Published Date : 2019年4月30日2:18
モーニングマルコフ
前回の記事の簡単なおさらい
マルコフ連鎖
前回の感情分析では
あまり納得のいく
結果は得られなかった。
もっと踏み込んで、 文章を形態素に分割してから
感情評価表といったものを使って
東北大の乾・岡崎研究室 が公開している
日本語評価極性辞書
東工大の高村教授が公開している
単語感情極性対応表
細かく学習していこう かと思いましたが、
同じことをしていると 飽きてくるので、
今回は「マルコフ連鎖」を使い
簡易的な「文章自動生成」 を行っていこうかと思います。
もっと踏み込んで、 文章を形態素に分割してから
感情評価表といったものを使って
例えば以下
東北大の乾・岡崎研究室 が公開している
日本語評価極性辞書
東工大の高村教授が公開している
単語感情極性対応表
細かく学習していこう かと思いましたが、
同じことをしていると 飽きてくるので、
今回は「マルコフ連鎖」を使い
簡易的な「文章自動生成」 を行っていこうかと思います。
マルコフ連鎖で文章自動生成
至極簡単に説明すると、
「私は 速く 歩く !」
「私は 遅く 歩く ?」
こんな2つの文章があるとします。
以下の画像をみてください。
「私は 速く 歩く !」
「私は 遅く 歩く ?」
こんな2つの文章があるとします。
以下の画像をみてください。
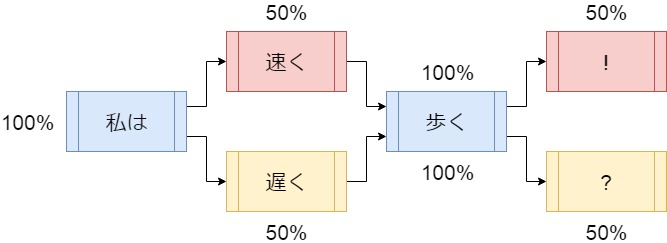
最初の単語を「私は」にすると、
次の単語は「速く」
もしくは「遅く」。
「私は」(正確には「私」と「は」) から「速く」は50%の確率。
「遅く」は50%の確率になります。
次に「歩く」にいく確率は 一つしかないので100%の確率。
そうやって「今の単語」と 「次の単語」の確率を
計算していき、 文章を作っていくのが マルコフ連鎖による 文章生成方法です。
これは今流行の人工知能 とは言い難いです。
ただし、 それなりの文章は作っていけます。
そして、Pythonには 簡単に「マルコフ連鎖」を行って、
「文章自動生成」が作れる ライブラリが存在するので、
手軽に 「マルコフ連鎖による文章自動生成」 を試すことができます。
偉大なる先人達に 感謝して使いましょう。
「私は」(正確には「私」と「は」) から「速く」は50%の確率。
「遅く」は50%の確率になります。
次に「歩く」にいく確率は 一つしかないので100%の確率。
そうやって「今の単語」と 「次の単語」の確率を
計算していき、 文章を作っていくのが マルコフ連鎖による 文章生成方法です。
これは今流行の人工知能 とは言い難いです。
ただし、 それなりの文章は作っていけます。
そして、Pythonには 簡単に「マルコフ連鎖」を行って、
「文章自動生成」が作れる ライブラリが存在するので、
手軽に 「マルコフ連鎖による文章自動生成」 を試すことができます。
偉大なる先人達に 感謝して使いましょう。
マルコフ娘。
それでは実際に作っていきましょう。
まずは環境作りです。
まずは環境作りです。
必要なライブラリをインストール
!pip install markovify
試しに使ってみる
テストとして、
使用してみます。
テスト用テキストは、 モーニング娘。のWikipediaページ から拝借しました。
文章は形態素で分割した後、 整形しましたが、
後でその方法と ライブラリの説明はしていきます。
使用してみます。
テスト用テキストは、 モーニング娘。のWikipediaページ から拝借しました。
文章は形態素で分割した後、 整形しましたが、
後でその方法と ライブラリの説明はしていきます。
# ライブラリをインポート
import markovify
