Published Date : 2019年4月21日20:41
続・自然言語処理
前回の記事の簡単なおさらい
Scrapyを使って
モーニング娘。の
メンバー達のブログ記事を、
JSON形式で保存。
データを覗く
前回、ブログ記事を
morningblog.json
という名前で保存しました。
まずそれを開いちゃいます。
その為にプロジェクトの外側に、 処理用の新しいPythonファイルを作る。
まずそれを開いちゃいます。
その為にプロジェクトの外側に、 処理用の新しいPythonファイルを作る。

ファイル名はnlp_preprocessing.py
ですが、別に決まりは無いので、
各々好きな名前にしちゃいなYO。
JSONの取り扱い
さあ、中身を確かめてみよう!
。。。おっとその前に、
処理がしやすくなるように、
ファイルの場所を分かりやすくします。
。。。おっとその前に、
処理がしやすくなるように、
ファイルの場所を分かりやすくします。
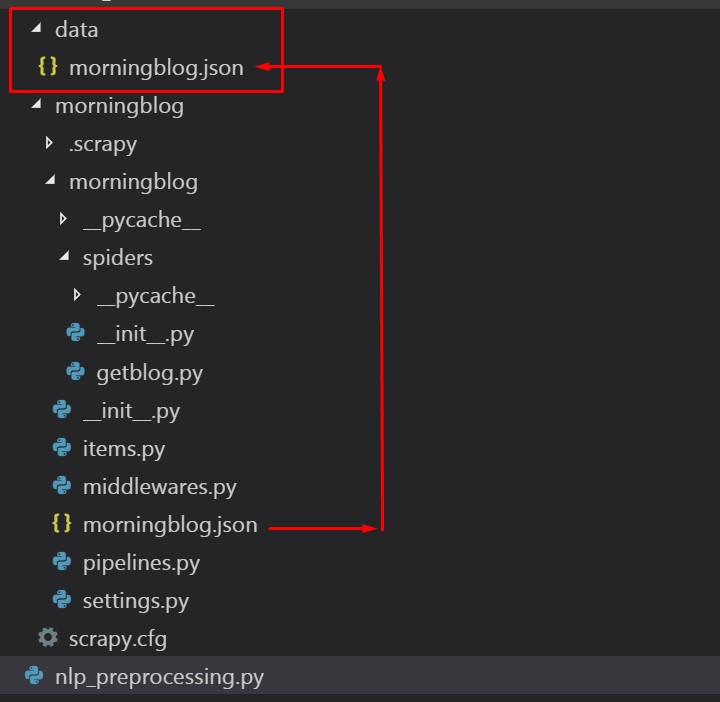
nlp_preprocessing.py
と同じフロアに、
dataというフォルダを作る。
その中に、前回保存した morningblog.jsonをコピペします。
さあ、中身を確かめてみよう!
nlp_preprocessing.pyを開き、 以下のコードをカキカキ。
dataというフォルダを作る。
その中に、前回保存した morningblog.jsonをコピペします。
さあ、中身を確かめてみよう!
nlp_preprocessing.pyを開き、 以下のコードをカキカキ。
nlp_preprocessing.py
# JSONファイルを取り扱うためにjsonモジュールをインポート。
import json
# 第一引数はファイルまでのパスにする。
# 第二引数には読み込みモードの'r'を指定。
# encodingをutf-8にしないと日本語をうまく読み込めない場合がある。
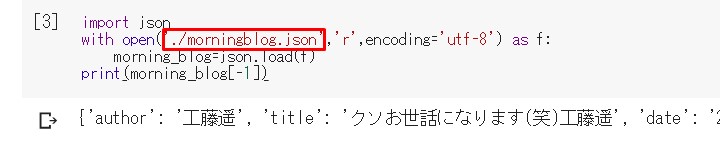
with open('./data/mornigblog.json','r',encoding='utf-8') as f:
