Published Date : 2019年4月28日20:40
自然言語処理・其の弐
前回の記事の簡単なおさらい
続・感情分析
Google Colaboratory
前回のipython notebookを
開いて、必要な設定をし直そう。
下記サイトにアクセスし、 Googleアカウントでログイン。
https://colab.research.google.com/?hl=ja
今回は以下の画面で ファイルを選択するだけ。
下記サイトにアクセスし、 Googleアカウントでログイン。
https://colab.research.google.com/?hl=ja
今回は以下の画面で ファイルを選択するだけ。
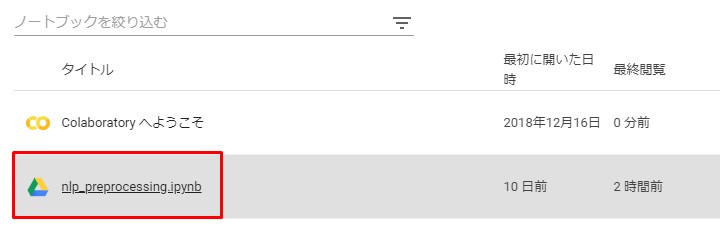
再びファイルをアップロード
Google Drive へアクセス
まずGoolge Driveへアクセスして、
https://drive.google.com/drive/my-drive
My Driveにファイルをアップしておきます。
Google Driveにアクセスしたら 「マイドライブ」を選択します。
https://drive.google.com/drive/my-drive
My Driveにファイルをアップしておきます。
Google Driveにアクセスしたら 「マイドライブ」を選択します。
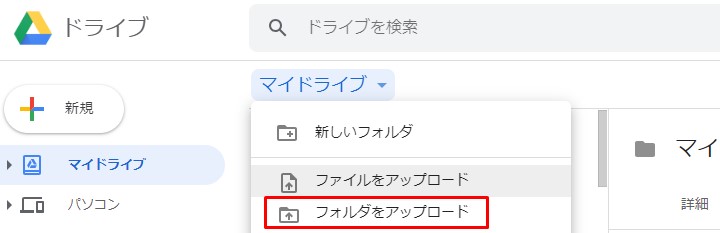
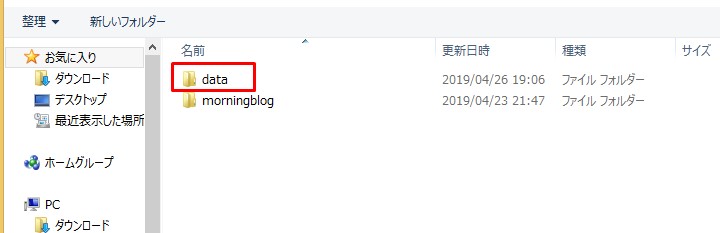
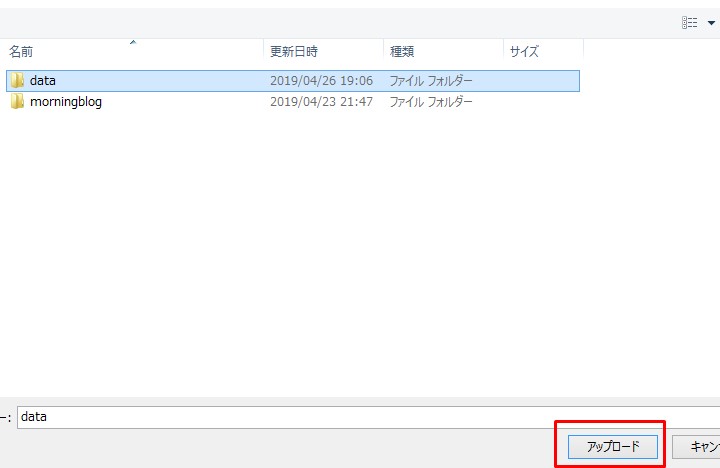
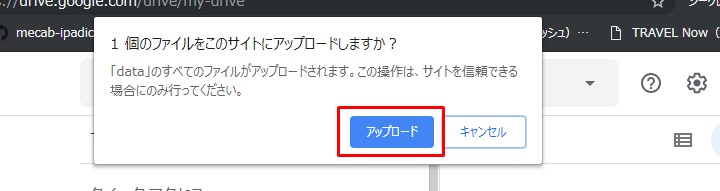
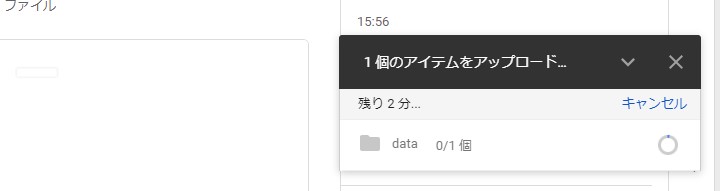
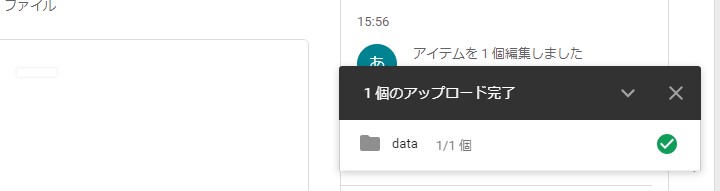
上の一連の流れで
アップロードが完了したら、
フォルダがあるか確認してみます。
フォルダがあるか確認してみます。
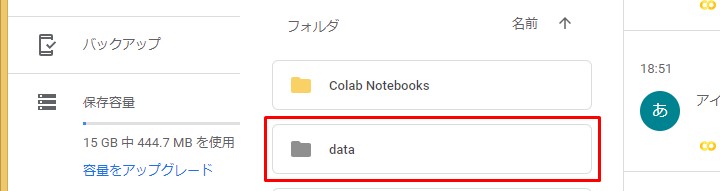
再びGoogle Colaboratoryへ
続いてColaboratoryに戻り、
以下のコードを実行。
以下のコードを実行。
from google.colab import drive
drive.mount('/content/drive')
すると、URLが出てくるので、
クリックしてアクセスしてね。
クリックしてアクセスしてね。
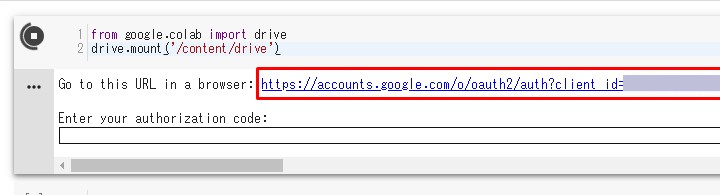
どのアカウントで入るか聞かれるので、
適当に選んで入ってね。
適当に選んで入ってね。
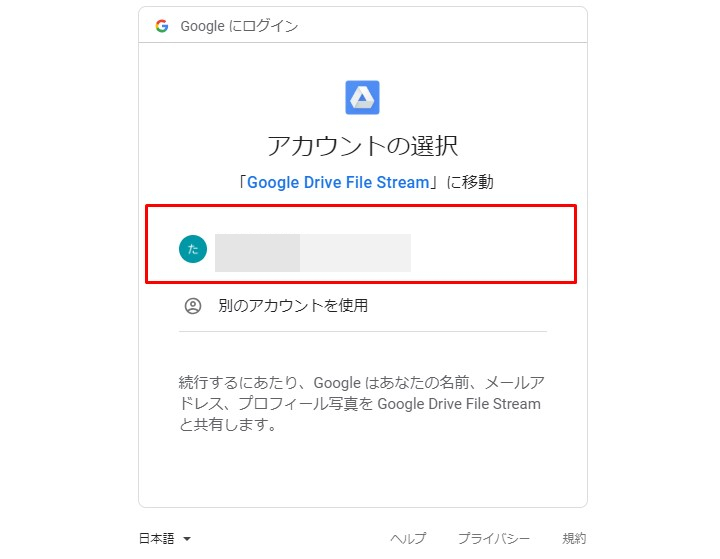
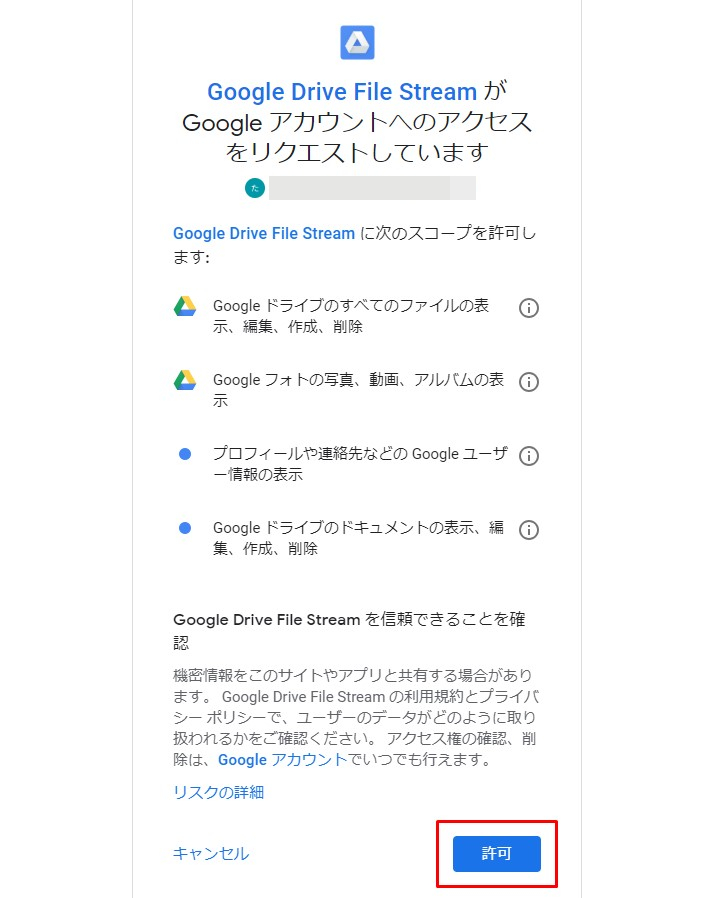
あとで設定し直すことができるので、
とりあえず使えるように許可しときます。
とりあえず使えるように許可しときます。
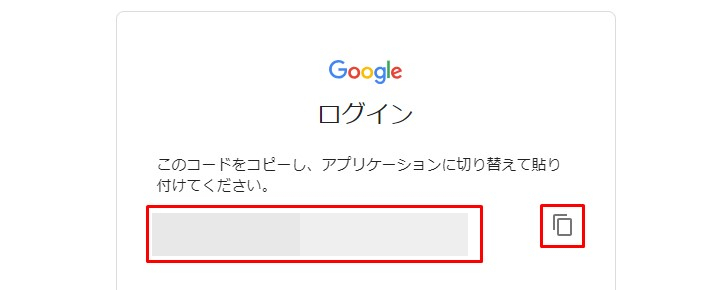
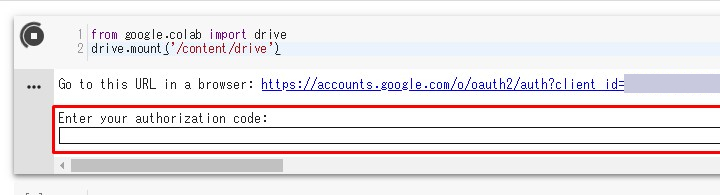
すると英数字がズラーっと出てきます。
必要なのでコピー。
必要なのでコピー。
Colaboratoryに戻り、
赤枠の部分へ貼り付け。
赤枠の部分へ貼り付け。
ENTERキーを叩け!!