# Wikipediaの文章を形態素で分割して、
# 不要な文字を取り除き、
# 改行をつけて一つの文字列にする。
text="モーニング娘。 モーニング むすめ は 、 日本 の 女性 アイドル ・ ボーカル & ダンス グループ で ある \n
所属 事務所 は アップフロントプロモーション 旧 ・ アップフロントエージェンシー \n
ハロー ! プロジェクト 以下 、 ハロプロ の 一員 \n
略称 は モー娘。 モー むす。 娘。 むすめ と 略さ れる こと も ある \n
また 、 メンバー や OG など は モーニング と 呼ぶ こと も 多い \n
日本 国外 で の 表記 は Morning Musume。 英語 、 早 安 少女 組 。 中国 語 など \n
正式 名称 について 、 2014 年 1 月 1 日 以降 は モーニング 娘。 の 後 に 当該 年 の 西暦 の 下 二 桁 を 付し て モーニング 娘。 '○○ と し て いる \n
例 : モーニング 娘 。 19 \n
読み は 、 もーにんぐむすめ に 続い て 、 西暦 の 10 の 位 と 1 の 位 を それぞれ 英語 読み する \n
例 : モーニング 娘。 19 なら ば モーニング むすめ ワン ナイン \n
ほぼ 全 楽曲 の 作詞 ・ 作曲 を 同 グループ の 生み の 親 で サウンド プロデューサー の つんく♂ シャ乱Q が 手掛ける \n
1998 年 の メジャーデビュー から 2018 年 10 月 現在 まで に リリース し た シングル の うち 66 作品 が オリコン の 週間 CD 販売 ランキング の トップ 10 に 、\n
さらに その 大 部分 が トップ 5 に 入り 、 過去 に は NHK 紅白 歌合戦 に 10 年 連続 出場 する など 、\n
グループ 発足 から 現在 に 至る まで 20 年 以上 に 渡り 安定 し た 人気 を 保ち 続け て いる \n
また 、 日本 国外 に も 多く の ファン が 存在 し 、 海外 ライブ や イベント など も 行う \n"
# 色々試してみて、日本語の場合は
# 形態素で分割したのち、
# 文の終わり「。」を改行に変えて
# 一つの文字列にして、NewlineTextメソッドを
# 使用したほうが良く認識してくれたので、
# この方法をとってます。
text_model = markovify.NewlineText(text)
# できたモデルを使って文章生成。
# make_sentenceメソッドを使い十回文章を生成させる。
# 文章が出来ないとNoneが返されるので、
# If文を使ってそれを弾いて表示させる。
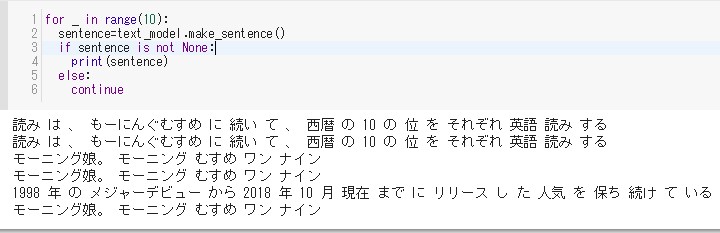
for _ in range(10):
sentence=text_model.make_sentence()
if sentence is not None:
print(sentence)
else:
continue
結果は以下。
そんなに不自然ではないが、 何せ文章量が少ないので、 如何ともし難い。
そんなに不自然ではないが、 何せ文章量が少ないので、 如何ともし難い。
というよりも、
元の文章とあまり変わらない。
はちゃめちゃが 押し寄せてくるような、 カオスを味わいたい。
つーことで今回も不本意ですが、 ネタになってしまいます。
元の文章とあまり変わらない。
面白くない!
はちゃめちゃが 押し寄せてくるような、 カオスを味わいたい。
つーことで今回も不本意ですが、 ネタになってしまいます。
いざカオスへ
形態素解析
Colaboratoryに戻り、
形態素に分割するための ライブラリを インストールしていきます。
形態素解析はMecabが有名ですが、
今回はsudachi というものを使っていきます。
