preds = np.asarray(preds).astype('float64')
preds = np.log(preds) / temperature
exp_preds = np.exp(preds)
preds = exp_preds / np.sum(exp_preds)
probas = np.random.multinomial(1, preds, 1)
return np.argmax(probas)
# TPUを使う設定!
import os
import tensorflow as tf
tpu_grpc_url = "grpc://"+os.environ["COLAB_TPU_ADDR"]
tpu_cluster_resolver = tf.contrib.cluster_resolver.TPUClusterResolver(tpu_grpc_url)
strategy = keras_support.TPUDistributionStrategy(tpu_cluster_resolver)
model = tf.contrib.tpu.keras_to_tpu_model(model, strategy=strategy)
学習
# 学習していく。
for i in range(1,50):
print('_'*50)
print('iretation: ',i)
model.fit(X,y,batch_size=128,epochs=1)
start_index = random.randint(0, len(script_lines)-maxlen-1)
# 保存をするのを忘れずに。さもないと。。。
model.save(manzai_model.h5)
途中経過
やるせない気持ちですね。。。
total3時間ですから。。。

total3時間ですから。。。
# テキスト生成。
# 文ベースに対応するよう若干修正。
for diversity in [0.2,0.5,1.0,1.2]:
print('----- diversity:', diversity)
generated = ''
sentence = script_lines[start_index: start_index + maxlen]
sentence='\n'.join(sentence)
generated += sentence
print('----- Generating with seed: "' + sentence + '"')
sys.stdout.write(generated)
for i in range(400):
# tpu 対策
x = np.zeros((8, maxlen, len(docs)))
for t, doc in enumerate(sentence.split('\n')):
x[0, t, doc_indices[doc]] = 1.
preds = model.predict(x, verbose=2)[0]
next_index = sample(preds, diversity)
next_doc = indices_doc[next_index]
generated = generated+'\n'+next_doc
joined='\n'.join(sentence.split('\n')[1:])
sentence = joined+'\n'+next_doc
sys.stdout.write(next_doc)
sys.stdout.flush()
print()
結果
続いて、
テキストを生成の結果。

テキストを生成の結果。
おまけ
ためしに、
「どうもありがとうございました。」を
入れてみる。
注意としては、同じ分かち書き でなければならないので、
SudachiぃならSudachiで、 JanomeならJanome、 NagisaならNagisa、 MeCabならMeCabで、 その他ならその他でどうぞ。
注意としては、同じ分かち書き でなければならないので、
SudachiぃならSudachiで、 JanomeならJanome、 NagisaならNagisa、 MeCabならMeCabで、 その他ならその他でどうぞ。
# JSONファイルを読み込むためにインポート
import json
# Sudachiぃを使えるようにインポート
from sudachipy import config
from sudachipy import dictionary
from sudachipy import tokenizer
# 必要な設定ファイルを読み込む
with open(config.SETTINGFILE, 'r', encoding='utf-8') as f:
settings = json.load(f)
# 形態素をするためのオブジェクトを作成
tokenizer_obj = dictionary.Dictionary(settings).create()
mode = tokenizer.Tokenizer.SplitMode.C
gen_seed=input('何か掛け合いっぽい言葉を入力してくだちぃ。->: ')
print('分かち書き中。')
text_seed=' '.join([token.surface() for token in tokenizer_obj.tokenize(mode,gen_seed)])
print('MeCabぅ、Sudachiぃが形態素解析するんだよぉ。')
print('done.')
print(f'わかちしたよ。なめてないぞぉ。-> {text_seed}')
print()
print('漫才生成Start。ワードがなければ何も生まれません。ポンコツ生成器です。')
print()
for diversity in [0.2,0.5,1.0,1.2]:
print('----- diversity:', diversity)
generated = ''
sentence=text_seed
generated = sentence
print('----- Generating with seed: "' + sentence + '"')
for i in range(400):
x = np.zeros((8, maxlen, len(docs)))
try:
x[0, t, doc_indices[text_seed]] = 1.
except:
print('一語一句合ってないとだめですから!!残念っ!!')
sys.exit()
preds = model.predict(x, verbose=2)[0]
next_index = sample(preds, diversity)
next_doc = indices_doc[next_index]
generated = generated+'\n'+next_doc
sentence = joined+'\n'+next_doc
sys.stdout.write(next_doc)
sys.stdout.flush()
print()
まあ。。文ベースなので、
一行一行はちゃんとしてるよね。








後半になると詰まってきて、 意味不明さと、 微妙なすれ違いでくすっとくる。
それと知ってるネタの 掛け合いがはまると嬉しい。
後半になると詰まってきて、 意味不明さと、 微妙なすれ違いでくすっとくる。
それと知ってるネタの 掛け合いがはまると嬉しい。
なんかあれを
入れたくなってみた。
インターネットのヤホーで 調べてきました。





インターネットのヤホーで 調べてきました。
次回へ続く
とりあえず次やりたことは、
ボケだけ一文ずつ生成して、
ツッコミを入力して、 またボケて。。。
もっといいやり方を模索するか。。。
こうして同じテーマの 無限ループは続く。。。
かもしれない。
See You Next Page!
ツッコミを入力して、 またボケて。。。
もっといいやり方を模索するか。。。
こうして同じテーマの 無限ループは続く。。。
かもしれない。
See You Next Page!