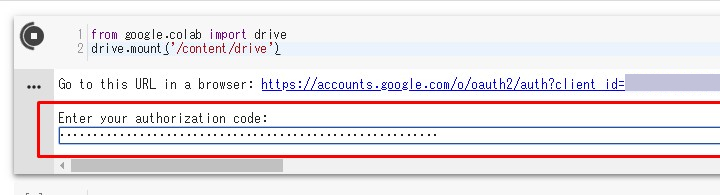
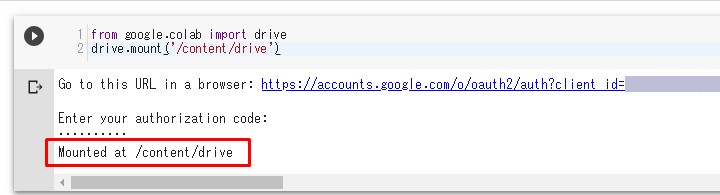
やり方が間違ってなければ
以下のように成功します。
以下のように成功します。
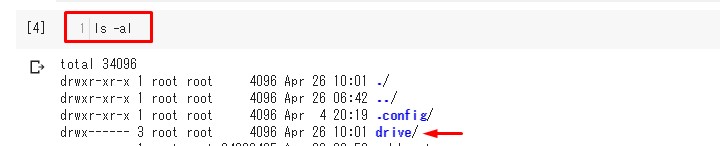
ちゃんとマイドライブが
認識されているか確認。



きちんとJSONファイルが
認識されてますね。
時間が経ち過ぎたり、 一回セッションアウトすると、 始めからやり直しになる。
でもGoogle Driveにあるファイルは 消えないので、前回みたいに ダウンロードで時間を食うこともなくなる。
時間が経ち過ぎたり、 一回セッションアウトすると、 始めからやり直しになる。
でもGoogle Driveにあるファイルは 消えないので、前回みたいに ダウンロードで時間を食うこともなくなる。
ブログ記事を召喚
Google Drive
をマウントできたら、
My Drive内の 目的のフォルダに移動しましょう。
My Drive内の 目的のフォルダに移動しましょう。
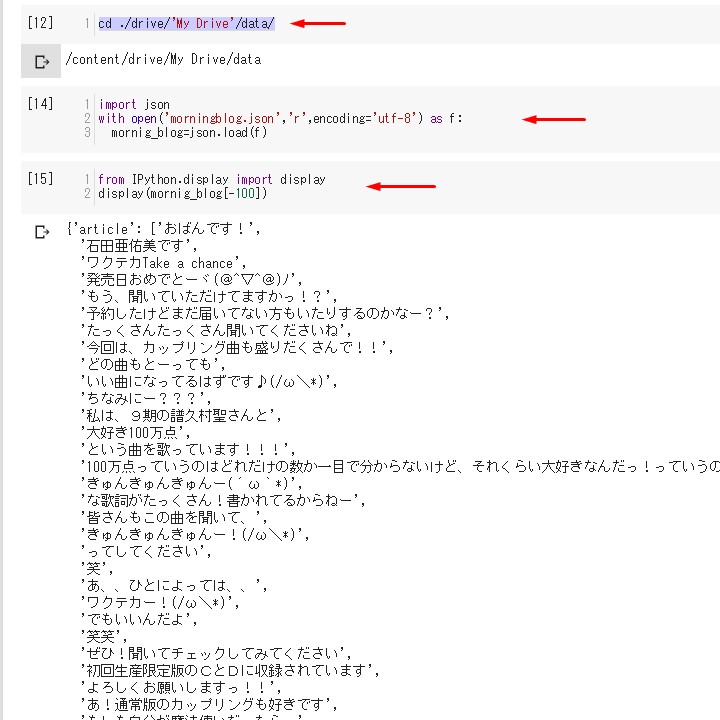
cd ./drive/'My Drive'/data/
再びJSONファイルを呼び込みます。
import json
with open('morningblog.json','r',encoding='utf-8') as f:
mornig_blog=json.load(f)
内容を表示させてみます。
今回は後ろから100番目の記事を選択。
今回は後ろから100番目の記事を選択。
from IPython.display import display display(mornig_blog[-100])
感情分析準備
!git clone https://github.com/sugiyamath/sentiment_ja
フォルダ内へ移動。
cd sentiment_ja
セットアップしてインストール。
!python setup.py install
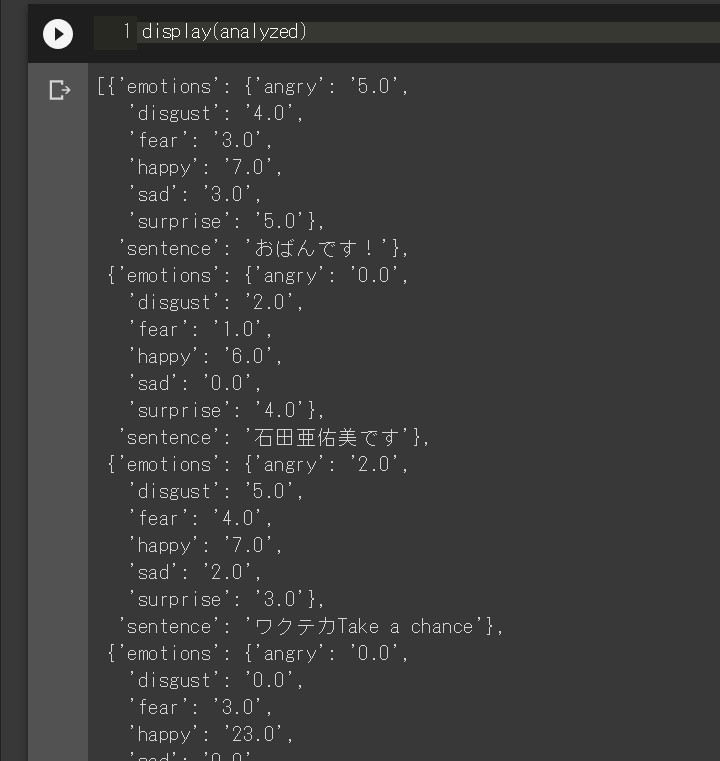
実験
一応確認だけしておきます。
適当に記事を選んで、 前回同様のコードで動かします。
適当に記事を選んで、 前回同様のコードで動かします。
# インストールしたsentimetjaからAnalyzerをインポート from sentimentja import Analyzer # Analyzerから感情分析するためのanalyzerオブジェクトを作成 analyzer = Analyzer() # 後ろから100番目の記事を取り出す。 senti_test=mornig_blog[-100]['article'] # 一行ごとに感情分析。 analyzed=analyzer.analyze(senti_test) # 表示してみる display(analyzed)
グラフ表示
グラフの準備の前に、
日本語を表示できるようにします。
!pip install japanize-matplotlib
重複しますが、また一から
グラフを表示してみましょう。
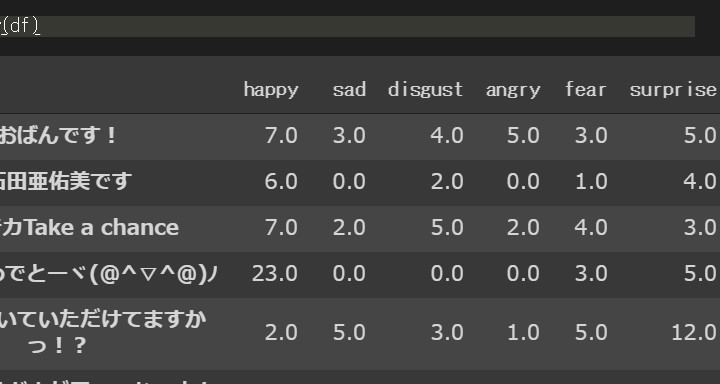