偉大な素晴らしき先輩達に感謝です! サンキューです!
形態素に分割するための ライブラリを インストールしていきます。
形態素解析はMecabが有名ですが、
今回はsudachi というものを使っていきます。
偉大な素晴らしき先輩達に感謝です! サンキューです!
Google Driveをマウント
# ブログ記事の文章を使うため、
# Sudachiをドライブに保存するため、
# またまた何回目なのよ!のドライブマウント。
from google.colab import drive
drive.mount('/content/drive')
Mecabぅ、Sudachiが形態素するんだよ
# 前回のフォルダに民族大移動 cd drive/'My Drive'/data # sudachi install !pip install -e git+git://github.com/WorksApplications/SudachiPy@develop#egg=SudachiPy
こんな感じどぅえす。
Google Drive
をマウントできたら、
My Drive内の 目的のフォルダに移動しましょう。
そこで、Sudachiぃを ダウンロードします。
さらに最新の辞書があれば、
「ネットスラング」や 「新語」などにも対応できるので、
ダウンロードして セットアップしていきます。
My Drive内の 目的のフォルダに移動しましょう。
そこで、Sudachiぃを ダウンロードします。
さらに最新の辞書があれば、
「ネットスラング」や 「新語」などにも対応できるので、
ダウンロードして セットアップしていきます。
# 最新の辞書をダウンロード !wget https://object-storage.tyo2.conoha.io/v1/nc_2520839e1f9641b08211a5c85243124a/sudachi/sudachi-dictionary-20190425-full.zip # ZIPを解凍 !unzip sudachi-dictionary-20190425-full.zip # 辞書を使えるように、大本営へ移してあげる。 !mv sudachi-dictionary-20190425/system_full.dic src/sudachipy/resources/system.dic
こんな感じどぅえす。
sudachipyの出番
# SudachiをPythonで使えるように民族大移動
cd src/sudachipy
# JSONファイルを読み込むためにインポート
import json
# Sudachiぃを使えるようにインポート
from sudachipy import config
from sudachipy import dictionary
from sudachipy import tokenizer
# ブログ記事を読み込む
# '../../'は上の上のフロアを意味しています。
with open('../../morningblog.json','r',encoding='utf-8') as f:
morning_blog=json.load(f)
準備ができたら、
サクッと使ってみる。
# 必要な設定ファイルを読み込む
with open(config.SETTINGFILE, 'r', encoding='utf-8') as f:
settings = json.load(f)
# 形態素をするためのオブジェクトを作成
tokenizer_obj = dictionary.Dictionary(settings).create()
# 実験で短い文章を入れてみる。
# windowsなら改行マークは「¥n」でよし。
text='\n'.join(morning_blog[0]['article'])
