Published Date : 2019年5月2日19:36
マルコフアプリの作り方
前回の記事の簡単なおさらい
Google Colaboratoryと
Sudachiと
マルコフ連鎖 のライブラリ
markovify を使って、
モーニング娘。の メンバー達のブログ記事を、
形態素解析し、 なんちゃって 文章自動生成WEBアプリ を作りました。
上のナビバーにもあります。
マルコフ連鎖 のライブラリ
markovify を使って、
モーニング娘。の メンバー達のブログ記事を、
形態素解析し、 なんちゃって 文章自動生成WEBアプリ を作りました。
上のナビバーにもあります。
マルコフレボリューション
データをダウンロード
# またまた何回目なのよ!のドライブマウント。
from google.colab import drive
drive.mount('/content/drive')
# 前回のフォルダに民族大移動 cd drive/'My Drive'/data # 移動後、中身を確認。 ls -al
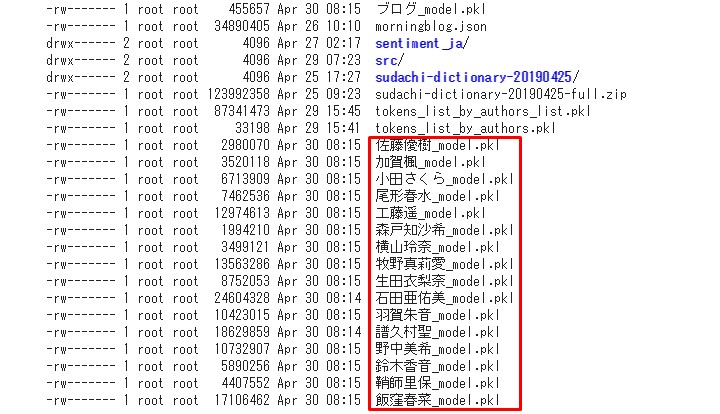
SQLiteにする
全てをこのまま扱うと、
結構な容量があるので、 圧縮しつつ、SQLiteに直し、
Djangoで扱いやすいようにしよう。
結構な容量があるので、 圧縮しつつ、SQLiteに直し、
Djangoで扱いやすいようにしよう。
# 前回、塩漬けにしたピックルオブジェクトをご開封
# 諸事情によりPython標準のPickleモジュールをDillの代わりに使う。
import pickle
# 簡単な正規表現でファイルを指定して、取り出せる便利なやつ、glob。
import glob
markov_model_path=glob.glob('./*_model.pkl')
import markovify
をしたいところですが、
セッションが切れていると 再インストールが必要です。
セッションが切れていると 再インストールが必要です。
!pip install markovify
# マルコフモデルを読めるようにしなければならないので、インポート
import markovify
# 後でSQLiteに格納したのち、
# # また取り出すため関数にしておく。
def load_pickles(pkl_path):
with open(pkl_path,'rb') as f:
model_obj=pickle.load(f)
return model_obj
# マルコフモデルを一つずつ取り出し、リストにする。
# 実行時間約6秒
mm_models=[load_pickles(path_) for path_ in markov_model_path]
SQLite3
DjangoにSQLite3を
ぶちこめば、即使える。
SQLite3を使う理由は ただこれだけ。
SQLite3とは単なる データベースのファイルだよ。
SQLite3を使う理由は ただこれだけ。
SQLite3とは単なる データベースのファイルだよ。
# sqlite3 を扱うためにインポート import sqlite3 # データベースの名前を決める。 # 好きな名前をつけてね。 dbname = 'mmblog_markov_model.sqlite3' # 後楽園でデータベースと握手! conn = sqlite3.connect(dbname) # データベースを操作できるようにするよ! c = conn.cursor() # エクセルシートみたいなものを作るよ! # そのための命令文だけ文字列にしておくよ。 create_sql = "create table markovmodels (id integer, name text, blog_model)" # エクセルシートみたいなものを作るよ! c.execute(create_sql) # 戦いの前のセーブをするよ! conn.commit() # 一旦ゲーム中断するよ! conn.close()
ここにいるぜぇ!

SQLiteができたので、
マルコフモデルを
オブジェクトのまま 圧縮して中にぶっこみます。
オブジェクトのまま 圧縮して中にぶっこみます。
疾風伝説 特攻のSQLite
# ファイルを圧縮してくれるヤツだよ!
import bz2
# みんな大好きOSモジュールだよ!
import os
# 関数の時間だ!こらぁ!
# !?
# # ピックルして瓶に蓋をしてツメツメする関数だよ!
def pickle_to_zip(obj):
# 3 は圧縮率
# 9まであり、高ければ高圧縮
return bz2.compress(pickle.dumps(obj, PROTOCOL), 3)
# !?
# # ピクルスの瓶を開けてお皿に並べる関数だよ!
def zip_to_pickle(b):
# 解凍して、ピックルからオブジェクトにして返す。
return pickle.loads(bz2.decompress(b))
なぜなにプロトコル
明日の朝刊載ったゾ!プロトコル!
説明しよう! プロトコルとは通信をする際の 約束事である。
JSONとPickleのプロトコルの 決定的な違いは、
テキスト形式(人間が普通に読める)か、
バイナリ形式(人間読めねぇー)かである。
だからなんだよ! プロトコル!