# データをいっぺんに処理するためPandasをインポート import pandas as pd # グラフツールのライブラリを長いので短い名前にしてインポート import matplotlib.pyplot as plt # 日本語を表示してくれる import japanize_matplotlib # 軽くグラフを表示してくれるマジックコマンド % matplotlib inline # 表題をメンバーの名前と日付にする。 plot_title=mornig_blog[-100]['author']+mornig_blog[-100]['date'] # 感情表記6種類をデータフレームの列名にする。 columns=list(analyzed[0]['emotions'].keys()) # Index番号を感情分析の元の文章にする。 sentence=[a['sentence'] for a in analyzed] # 平均や比率を計算するのに、DataFrameにすると便利なので変換する df=pd.DataFrame([list(a['emotions'].values()) for a in analyzed],index=sentence,columns=columns)
データフレームの中身はこんな感じ。
コードの続き。
# 合計値をリストにする。
emotions_sum=[df[dc].apply(float).sum() for dc in df.columns]
# 感情ごとの比率をリスト化していく。
rate=[esum/sum(emotions_sum) for esum in emotions_sum]
senti_rate=dict(map(list,zip(df.columns.tolist(),rate)))
# 感情の種類と対応する比率をパーセンテージに直して表記させる。
xlabels=[f'{key} \n {round(value*100)}%' for key,value in senti_rate.items()]
# グラフの表示。
# X軸に「仮」の名前をつけてグラフの骨組みを作っておくための作業。
x=[i+1 for i in range(len(xlabels))]
# Y軸は感情の合計値。
y=emotions_sum
# 表題は書いた人の名前と日付。
plt.title(plot_title)
# X,Yを指定してグラフの型を作り、
# 感情の名前と比率をXラベルとして貼り付ける。
plt.bar(x,y,tick_label=xlabels)
# グラフ表示させる
plt.show()
こんな感じ。
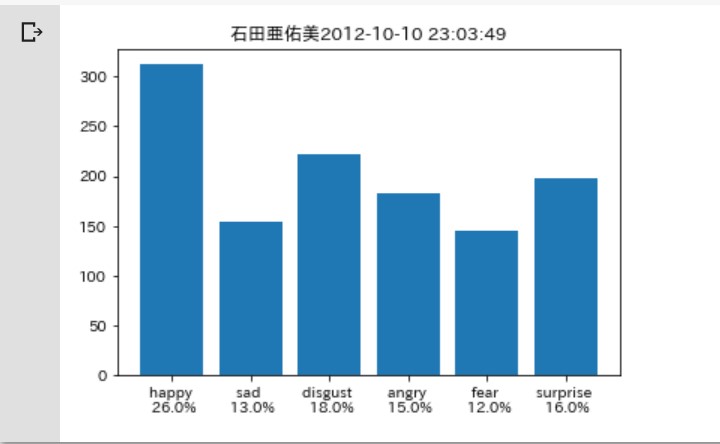
やり方を変えてみる
今度は文章をタイトルにして、
一行ごとにグラフ表示をしていきましょう。
# タイトルを文章にする。
plot_title=df.index.tolist()
# 合計値をリストにする。
emotions_sum=[df.iloc[i].apply(float).sum() for i in range(df.shape[0])]
# 感情ごとの比率をリスト化していく。
rate=[df.iloc[i].apply(lambda x: float(x)/esum) for i,esum in enumerate(emotions_sum)]
senti_rate=[dict(map(list,zip(r.index.tolist(),r.tolist()))) for r in rate]