# SplitMode.C(モードC)
# にするといい感じに長い単語を認識してくれる。
mode = tokenizer.Tokenizer.SplitMode.C
# いざ形態素解析。
tokens = tokenizer_obj.tokenize(mode, text)
# 単語ごとにバラバラに分割したものを一つずつ解析。
for i,t in enumerate(tokens):
# 例外を排除していく。
try:
# 単語を正規化していく。
# こんばんわ ー> 今晩は
# ふいんき ー> 雰囲気(ふんいき)
# ツア− ー> ツアー 等
# 全角を半角にしたり、半角を全角にしたり、
# 漢字に直したり、通常の表現方法に直したり、etc
norm = tokenizer_obj.tokenize(mode,t)[0].normalized_form()
# 単語の品詞を調べる。
# 名詞、動詞、助動詞、形容詞など。
p_o_s = tokenizer_obj.tokenize(mode,norm)[0].part_of_speech()[0]
# 元の単語と、比べて表示していく。
print(f'*********{i+1}回目の解析*********')
print(f'元の単語 -> {t} : 正規化表現 -> {norm}')
print(f'元の単語 -> {t} : 品詞 -> {p_o_s}')
print('*'*30)
# 例外が出たら無視して続ける
except:
pass

ツッコミどころ満載ですが、
ひとまず続けていきましょう。
ストップワードと前処理
このように、特にブログの文章だと、
形態素解析が難しいです。
意図しない単語の正規化だったり、 上手く分割できなかったり。
ただ、その人の文章の特徴である 記号や、絵文字、表現方法も 上手に活用していきたいので、
ここは正規化は行わず、 品詞による分け方も行わず、
生の表現を できるだけ使用していきます。
しかしながら、 厳密に形態素解析を行う場合は、
ストップワード (指定した文字を排除する)
の選定や、品詞によって分けていく (名詞だけに絞る)など。
色々と膨大な時間と 頭を悩ませる前処理を 行っていかなければなりません。
ネタでは無く、 真剣な研究や業務
などでは避けて通れません。
が、今回は何も考えず ノーガードゆるふわ戦法で マルコフりましょう。
意図しない単語の正規化だったり、 上手く分割できなかったり。
ただ、その人の文章の特徴である 記号や、絵文字、表現方法も 上手に活用していきたいので、
ここは正規化は行わず、 品詞による分け方も行わず、
生の表現を できるだけ使用していきます。
しかしながら、 厳密に形態素解析を行う場合は、
ストップワード (指定した文字を排除する)
の選定や、品詞によって分けていく (名詞だけに絞る)など。
色々と膨大な時間と 頭を悩ませる前処理を 行っていかなければなりません。
ネタでは無く、 真剣な研究や業務
などでは避けて通れません。
が、今回は何も考えず ノーガードゆるふわ戦法で マルコフりましょう。
荒ぶるマルコフ魂
我々はデータフレームを求めている
別にJSONのままでもいいけど、
データフレームに直して、
データを眺めてみよう。
本当は文字数や 段落の数の分析のため、
記事を改行で区切って リストにしてましたが、
データフレームに 直す際は問題になるので、
めんどくさいですが、 一旦全て 一つの文字列に結合してから、
パンダちゃんで、 データフレームにします。
データを眺めてみよう。
本当は文字数や 段落の数の分析のため、
記事を改行で区切って リストにしてましたが、
データフレームに 直す際は問題になるので、
めんどくさいですが、 一旦全て 一つの文字列に結合してから、