# ファイル記述子をloadメソッドに入れるだけの簡単なお仕事です。
mornigblog=json.load(f)
# とりあえず中身を確認。
# これ全部表示すると恐ろしいことになる。
# なので、最後の行だけ表示する。
# 最後の行には一番古いブログ記事が格納されている。
print(mornigblog[-1])
ファイルを保存して、
以下を実行。
# コマンドプロンプトまたはターミナルから実行 python nlp_preprocessing.py

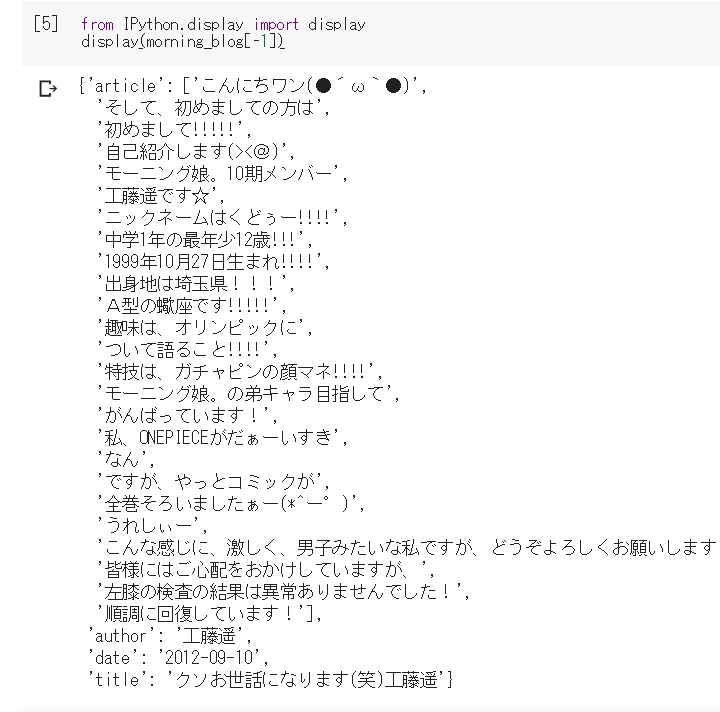
今では女優として活躍している
工藤遥さんのブログですね。
当時は12歳の中学一年生。。。
日付は2012年9月10日。
7年前。。。 色々な意味で凄いっす。
当時は12歳の中学一年生。。。
日付は2012年9月10日。
7年前。。。 色々な意味で凄いっす。
google colaboratory
さて、今まで黒い画面とかで
出力を見てきましたが、
データを見やすくしたり、 KerasやTensorflow
といった、機械学習用ライブラリ を使用できると便利なので、
これからは、google colaboratory で作業を進めていこうと思います。
google colaboratoryとは、 簡単に説明すると、
あまりにも素晴らしすぎて、
利用者はGoogle様本社に、
足を向けて眠れなくなるだろう。
感謝感謝!サンキューです!Google様!!
と一日100回は唱えましょう。
データを見やすくしたり、 KerasやTensorflow
といった、機械学習用ライブラリ を使用できると便利なので、
これからは、google colaboratory で作業を進めていこうと思います。
google colaboratoryとは、 簡単に説明すると、
| 1 | クラウドで実行される |
|---|---|
| 2 | Tesla系のK80 GPU付属 |
| 3 | 機械学習の環境が設定済み |
| 4 | OSの環境に振り回されない |
| 5 | Googleアカウントあれば使える |
| 6 | 驚くなかれ、無料で使える |