# 感情の種類と対応する比率をパーセンテージに直して表記させる。
xlabels=[[f'{key} \n {round(value*100)}%' for key,value in sr.items()] for sr in senti_rate]
# グラフの表示。
for num,pt in enumerate(plot_title):
# X軸に「仮」の名前をつけてグラフの骨組みを作っておくための作業。
x=[i+1 for i in range(len(xlabels[num]))]
# Y軸は各行の感情値のリスト。
y=df.iloc[num].apply(float).tolist()
# タイトルは一行ごとの文章。
plt.title(pt)
# X,Yを指定してグラフの型を作り、
# 感情の名前と比率をXラベルとして貼り付ける。
plt.bar(x,y,tick_label=xlabels[num])
# グラフ表示させる
plt.show()
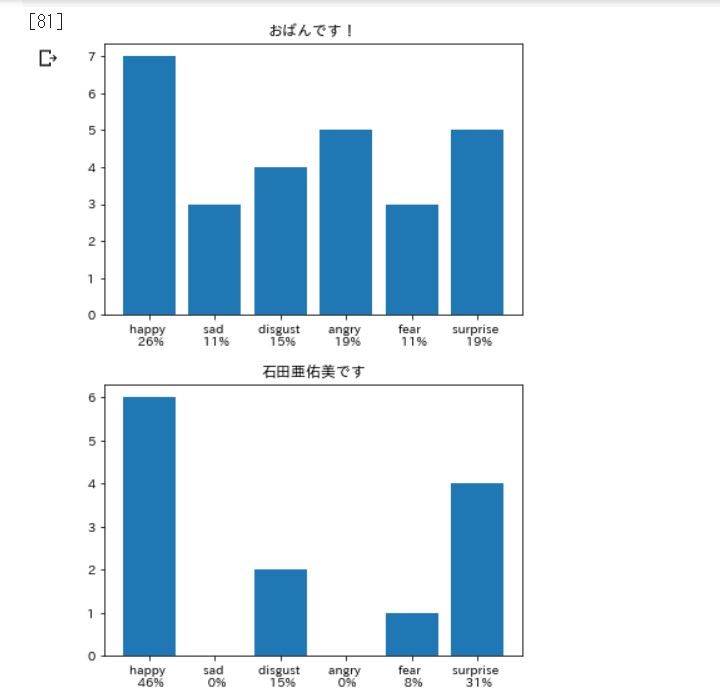
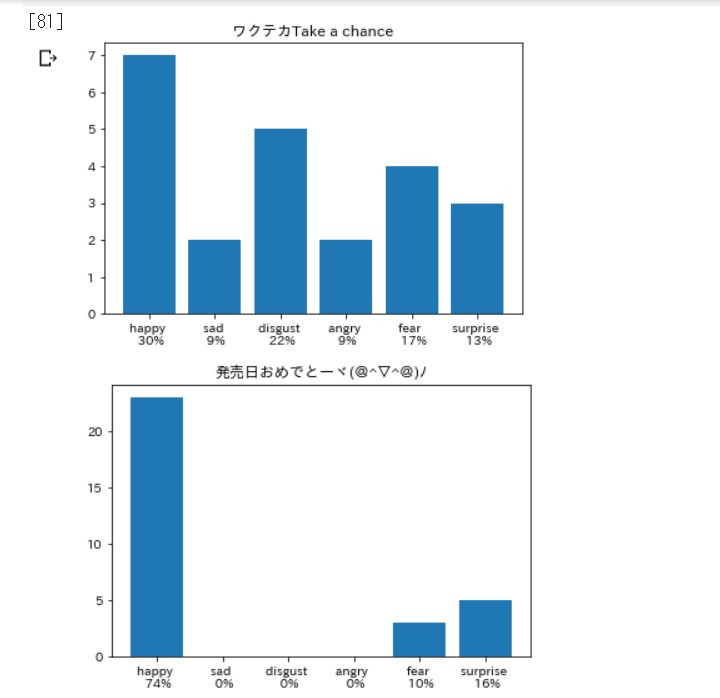
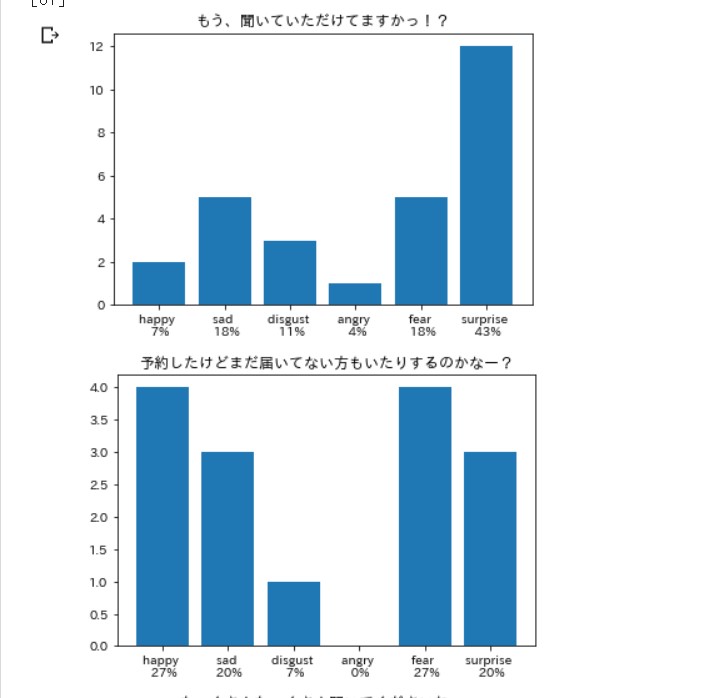
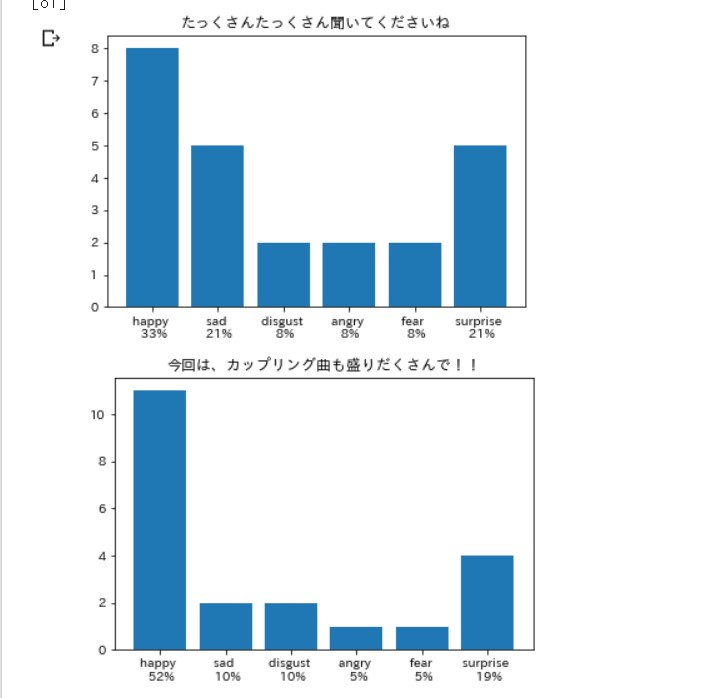
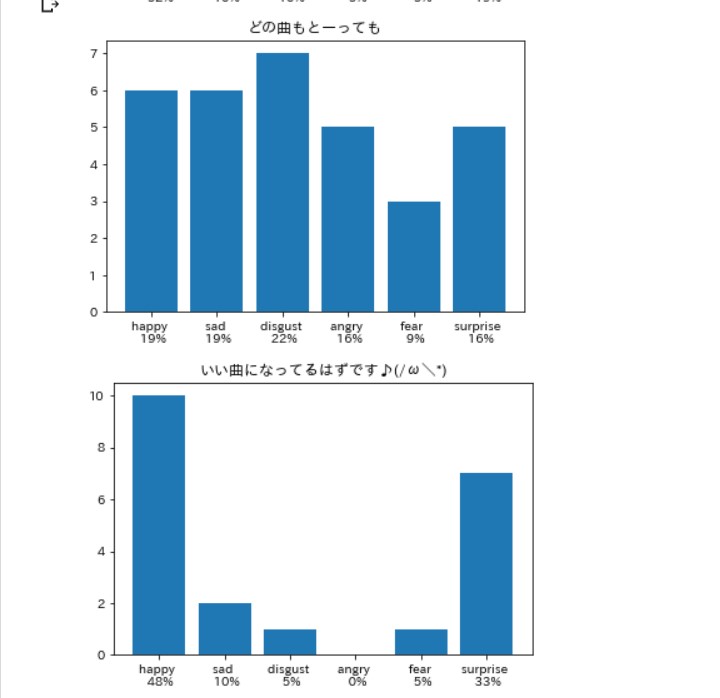
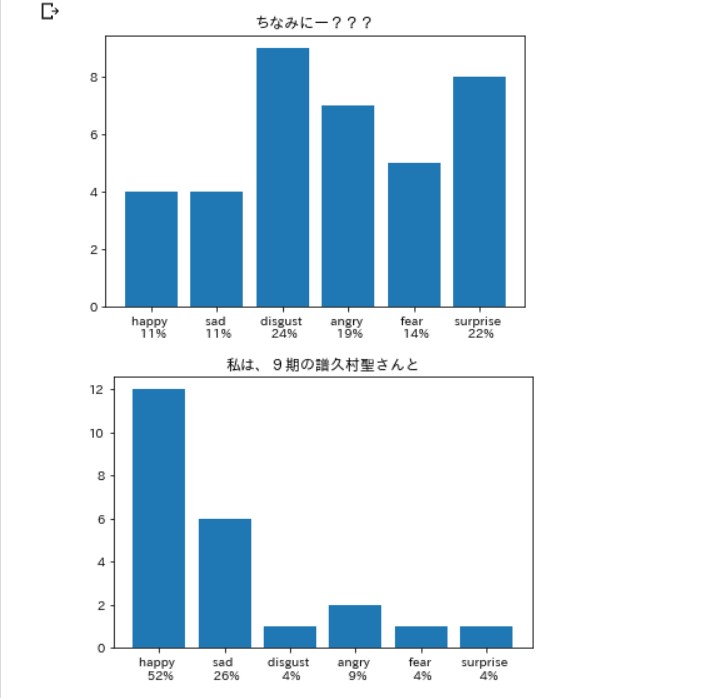
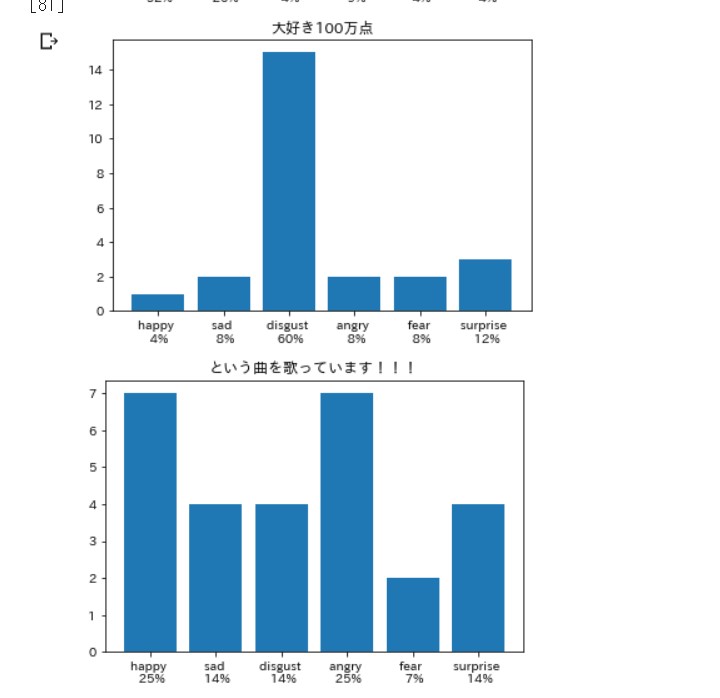
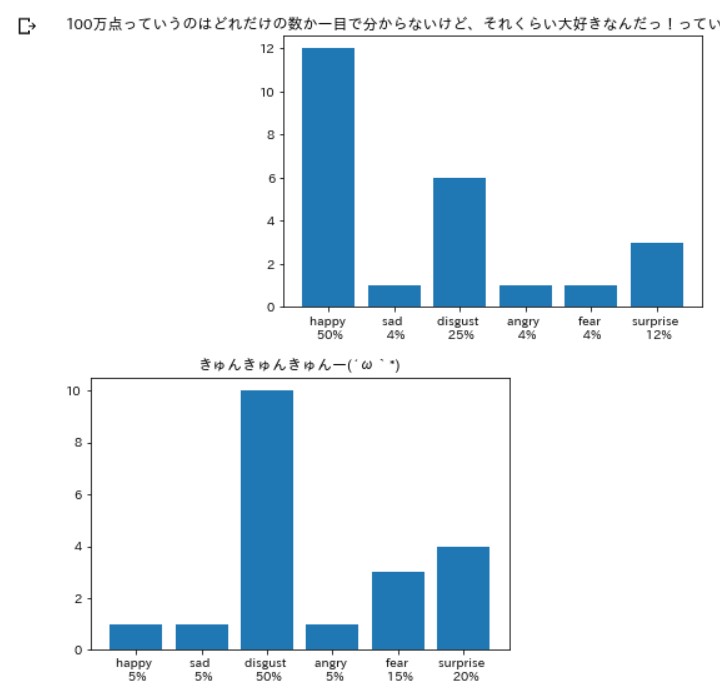
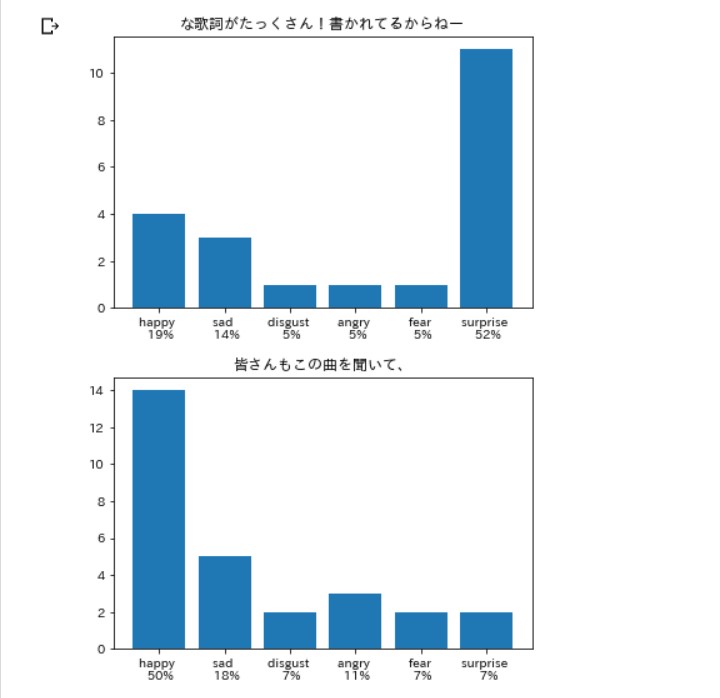
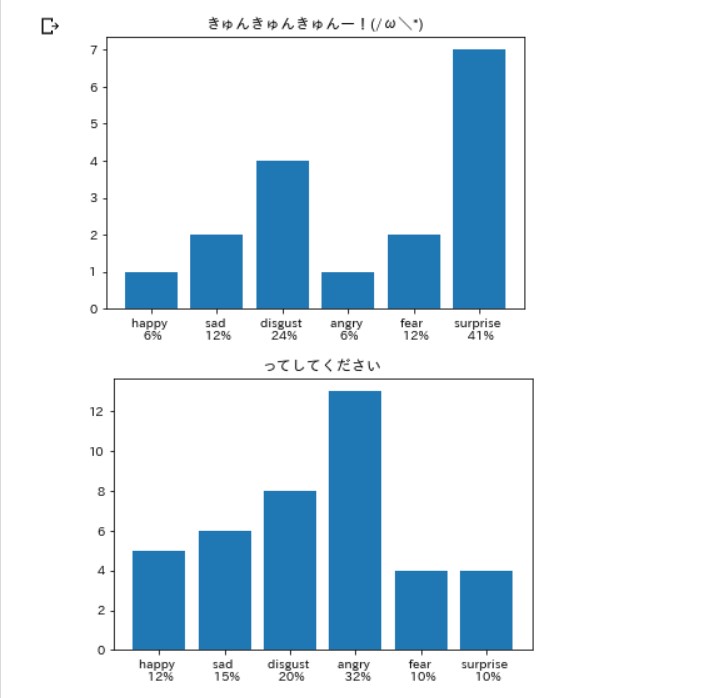
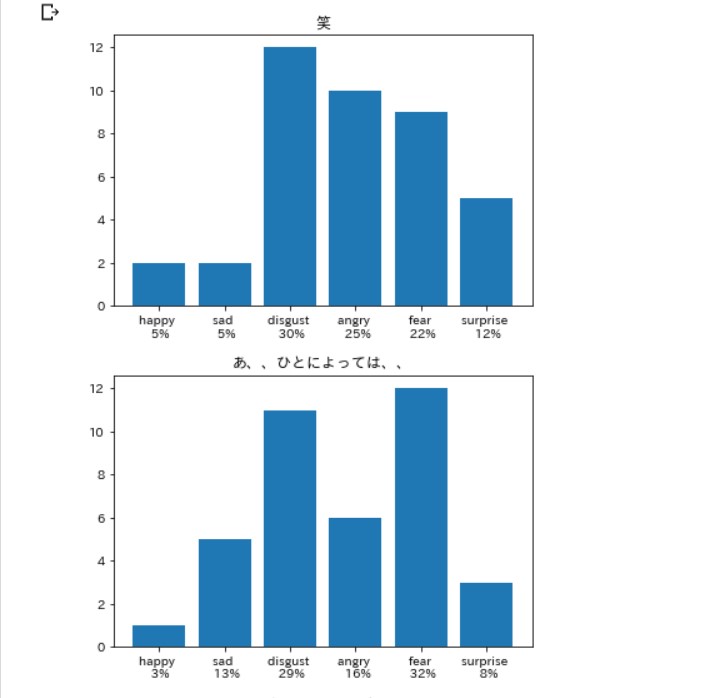
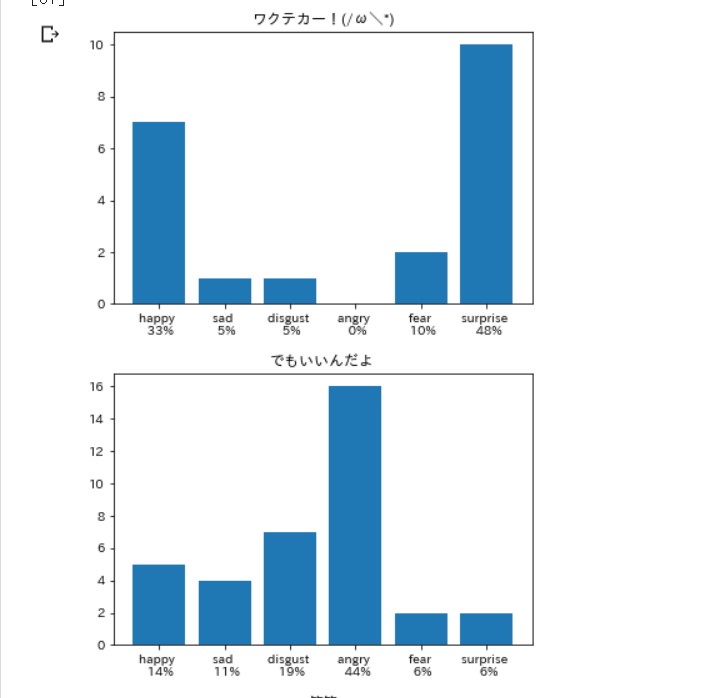
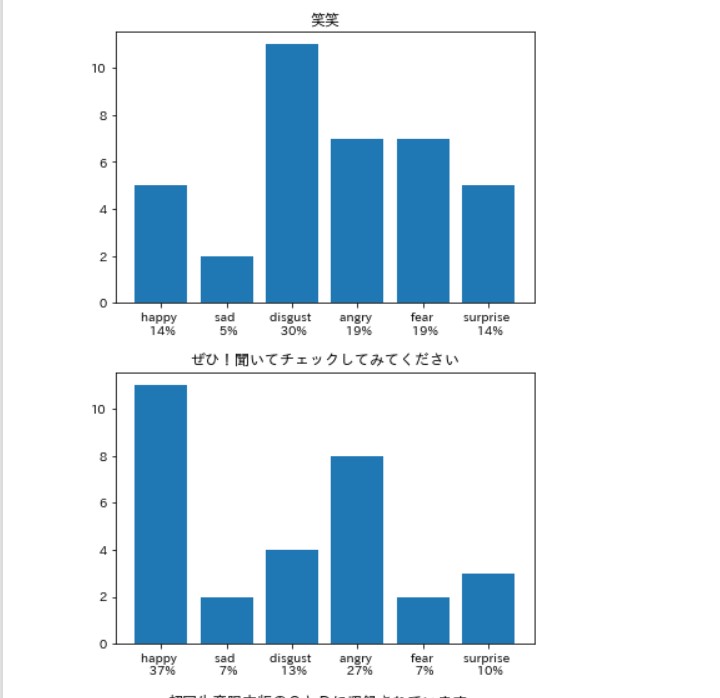
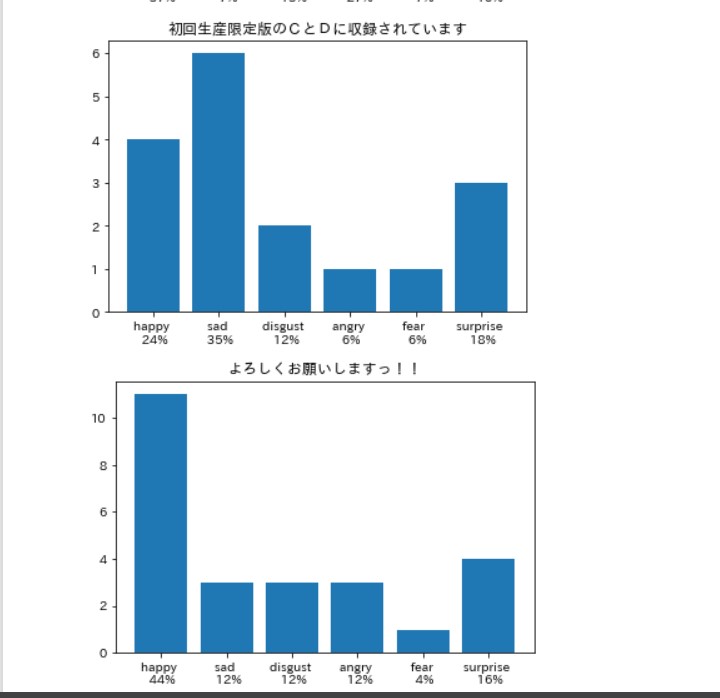
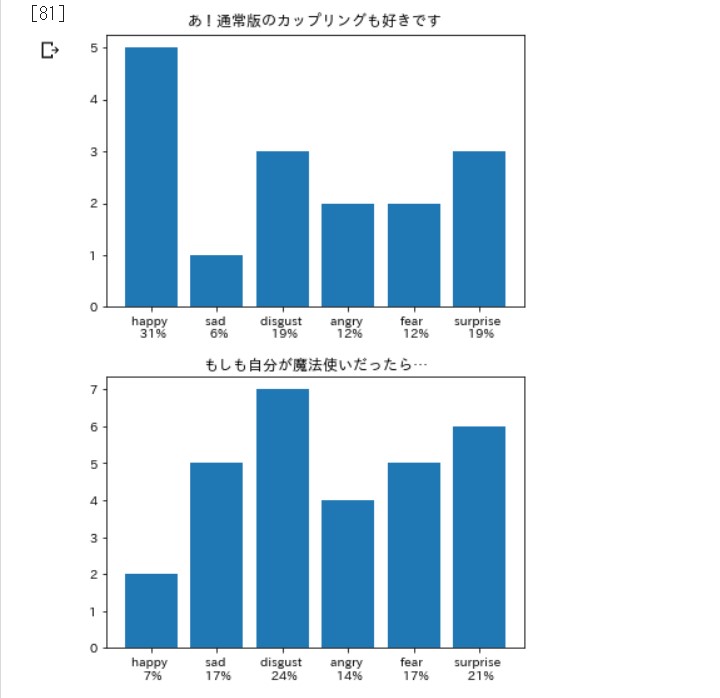
笑いは嫌悪率が高いらしい。
なんかネタにしかなりそうにない
雰囲気です。。。
なにはともあれ、
全メンバーの年ごとの 感情分析していこうかな。。。
なにはともあれ、
全メンバーの年ごとの 感情分析していこうかな。。。
年間表示
とりあえず、
年間ごとにメンバーと記事を分けます。
やり方は年ごとにデータフレームを 作っていくだけです。
やり方は年ごとにデータフレームを 作っていくだけです。
# メンバー全員の記事をデータフレームにするため、 # 一旦すべての記事を改行で繋げて、リストから文字列にする。 newline_articles=['\n'.join(mb['article']) for mb in mornig_blog] # データフレームにしていく。 blog_df=pd.DataFrame([[mb['author'],mb['title'],mb['date'],newline_articles[i]] for i,mb in enumerate(mornig_blog)],columns=list(mornig_blog[0].keys())) # 確認 display(blog_df)
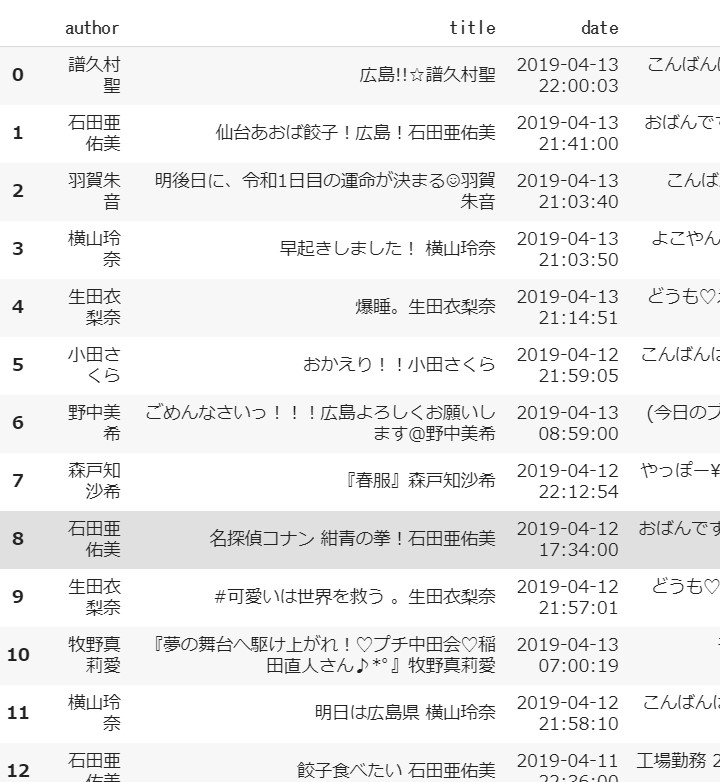