パンダちゃんで、 データフレームにします。
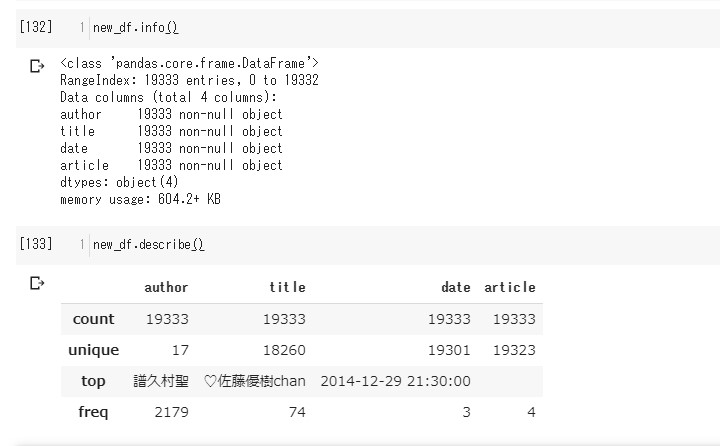
# データをいっぺんに処理するためPandasをインポート import pandas as pd # 全ての記事のリストを改行で繋げて文字列にする。 articles=['\n'.join(mb['article']) for mb in morning_blog] # データフレームに変換。 new_df=pd.DataFrame([[mb['author'],mb['title'],mb['date'],articles[i]] for i,mb in enumerate(morning_blog)],columns=list(morning_blog[0].keys())) # 情報を覗く。 new_df.info() # 情報を覗く。 new_df.describe()
情報を覗く。
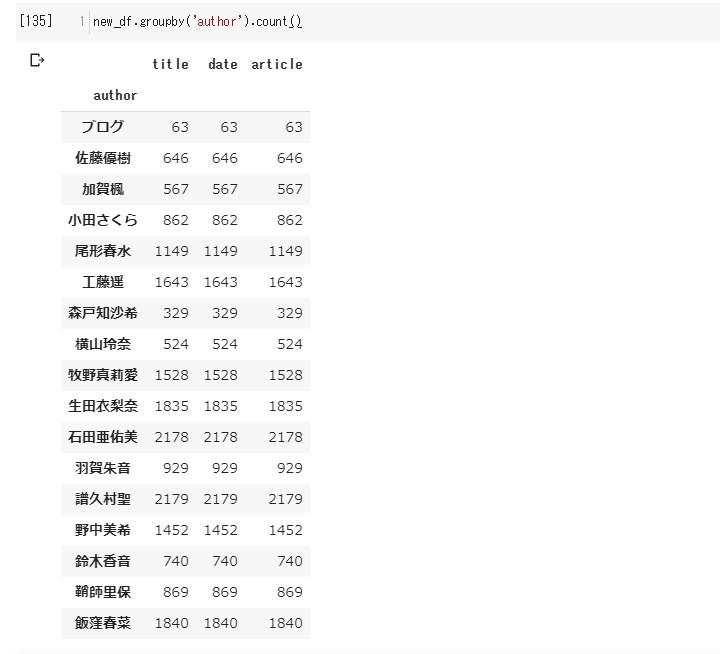
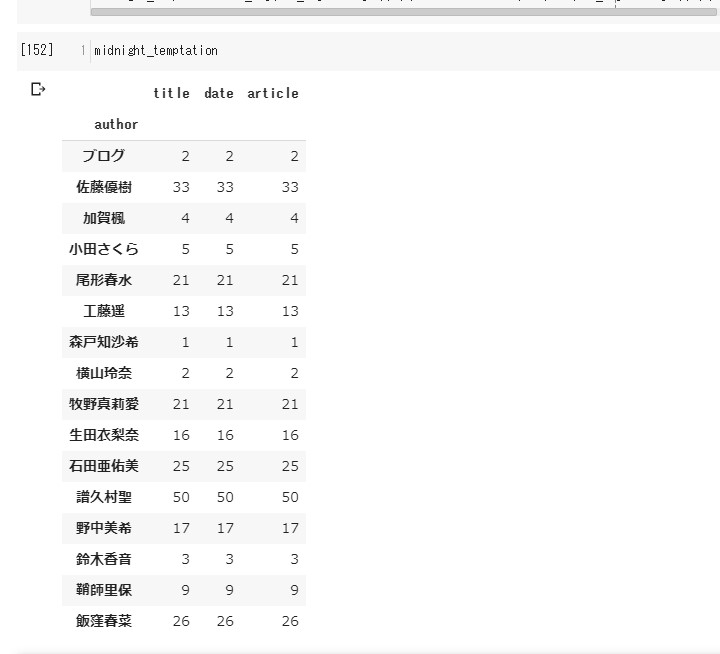
# メンバーごとに数値化してみる。
new_df.groupby('author').count()
# 時間をDatetimeオブジェクトにすり替える。 new_df['date']=new_df['date'].apply(pd.to_datetime)
ちょっと脱線して、
時間の関係性を見てみる。
# 午前中、午後、夕方、夜、夜中の彼女らの動向(マネージャーの動向)
morning_coffee=new_df[(new_df['date'].apply(lambda x: x.hour)>=6) & (new_df['date'].apply(lambda x: x.hour)<=12)].groupby('author').count()
afternoon_count=new_df[(new_df['date'].apply(lambda x: x.hour)>=13) & (new_df['date'].apply(lambda x: x.hour)<=16)].groupby('author').count()
after_five=new_df[(new_df['date'].apply(lambda x: x.hour)>=17) & (new_df['date'].apply(lambda x: x.hour)<=19)].groupby('author').count()
night_count=new_df[(new_df['date'].apply(lambda x: x.hour)>=20) & (new_df['date'].apply(lambda x: x.hour)<=23)].groupby('author').count()
midnight_temptation=new_df[(new_df['date'].apply(lambda x: x.hour)>=0) & (new_df['date'].apply(lambda x: x.hour)<=5)].groupby('author').count()
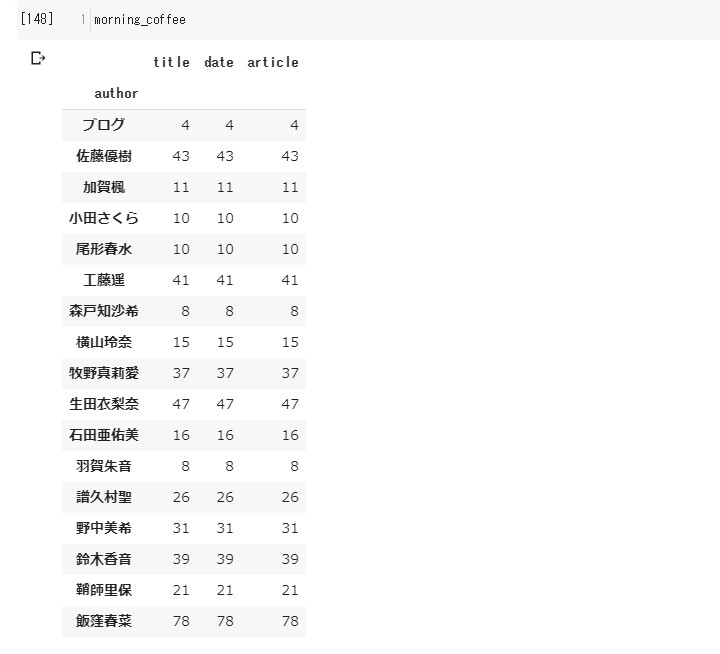
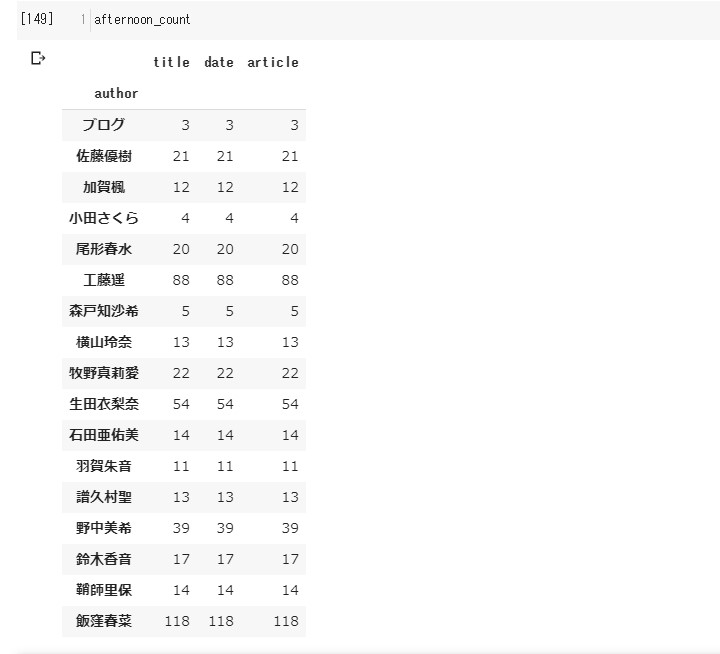
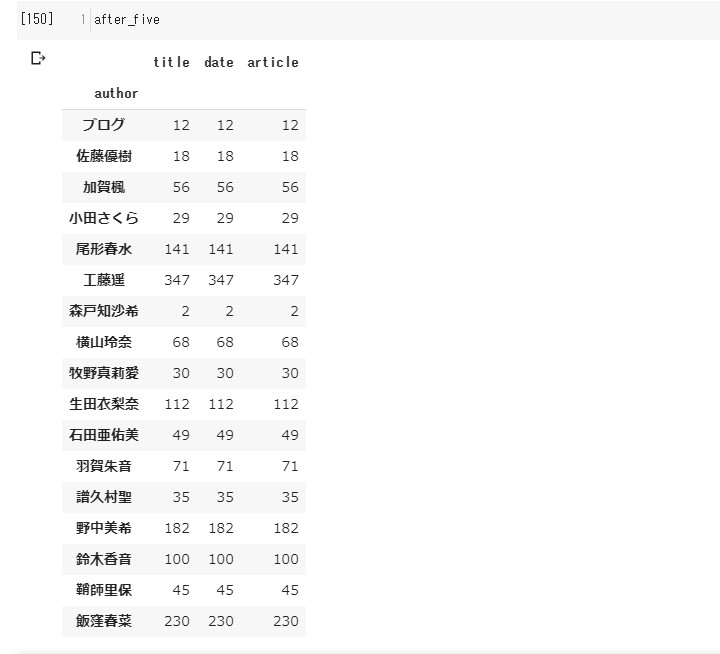
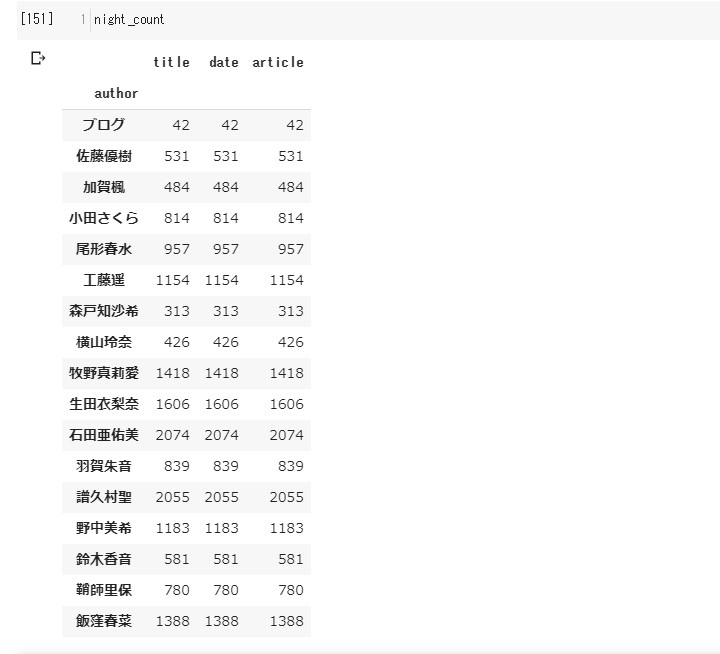
メンバーのブログが
待ち切れないあなた!
20時から24時になれば、 80%以上の確率で マネージャーが上げてくれますよ!
20時から24時になれば、 80%以上の確率で マネージャーが上げてくれますよ!