説明しよう! プロトコルとは通信をする際の 約束事である。
JSONとPickleのプロトコルの 決定的な違いは、
テキスト形式(人間が普通に読める)か、
バイナリ形式(人間読めねぇー)かである。
だからなんだよ! プロトコル!
メインディッシュ
# なんでプロトコルだって?んああ、おっしゃらないで。 # # 気に入ったのは、以下の長い説明だけだ! # ここで、プロトコルバージョンをもっとも高く設定しているのは # # プロトコルバージョンが低いと、対応するPythonバージョンも低い。 # # # つまり、Pythonバージョンと共に歩んできたPickleの進化によって # # # # 便利になった部分や圧縮率の恩恵が得られない。 # # # # # なので、もっとも「自分のPythonで利用できるもっとも高いプロトコル」を選択するようにしています。 PROTOCOL = pickle.HIGHEST_PROTOCOL
続き。
# 後で取り出しやすくするため、
# モデルの名前を把握する。
model_names = [path_.split('_')[0] for path_ in markov_model_path]
# 一旦終了したゲームを再開するように、
# SQLiteデータベースに再アクセス。
conn = sqlite3.connect(dbname)
c = conn.cursor()
# IDと、モデル名、圧縮ピックルを
# データベースに入れていけという命令文を作る。
# (?,?,?)これはプレースホールダーといって、
# 場所を仮で確保しておくことができるよ。
# 明日花見がしたいからプレースホールダー(?,?,?)三人衆。
insert_sql = "insert into markovmodels (id, name, blog_model) values (?,?,?)"
# 実行時間21秒
# さっき作ったピックルにして圧縮する関数を併用して、
# インデクス番号+1でIDに、モデルの名前と、モデルを
# タプルのリストにして、インサートするオブジェクトにするよ!
insert_objs = list(zip(list(range(1,len(model_names)+1)), model_names, [pickle_to_zip(mmm) for mmm in mm_models]))
# executemanyは一度にたくさん命令を実行してくれるよ!
# !?データベースにぶっこむよ!
c.executemany(insert_sql, insert_objs)
# コミット(結果を残すぜ!)するよ!
conn.commit()
それじゃあ中身が
どうなっているのか、
確認してみましょうか。
どうなっているのか、
確認してみましょうか。
# さっき作ってデータを入れた
# テーブル名から
# 全部の情報を抜き出す命令を作るよ!
select_sql = 'select * from markovmodels'
# 一行ずつ何が入っているか見てみるよ!
# 実行時間15秒
for row in c.execute(select_sql):
# さっき作った解凍する関数を使って
# 3列目、インデックス番号2、を
# オブジェクになおすよ!
print((row[0], row[1], zip_to_pickle(row[2])))
# 処理が終わったら面倒くさがらず
# データベースの電源を落とすよ!
conn.close()
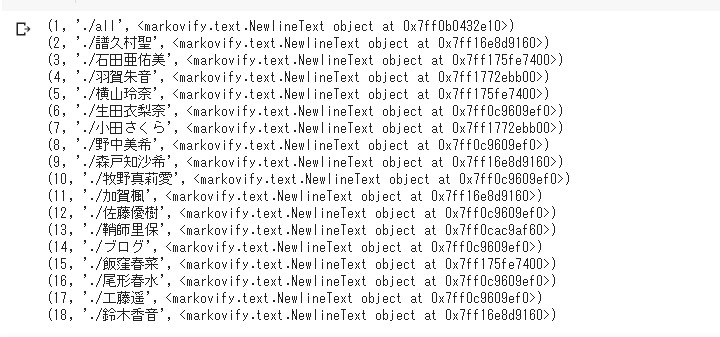
きちんとオブジェクトのまま
データベースに格納されていますね!
サイズがどれだけ圧縮されたか 確認してみましょう。
サイズがどれだけ圧縮されたか 確認してみましょう。
# getsize()はファイルの容量をバイトで知らせてくれる。
all_size = sum([os.path.getsize(path_) for path_ in markov_model_path])
dbsize=os.path.getsize(dbname)
# キロバイト=1024バイトなので、それで計算。
f'{round(all_size/1024/1024)}MB'
f'{round(dbsize/1024/1024)}MB'

通常の集合体、約275MB。
一つずつ圧縮したDB、約43MB。
約6分の1に圧縮されました。 めでたしめでたし。
約6分の1に圧縮されました。 めでたしめでたし。
SQLiteをダウンロード
それではDjangoでアプリを
作っていくため、
一旦ローカル作業に入ります。
作ったSQLiteを ダウンロードします。
ダウンロードは簡単。
楽ちんポンやで。
一旦ローカル作業に入ります。
作ったSQLiteを ダウンロードします。
ダウンロードは簡単。
楽ちんポンやで。
from google.colab import files
# ダウンロードしたいファイル名を指定するだけ。
files.download(f'{dbname}')
ダウンロードフォルダに、
ぶっこまれます。
とりあえず前半戦終了。
See You Next Page !
とりあえず前半戦終了。
See You Next Page !