時間などの計算と操作がしやすいように、
date列に入っている文字列を、
Datetimeオブジェクトに変換する。
date列に入っている文字列を、
Datetimeオブジェクトに変換する。
# pandasのto_datetimeメソッドを使い、 # すべてのdate列の文字列をdatetimeオブジェクトに変換した後、 # 元のdate列と入れ替える。 blog_df['date']=pd.to_datetime(blog_df['date']) # ちゃんと変化してるか確かめる。 blog_df.info()
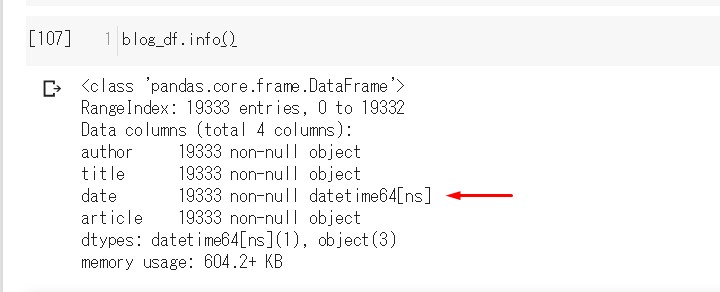
年を分けテカCHANCE
# 年ごとの詳細をみてみる。 blog_df['date'].apply(lambda x: x.year).unique()

# 記事が存在する年のリストを作る。 # uniqueメソッドは同じ年を一つにまとめる。 #「2019年、2019年、2018年」ー> 「2019年、2018年」 unique_year=blog_df['date'].apply(lambda x: x.year).unique() # そのリストを使って年ごとにデータフレームを分けていく。 # lambdaは無名関数と言って、一行程度の短い関数を書く時に便利。 # pandasのapplyメソッドは、指定した列にある値一つ一つに、 # 関数を働かせることができる便利なやつ。 # data列の値をlambda関数に渡して、リストにある年と合ってるなら、 # そのデータフレームの一行を取り出す。 # リスト内包表記を使い、年ごとのデータフレームのリストにする。 split_by_year_df=[blog_df[blog_df['date'].apply(lambda x: x.year == uy)==True] for uy in unique_year]
ちゃんと分けられているか確認。
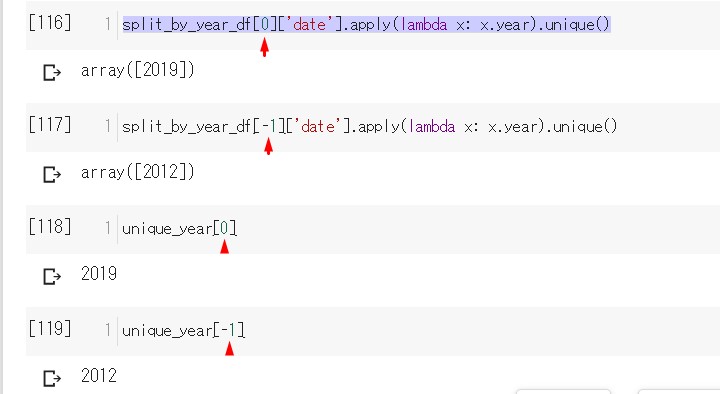
インデックス番号と
一致してるので大丈夫そう。
取り調べ
2019年の結果を見ていきます。
# groupbyメソッドは指定した列の情報をまとめる。
# countメソッドを使って数を確認する。
# インデックス番号「0」は先程確認した通り今年2019年。
split_by_year_df[0].groupby('author').count()
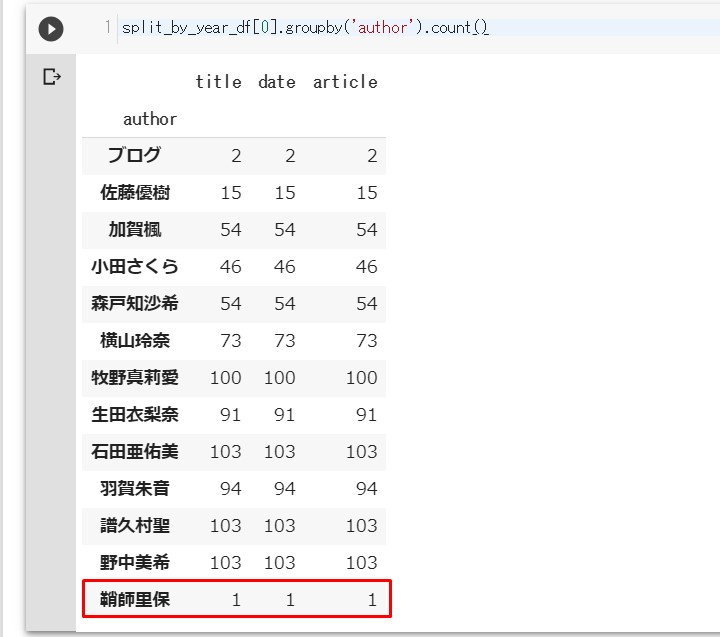
あれ?りほりほ??
説明しよう!
りほりほとは!
鞘師里保(さやしりほ) wikipediaを読め!
簡単に説明すると過去にいたメンバー、 絶対的エースだった。
2015年の年末に卒業した。
かつ昨年末にアップフロントとの マネジメント契約が終了。
ハロプロも卒業し、我々は絶望していた。
では何故今年のブログに名前が あるのかというと、以下がそのからくり。
説明しよう!
りほりほとは!
鞘師里保(さやしりほ) wikipediaを読め!