軌道修正
脱線から戻って参りました。
続き、形態素解析です。
以下のコードで一発ですが、
続き、形態素解析です。
以下のコードで一発ですが、
tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in articles]
ちょおっと待った!
チョトマテクダサイ!
チョトマテクダサイョ シャチョサン!
はっきりいって、 相当時間がかかりました。
GPUのメモリを9ギガバイト消費。 1時間かかりやした。へっ!
19333記事あるので、メンバー分分割 してから行いましょう。はい。
# "author"の名前をリストにする。 authors=new_df['author'].unique().tolist() # "author"ごとにデータフレームを分ける。 split_by_author_df=[new_df[new_df['author'].apply(lambda x: x == author)] for author in authors]
一瞬で終わる、楽をするためのVS Code講座
ここで、VS CodeのみのTips
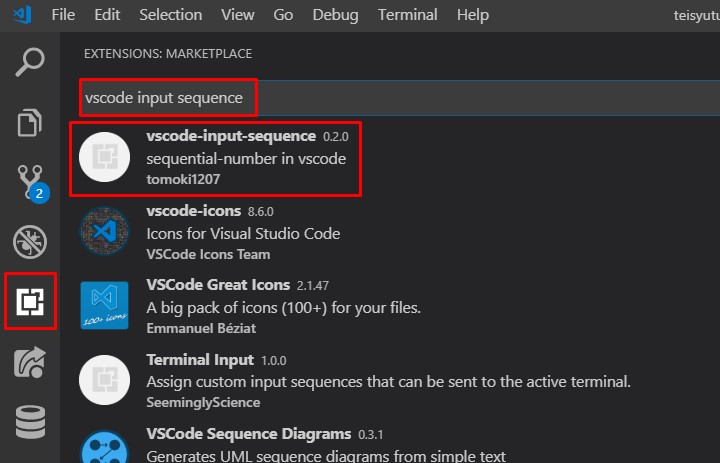
VS Codeには、 vscode-input-sequence なるエクステンションがあります。
作者はこの人
貢献者、 コントリビューターさん達。 サンキューです!
導入方法は至って簡単。
左の赤枠をポチる。
上の赤枠の検索窓に vscode-input-sequenceと打つ。
VS Codeには、 vscode-input-sequence なるエクステンションがあります。
作者はこの人
貢献者、 コントリビューターさん達。 サンキューです!
導入方法は至って簡単。
左の赤枠をポチる。
上の赤枠の検索窓に vscode-input-sequenceと打つ。
赤枠のインストールをポチる。
終了。
終了。
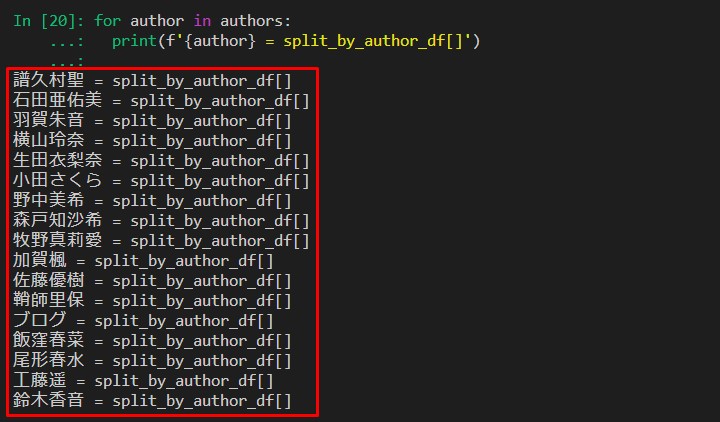
# "author"を表示させてエディターにコピペ。
# print関数に今からPythonコードで繰り返すコードを先取り40万
for author in authors:
print(f'{author} = split_by_author_df[]')
上の赤枠をコピペしてから
split_by_author_dfを選択し、
Ctrl + D(MacならCOMMAND +D) で一番下まで複数選択する。
Ctrl + D(MacならCOMMAND +D) で一番下まで複数選択する。
全部選択し終わったら、
「ー>」キーを一回右に押す。
さらにもう一回、
「ー>」キーを一回右に押す。
ここで「CTRL + SHIFT + P」
Macなら「Command (⌘ コマンド)」+「Shift (⇧ シフト) + P」
を押す。
Macなら「Command (⌘ コマンド)」+「Shift (⇧ シフト) + P」
を押す。
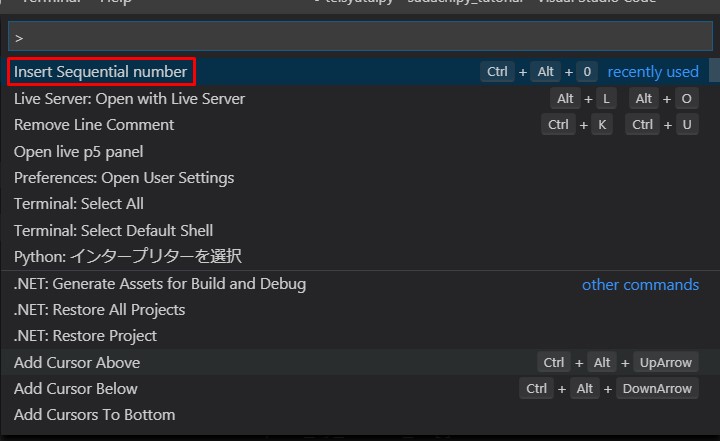
赤枠部分の
「Insert Sequential number」
をクリックするか、
「Insert Sequential number」
と打ち込んで「ENTER」。
赤枠部分に、 インデックス番号0番目から 連番をスタートさせるよう 「0」を入力。
そうすると0〜16の連番 が自動で入力されている。
地味に便利。快適。
「Insert Sequential number」
と打ち込んで「ENTER」。
赤枠部分に、 インデックス番号0番目から 連番をスタートさせるよう 「0」を入力。
そうすると0〜16の連番 が自動で入力されている。
地味に便利。快適。
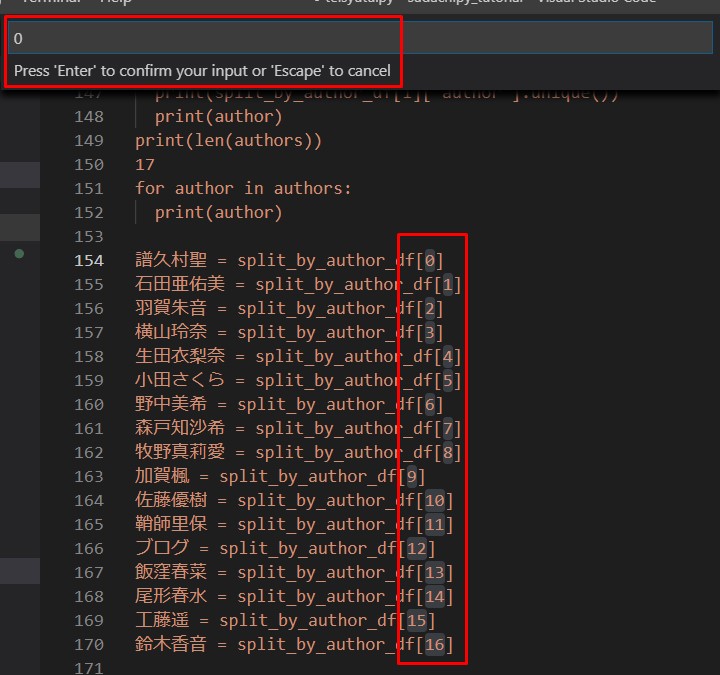
# Google Colaboratory へ貼り付けるんるん。 # Python3は日本語の変数にしても全然OK 譜久村聖 = split_by_author_df[0] 石田亜佑美 = split_by_author_df[1] 羽賀朱音 = split_by_author_df[2] 横山玲奈 = split_by_author_df[3] 生田衣梨奈 = split_by_author_df[4] 小田さくら = split_by_author_df[5] 野中美希 = split_by_author_df[6] 森戸知沙希 = split_by_author_df[7] 牧野真莉愛 = split_by_author_df[8] 加賀楓 = split_by_author_df[9] 佐藤優樹 = split_by_author_df[10] 鞘師里保 = split_by_author_df[11] ブログ = split_by_author_df[12] 飯窪春菜 = split_by_author_df[13] 尾形春水 = split_by_author_df[14] 工藤遥 = split_by_author_df[15] 鈴木香音 = split_by_author_df[16]
今度こそSudachiぃの出番だよぉ!
一番数が少ないであろう
「ブログ」で様子を見る。
# 一応長さ確認。
len(ブログ_tokens_list)
---> 63
# 形態素解析 (約5秒)
ブログ_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in ブログ['article']]
# 一個表示してみる。
print(''.join([t.surface() for t in ブログ_tokens_list[0]]))

あれ!?よこやん!?
一抹の不安が。。。
全部確認してみる。
一抹の不安が。。。
全部確認してみる。
一応順番は合ってる。
次は「ブログ」の中身を直接みる。
次は「ブログ」の中身を直接みる。
display([(i,a.split('\n')[-1]) for i,a in enumerate(ブログ['article'].tolist())])


どうやら「事務所」からのお知らせは
2015年05月29日が最後みたい。
それ以降は何か 作者がバラバラになっている。。。
2015年05月29日が最後みたい。
それ以降は何か 作者がバラバラになっている。。。
LOSS OF TIME!!