簡単に説明すると過去にいたメンバー、 絶対的エースだった。
2015年の年末に卒業した。
かつ昨年末にアップフロントとの マネジメント契約が終了。
ハロプロも卒業し、我々は絶望していた。
では何故今年のブログに名前が あるのかというと、以下がそのからくり。


つまり、今年の3月30日に行われた、
「ひなフェス」というハロプロのイベントで、
「りほりほ」はゲストととして出演し、 「りほりほ復活!」と相成った訳だ。
そこで、同期メンバー(9期)である
譜久村聖(ふくむら みずき)さん、 生田衣梨奈(いくた えりな)さん が同期の絆の証として、
著者「鞘師里保」で、 「りほりほ復活」の記事を書いたという訳ですね。はい。
「りほりほ」はゲストととして出演し、 「りほりほ復活!」と相成った訳だ。
そこで、同期メンバー(9期)である
譜久村聖(ふくむら みずき)さん、 生田衣梨奈(いくた えりな)さん が同期の絆の証として、
著者「鞘師里保」で、 「りほりほ復活」の記事を書いたという訳ですね。はい。
2019年の純情な感情分析
ということで、名残惜しいですが、
「ブログ」と「鞘師里保(りほりほ)」以外で
2019年の3分の1のブログ記事感情分析をしていきます。
2019年の3分の1のブログ記事感情分析をしていきます。
# 2019年のみのデータフレームを抜き出す。
df_2019=split_by_year_df[0]
# 「りほりほ」と「ブログ」以外を対象にするため、論理演算を使い振り分ける。
df_2019=df_2019[(df_2019['author']!='鞘師里保') & (df_2019['author']!='ブログ')]
# 'author'ごとにデータフレームを分けてリストにする。
df_2019_list=[df_2019[df_2019['author']==dau] for dau in df_2019['author'].unique()]
# メンバーごとの記事を、
# 改行で分割したリストにして、
# 一つの記事の一行ずつを感情分析していく。
analyzed_list=[[analyzer.analyze(article) for article in dl['article'].apply(lambda x: x.split('\n')).tolist()] for dl in df_2019_list]
# 後は前回とほぼ同じやり方でメンバーごとに2019年の3分の1の感情分析
# analyzed_listの最初のインデックス番号は
# df_2019_listの「'author'」の順番と対応している。
# 感情分析した辞書をデータフレームに直し、リスト化する。
analyzed_dfs_list=[[pd.DataFrame([d['emotions'] for d in a]) for a in al] for al in analyzed_list]
# データフレームのリストから3回リスト内包表記を使い
# メンバー順に感情値の合計のリストを格納していく
senti_list_2019=[[[a[col].apply(float).sum() for col in a.columns] for a in adf] for adf in analyzed_dfs_list]
こんな感じどぅぇす。
# 行列計算が簡単にできるようにnumpyをインポート import numpy as np # メンバーごとの感情値のリストをnumpy arrayにする。 senti_nplist_2019=[np.array(sl) for sl in senti_list_2019] # 合計値をリストにしてメンバー分格納。 # axis=0 は列方向に進んでいくって意味 # 列,列,列,列,列,列 # 行[1, 2, 3, 4, 5, 6] | # 行[1, 2, 3, 4, 5, 6] | # 行[1, 2, 3, 4, 5, 6] V # 結果 # 行[3, 6, 9, 12, 15, 18] emotoins_list=[snl.sum(axis=0) for snl in senti_nplist_2019]
こんな感じどぅぇす。
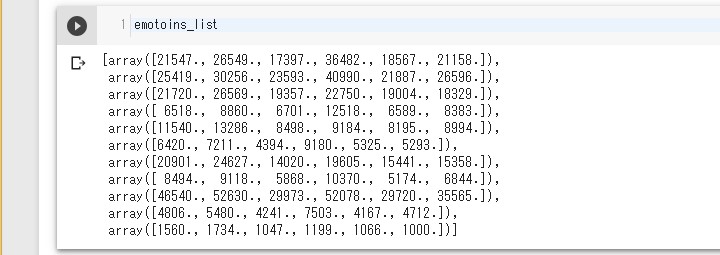
# 感情ごとの比率をリスト化していく。
rate_list=[[e/sum(el) for e in el] for el in emotoins_list]
# 処理しやすいように、メンバーと感情表記6種類のリストを用意しておく。
authors=[df_2019['author'].unique().tolist()[0] for df_2019 in df_2019_list]
columns=list(analyzed_list[0][0][0]['emotions'].keys())
# 感情の種類と対応する比率をパーセンテージに直して表記させる。
xlabels=[[f'{columns[i]} \n {round(r*100)}%' for i,r in enumerate(rl)] for rl in rate_list]
# メンバーの記事ごとにグラフに表示していく。
for i,rl in enumerate(rate_list):
# X軸に「仮」の名前をつけてグラフの骨組みを作っておくための作業。
x=range(len(columns))
# Y軸はそれぞれの感情の合計値。
y=rl
# 表題は書いた人の名前と西暦。
plt.title(f'{authors[i]} 2019')
# X,Yを指定してグラフの型を作ったのち、ラベル、
# つまり、感情の名前と比率を貼り付ける。
plt.bar(x,y,tick_label=xlabels[i])
# 一つずつグラフ表示させる
plt.show()
怒りと悲しみ
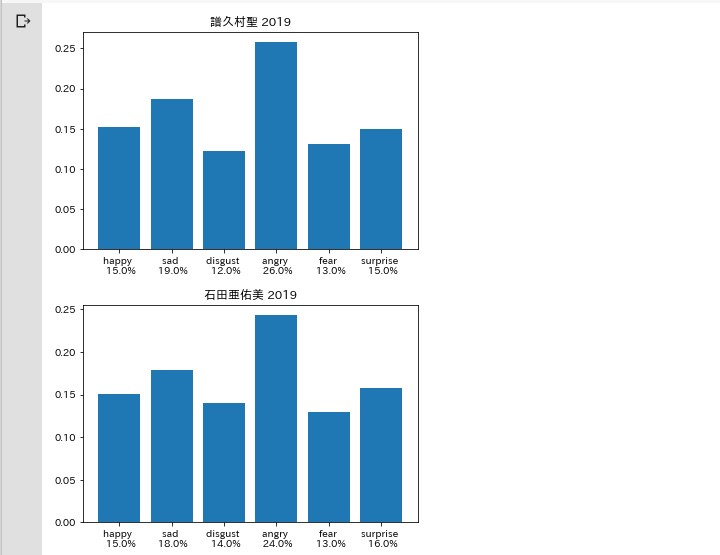
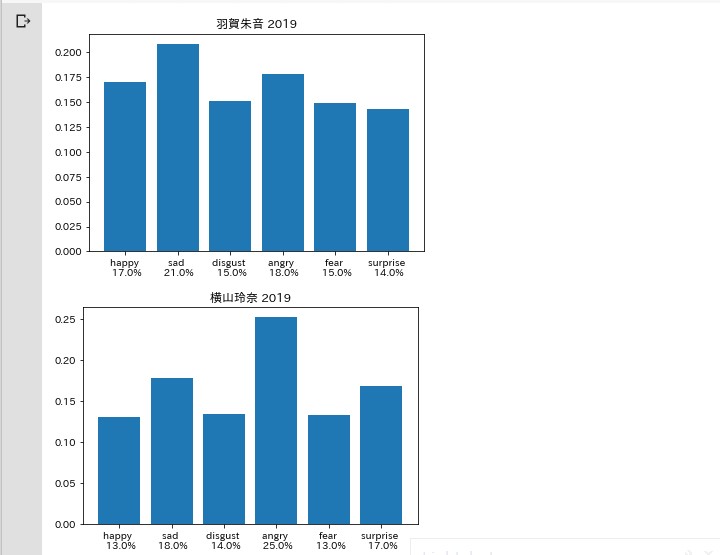
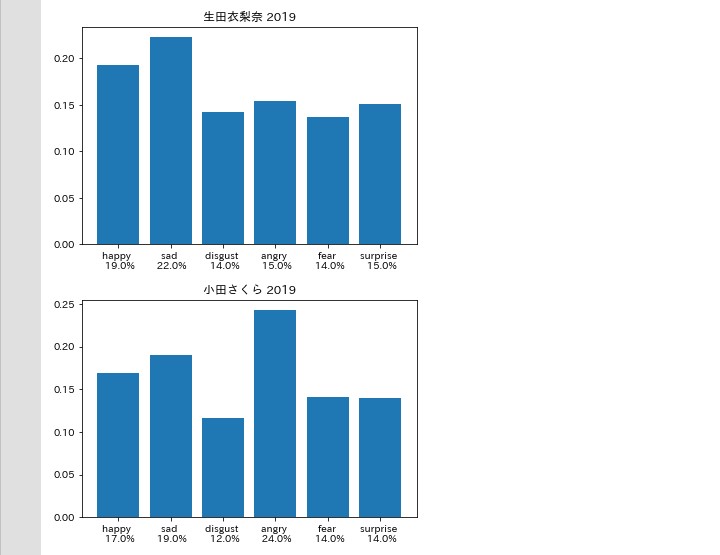
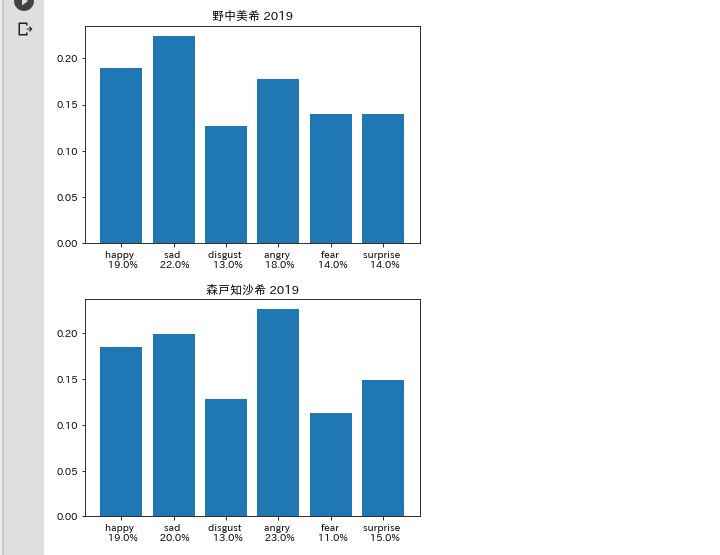
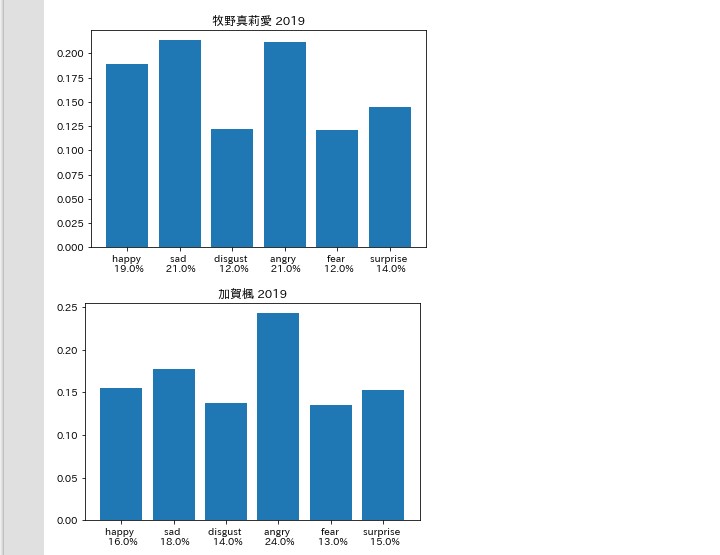
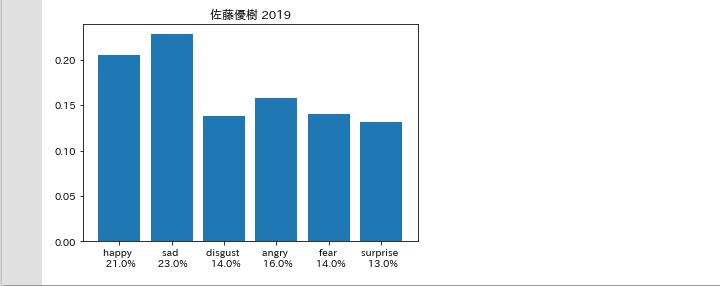
考察
なんじゃこりゃあ!(松田優作)
気を取り直して折れ線グラフ
# グラフの全体サイズの調整に必要
from pylab import rcParams
# グラフの全体サイズの調整
rcParams['figure.figsize'] = 10,10
# X軸のメモリを決める
x=range(1,len(columns)+1)
# Y軸のメモリ間隔を決める
y_ticks=np.array([i for i in range(10,28,2)])/100
# メンバーごとの折れ線グラフを作っていく。
for i,rl in enumerate(rate_list):
plt.plot(x, rl, marker = 'o', label = authors[i])
# X軸のメモリ間隔を決める
plt.xticks(x, columns)
# X軸のメモリ幅を決める
plt.xlim(0, len(columns)+1)
# Y軸のメモリ幅を決める
plt.ylim(0.1, 0.28)
# Y軸のメモリ間隔を決める
plt.yticks(y_ticks)
# グラフのタイトル
plt.title('感情分析 2019年', fontsize = 18)
# X軸のタイトル
plt.xlabel('emotions', fontsize = 18)
# Y軸のタイトル
plt.ylabel('rate', fontsize = 18)
# X軸とY軸のメモリの文字の大きさを決める
plt.tick_params(labelsize=15)
# グリッドを表示させる。(網の目のような線)
plt.grid(True)