細けぇこたぁいいんだよ。
(遠い目)
(遠い目)
# 一つづつ様子を見て
# 片付けて行きたいので
for author in authors:
print(f'''{author}_tokens_list =
[tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article)
for article in {author}['article']]''')
上の出力をまたコピペ。
譜久村聖_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in 譜久村聖['article']] 石田亜佑美_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in 石田亜佑美['article']] 羽賀朱音_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in 羽賀朱音['article']] 横山玲奈_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in 横山玲奈['article']] 生田衣梨奈_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in 生田衣梨奈['article']] 小田さくら_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in 小田さくら['article']] 野中美希_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in 野中美希['article']] 森戸知沙希_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in 森戸知沙希['article']] 牧野真莉愛_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in 牧野真莉愛['article']] 加賀楓_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in 加賀楓['article']] 佐藤優樹_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in 佐藤優樹['article']] 鞘師里保_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in 鞘師里保['article']] ブログ_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in ブログ['article']] 飯窪春菜_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in 飯窪春菜['article']] 尾形春水_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in 尾形春水['article']] 工藤遥_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in 工藤遥['article']] 鈴木香音_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in 鈴木香音['article']]
一度すべてを
コメントアウトしてから、
やる人だけ外す。
# ふくちゃんの番 譜久村聖_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in 譜久村聖['article']] # 石田亜佑美_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in 石田亜佑美['article']] # 羽賀朱音_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in 羽賀朱音['article']] # 横山玲奈_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in 横山玲奈['article']] # 生田衣梨奈_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in 生田衣梨奈['article']] # 小田さくら_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in 小田さくら['article']] # 野中美希_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in 野中美希['article']] # 森戸知沙希_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in 森戸知沙希['article']] # 牧野真莉愛_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in 牧野真莉愛['article']] # 加賀楓_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in 加賀楓['article']] # 佐藤優樹_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in 佐藤優樹['article']] # 鞘師里保_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in 鞘師里保['article']] # ブログ_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in ブログ['article']] # 飯窪春菜_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in 飯窪春菜['article']] # 尾形春水_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in 尾形春水['article']] # 工藤遥_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in 工藤遥['article']] # 鈴木香音_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in 鈴木香音['article']]
# 譜久村聖_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in 譜久村聖['article']] # あゆみんの番 石田亜佑美_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in 石田亜佑美['article']] # 羽賀朱音_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in 羽賀朱音['article']] # 横山玲奈_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in 横山玲奈['article']] # 生田衣梨奈_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in 生田衣梨奈['article']] # 小田さくら_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in 小田さくら['article']] # 野中美希_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in 野中美希['article']] # 森戸知沙希_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in 森戸知沙希['article']] # 牧野真莉愛_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in 牧野真莉愛['article']] # 加賀楓_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in 加賀楓['article']] # 佐藤優樹_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in 佐藤優樹['article']] # 鞘師里保_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in 鞘師里保['article']] # ブログ_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in ブログ['article']] # 飯窪春菜_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in 飯窪春菜['article']] # 尾形春水_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in 尾形春水['article']] # 工藤遥_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in 工藤遥['article']] # 鈴木香音_tokens_list = [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in 鈴木香音['article']]
こんな感じで一つづつ様子をみる。
もう一度言いますが、 いっぺんにやろうとすると 30分以上はかかります。
もう一度言いますが、 いっぺんにやろうとすると 30分以上はかかります。
クラッシュに怯える
ちなみに、
ふくちゃんだけなら9分でした。
一番ブログの記事を書いている がんばり屋さんですが、 (あゆみんも肉薄している。)
単体で処理をすると短縮できます。(当然か)
ちなみに違ったやりかた も考えてみた。
一番ブログの記事を書いている がんばり屋さんですが、 (あゆみんも肉薄している。)
単体で処理をすると短縮できます。(当然か)
ちなみに違ったやりかた も考えてみた。
# yield文で返し、小分けにして取り出してやるぜぇ
# でも時間の総数は変わらないぜぇ
# マイルドだろぉ
def yield_sudachi(df_list):
for df in df_list:
yield [tokenizer_obj.tokenize(tokenizer.Tokenizer.SplitMode.C, article) for article in df['article'].tolist()]
# 使い方
# リストのスライスを使って、大体4分の1くらいの量をめざす!
tokens_list_by_author_quarter=yield_sudachi(split_by_author_df[:4])
# 一瞬で終わるが、tokens_list_by_authorの
# 正体は処理を待ち望んでいるジェネレーターだ!
# 確認してみるがよい!
import types
isinstance(tokens_list_by_author, types.GeneratorType)
---> True
# さあ、あとはちょこっとづつ取り出して、リストにアペンドしていくだけだ!
# ユニークな名前をつけておくのを忘れるな!
tokens_list_by_authors_quarter=[tlbaq for tlbaq in tokens_list_by_author_quarter]
# 範囲だけ先にリスト化していけばいいかも
# そんで空のリストにアペンドでもいいかもね
term_1=split_by_author_df[:4] # 0~3 4つ
term_2=split_by_author_df[4:8] # 4~7 4つ
term_3=split_by_author_df[8:13] # 8~12 4つ
term_4=split_by_author_df[13:] # 13~16 4つ
# 最初だけ用意
tokens_list_by_authors=[]
# 繰り返しながら時間の様子をみる。
# 結局メモリが足りなくなるとクラッシュするんだ慎重にな!
tokens_list_by_author=yield_sudachi(term_1)
tokens_list_by_authors.appned([tlba for tlba in tokens_list_by_author])
tokens_list_by_author=yield_sudachi(term_2)
tokens_list_by_authors.appned([tlba for tlba in tokens_list_by_author])
.........................
.........................
運良く帰還できたら、
我々が生きた証を残そう。
# みんなダイスキピックルが簡単に作れるよ!
import dill
# このままピックル(塩漬け)にすると
# エラーが起こり、ピックルにできねぇよ!と怒られるので、
# 不本意ですが一旦全て文字列にしておきます。
tokens_list_by_authors_list=[[[token.surface() for token in tokens] for tokens in tokens_list_by_author] for tokens_list_by_author in tokens_list_by_authors]
# ピックルピックル!
with open('../../tokens_list_by_authors_list.pkl','wb') as f:
dill.dump(tokens_list_by_authors_list,f)
これを次回からは、
# これで取り出せます。
with open('../../tokens_list_by_authors_list.pkl','rb') as f:
tokens_list_by_authors_list=dill.load(f)
今日はここまで!
See You Next Page !
See You Next Page !