# 凡例を表示させる。
# どのメンバーがどの色の折れ線グラフか分かりやすくなる。
# locで右上に表示させると知らせ、フォントサイズを15pxにする。
plt.legend(loc = 'upper right',fontsize=15)
# グラフの表示
plt.show()
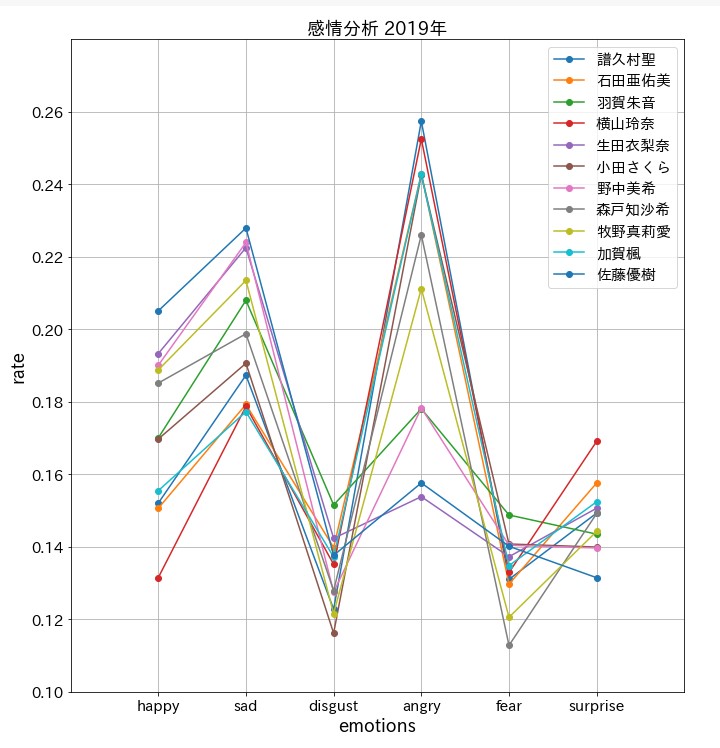
2012年から2019年へ
2012から2019年まで一気に
グラフ表示してみましょうか。
# 'author'ごとにデータフレームを分けてリストにする。
df_year_list=[[df_year[df_year['author']==dau] for dau in df_year['author'].unique()] for df_year in split_by_year_df]
# メンバーごとの記事を、
# 改行で分割したリストにして、
# 一つの記事の一行ずつを感情分析していく。
# 時間かかります!
analyzed_year_list=[[[analyzer.analyze(article) for article in dl['article'].apply(lambda x: x.split('\n')).tolist()] for dl in df_year] for df_year in df_year_list]
# 1 df_year_listには2012〜2019年の8年分のリストがあり、
# 2 analyzed_year_listには2012〜2019年の8年分のリストがあり、
display(len(df_year_list),len(analyzed_year_list))
out -> 8
-> 8
# 1 df_year_list さらに1年の中に、それぞれのメンバー分のリストがあり、
# 2 analyzed_year_list さらに1年の中に、それぞれのメンバー分のリストがあり、
display(len(df_year_list[0]),len(analyzed_year_list[0]))
out -> 13
-> 13
# 1 df_year_list メンバーのリストの中に、一つずつ記事の"データフレーム"がある。
# 2 analyzed_year_list メンバーのリストの中に、一つずつ記事のリストがあり、
display(len(df_year_list[0][0]),len(analyzed_year_list[0][0]))
out -> 103
-> 103
# 2 analyzed_year_list その記事のリストの中に一行ずつ感情分析した辞書が格納してある。
# 確認
display(analyzed_year_list[0][0][0][0]['emotions'])
out -> {'angry': '2.0',
'disgust': '4.0',
'fear': '2.0',
'happy': '4.0',
'sad': '2.0',
'surprise': '4.0'}
# 確認2
display(analyzed_year_list[0][0][0][0])
out -> {'emotions': {'angry': '2.0',
'disgust': '4.0',
'fear': '2.0',
'happy': '4.0',
'sad': '2.0',
'surprise': '4.0'},
'sentence': 'こんばんぽ(*´∀`*)ノん'}
# analyzed_year_list[0 -> 2012年]
# [0 -> その年のメンバー一人目記事全て]
# [0 -> 一つの記事の感情分析のリスト]
# [0 -> 感情分析結果の辞書]
# 感情分析した辞書をデータフレームに直し、8年分のリストにする。 analyzed_year_dfs_list=[[[pd.DataFrame([d['emotions'] for d in a]) for a in al] for al in ayl ]for ayl in analyzed_year_list] # データフレームのリストから4回リスト内包表記を使い # 年別、メンバー順に感情値の合計のリストを格納していく senti_year_list=[[[[a[col].apply(float).sum() for col in a.columns] for a in adf] for adf in aydf] for aydf in analyzed_year_dfs_list]
こんな感じどぅぇす。
# 年別、メンバーごとの感情値のリストをnumpy arrayにする。 senti_nplist_year_list=[[np.array(sl) for sl in syl] for syl in senti_year_list] # 合計値をリストにしてメンバー分格納。 # axis=0 は列方向に進んでいくって意味 # 列,列,列,列,列,列 # 行[1, 2, 3, 4, 5, 6] | # 行[1, 2, 3, 4, 5, 6] | # 行[1, 2, 3, 4, 5, 6] V # 結果 # 行[3, 6, 9, 12, 15, 18] emotoins_year_list=[[snl.sum(axis=0) for snl in snyl] for snyl in senti_nplist_year_list]
こんな感じどぅぇす。
# 年ごと、メンバーごとの感情の比率をリスト化していく。 rate_year_list=[[[e/sum(el) for e in el] for el in eyl] for eyl in emotoins_year_list] # 処理しやすいように、年別のメンバーと感情表記6種類のリストを用意しておく。 authors=[[dl['author'].unique().tolist()[0] for dl in dyl] for dyl in df_year_list] columns=list(analyzed_year_list[0][0][0][0]['emotions'].keys())
数が多いのでまとめて表示
# グラフの全体サイズの調整に必要
from pylab import rcParams
# グラフの全体サイズの調整
rcParams['figure.figsize'] = 12,12
# all year show
for num,author in enumerate(authors):
# X軸のメモリを決める
x=range(1,len(columns)+1)
# Y軸のメモリ間隔を決める
y_ticks=np.array([i for i in range(10,35,5)])/100
# メンバーごとの折れ線グラフを作っていく。
for i,rl in enumerate(rate_year_list[num]):
plt.plot(x, rl, marker = 'o', label = author[i])
# X軸のメモリ間隔を決める
plt.xticks(x, columns)
# X軸のメモリ幅を決める
plt.xlim(0, len(columns)+1)
# Y軸のメモリ幅を決める
plt.ylim(0.1, 0.35)
# Y軸のメモリ間隔を決める
plt.yticks(y_ticks)
# グラフのタイトル
plt.title(f'感情分析 201{9-num}年', fontsize = 18)
# X軸のタイトル
plt.xlabel('emotions', fontsize = 18)
# Y軸のタイトル
plt.ylabel('rate', fontsize = 18)
# X軸とY軸のメモリの文字の大きさを決める
plt.tick_params(labelsize=15)
# グリッドを表示させる。(網の目のような線)
plt.grid(True)
# 凡例を表示させる。
# どのメンバーがどの色の折れ線グラフか分かりやすくなる。
# locで右上に表示させると知らせ、フォントサイズを15pxにする。
plt.legend(loc = 'upper right',fontsize=15)
# グラフの表示
plt.show()
怒っているんじゃない!興奮してるんだ!
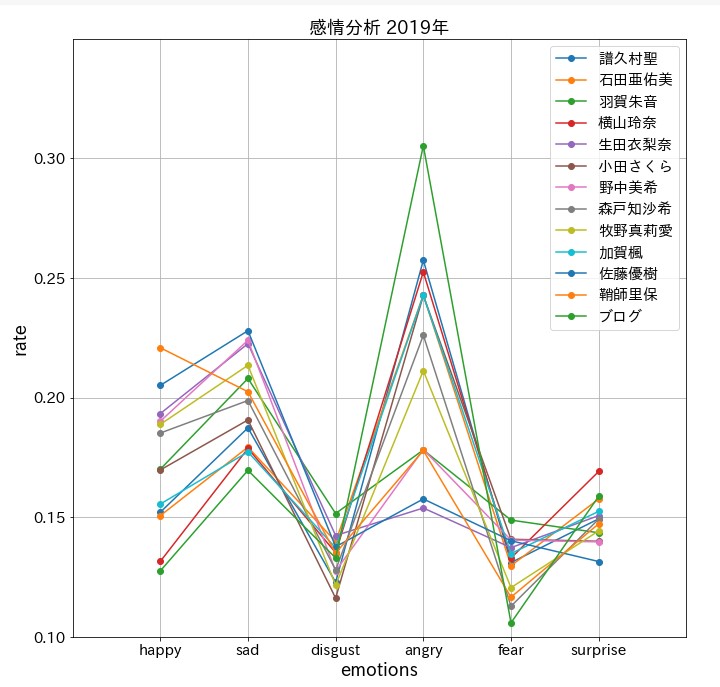
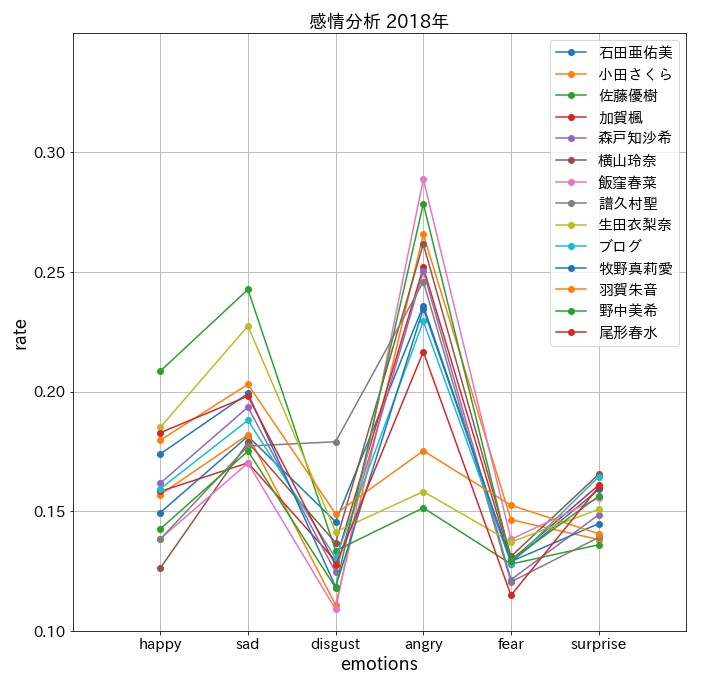
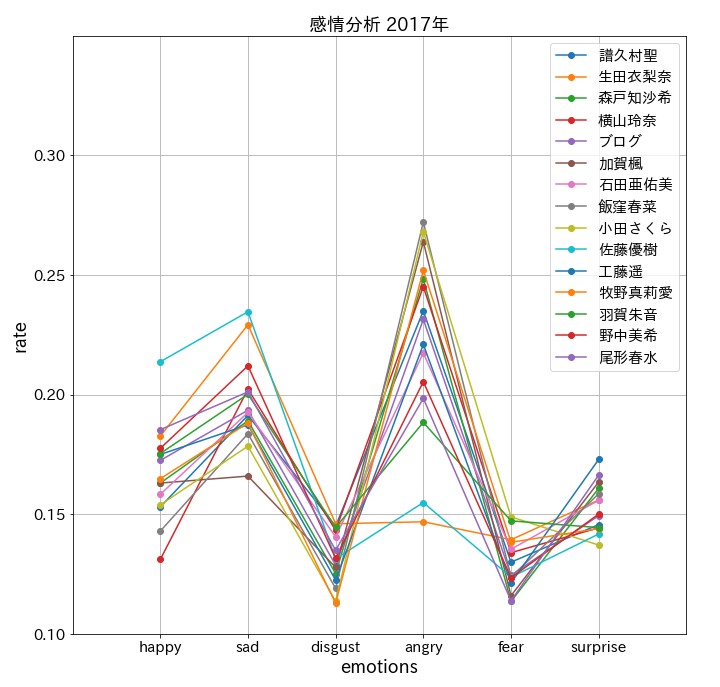
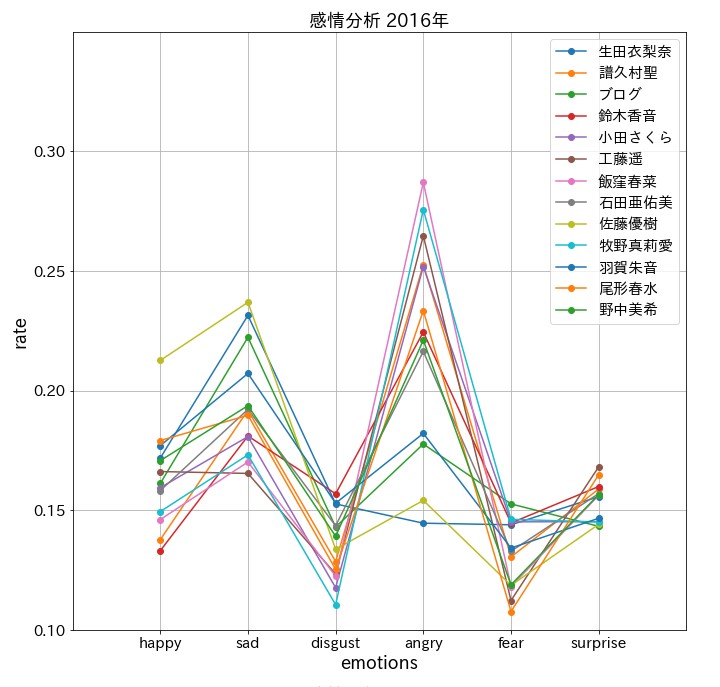
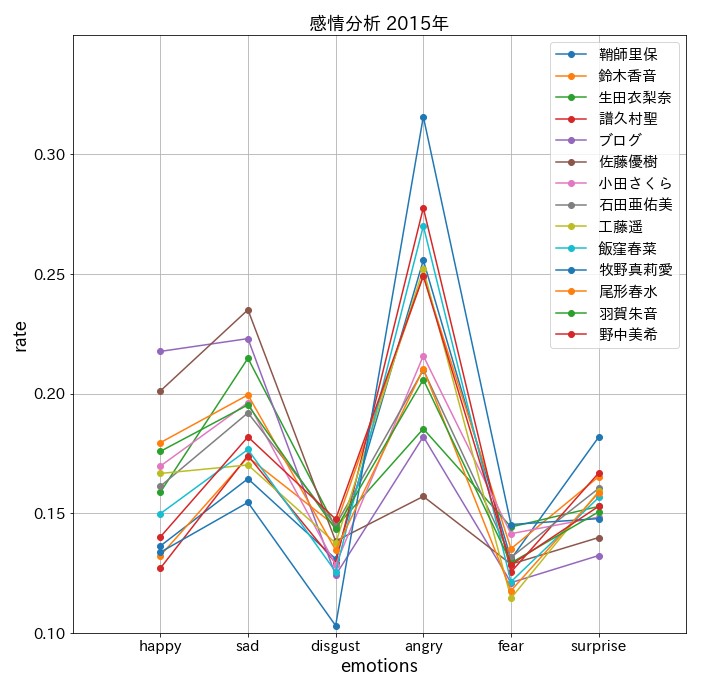
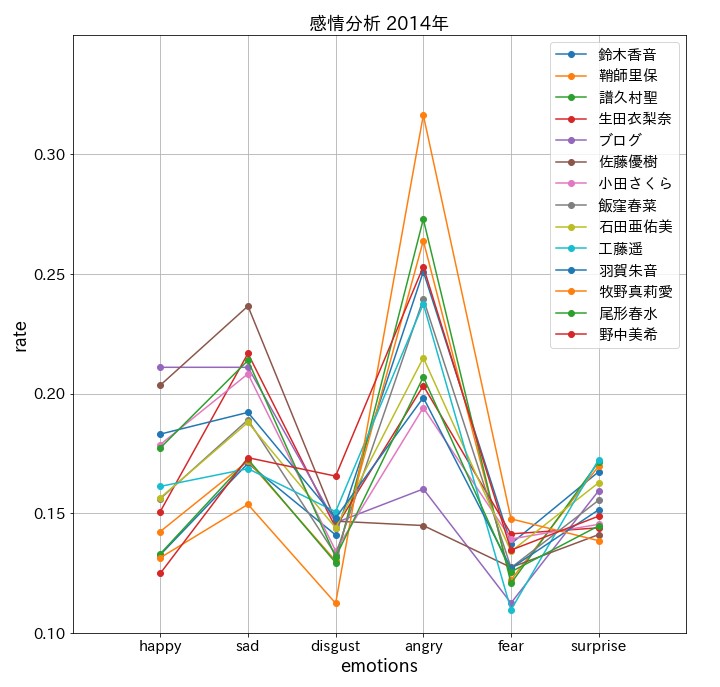
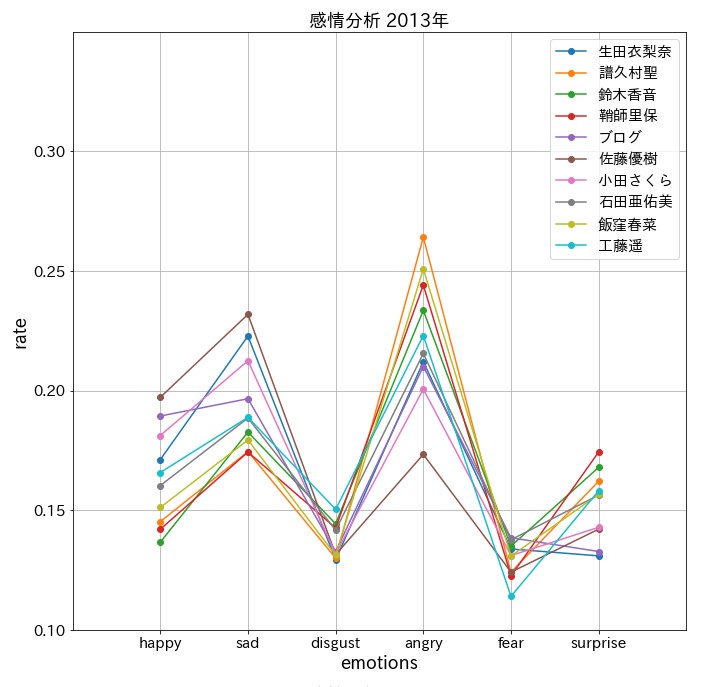
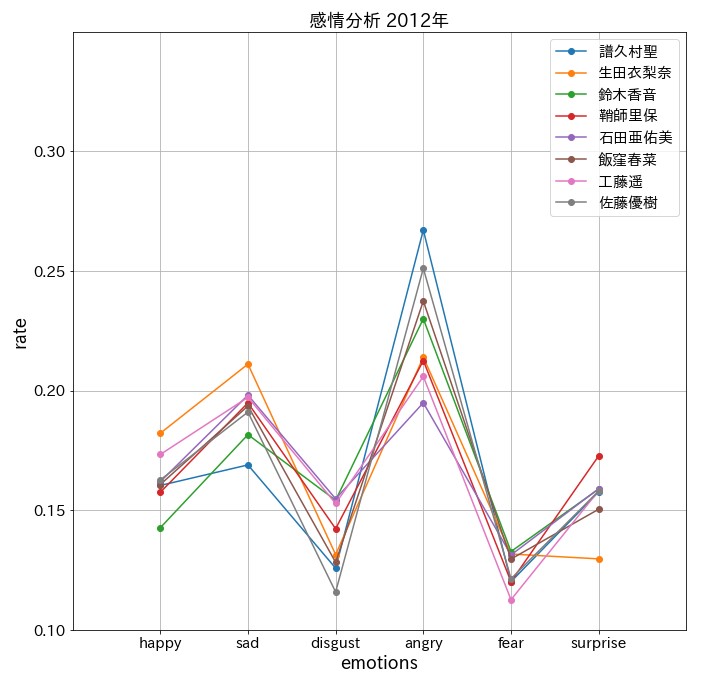
まとめ
驚愕の結果に。。。
ちなみに、2013年5月までは 田中 れいな(たなか れいな)さん
2014年11月までは 道重さゆみ(みちしげ さゆみ)さん の6期二人のブログはありましたが、
ここには入っていません。
念の為ですが、ご了承ください。
さて。。。まあ。。。こんな結果になりましたね。。。 やはりネタにしかなりませんでしたね。
そう言えば昔、 KOFの怒チームがマイフェイバリットでした。
ハイデルン教官。
ラルフとクラーク。
いや〜強かったですよね〜。
KOF96ぐらいまでは 怒(ド)チームは無敵でした。
怒(℃)チームにしてもいいかもね。
See You Next Page !
ちなみに、2013年5月までは 田中 れいな(たなか れいな)さん
2014年11月までは 道重さゆみ(みちしげ さゆみ)さん の6期二人のブログはありましたが、
ここには入っていません。
念の為ですが、ご了承ください。
さて。。。まあ。。。こんな結果になりましたね。。。 やはりネタにしかなりませんでしたね。
そう言えば昔、 KOFの怒チームがマイフェイバリットでした。
ハイデルン教官。
ラルフとクラーク。
いや〜強かったですよね〜。
KOF96ぐらいまでは 怒(ド)チームは無敵でした。
怒(℃)チームにしてもいいかもね。
See You Next Page !