足を向けて眠れなくなるだろう。
感謝感謝!サンキューです!Google様!!
と一日100回は唱えましょう。
事始め
Googleアカウントがあれば
速攻で使用できます。
アカウントがなければ、 秒速で作りましょう。
下記サイトにアクセスし、 Googleアカウントでログイン。
https://colab.research.google.com/?hl=ja
ログイン後「ファイル」から、 「Python 3の新しいノートブック」 を選択する。
アカウントがなければ、 秒速で作りましょう。
下記サイトにアクセスし、 Googleアカウントでログイン。
https://colab.research.google.com/?hl=ja
ログイン後「ファイル」から、 「Python 3の新しいノートブック」 を選択する。
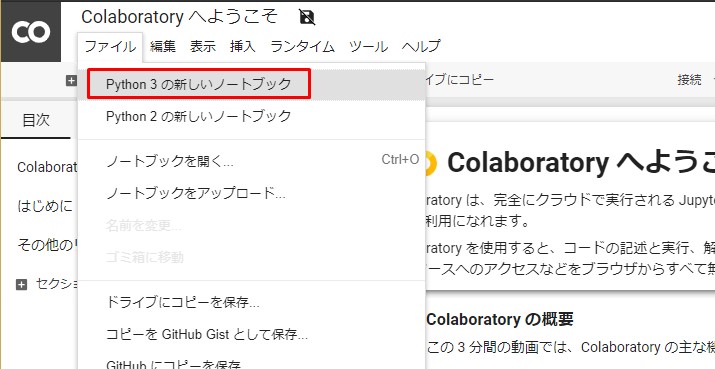
GPUを使えるようにする
「ランタイム」から、
「ランタイムのタイプを変更」
をクリック。
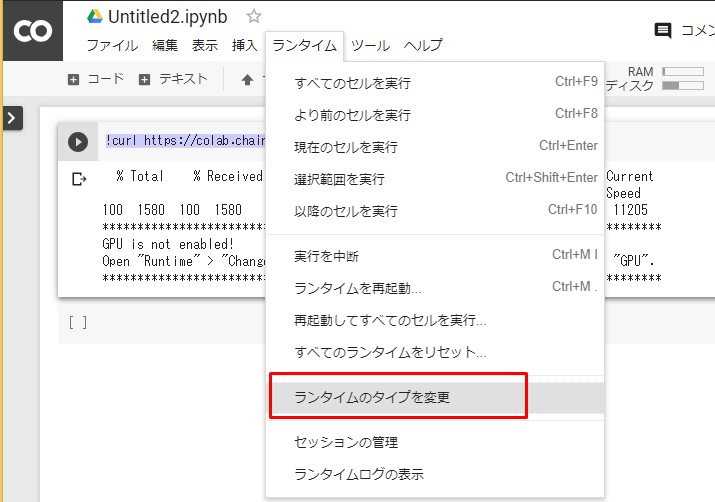
アクセレーターを
GPUに変更。
そして保存。
そして保存。
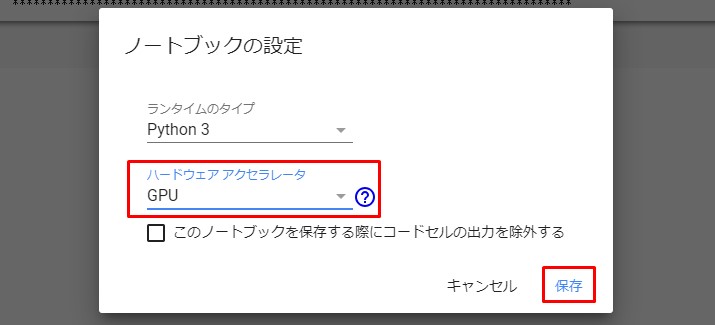
ファイルをアップロード
先程のブログ記事、
morningblog.jsonを
colaboratory で扱えるようにするため、 以下のコマンドを実行。
colaboratory で扱えるようにするため、 以下のコマンドを実行。
from google.colab import files uploaded = files.upload()
SHIFTを押しながら
ENTERで実行できます。
すると、ファイルを選択できるので、 morningblog.jsonを選び、
ファイルを開くをクリック。
すると、ファイルを選択できるので、 morningblog.jsonを選び、
ファイルを開くをクリック。
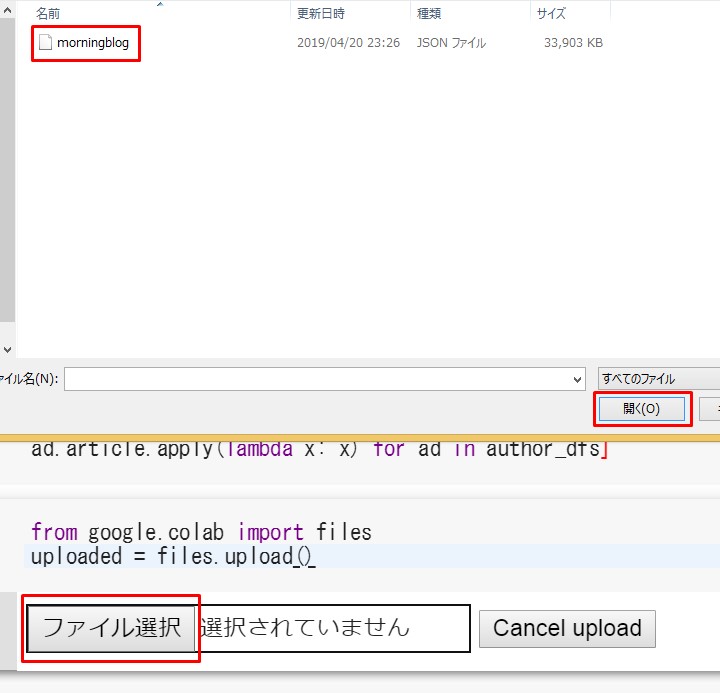
ファイルを確認
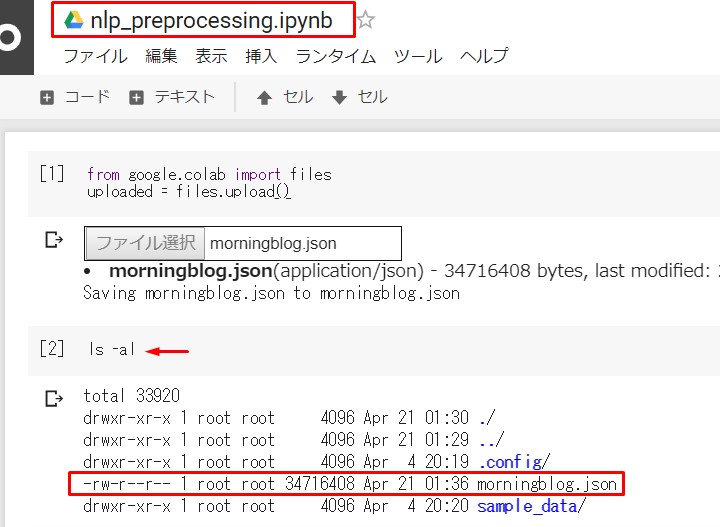
アップし終わったら、
ファイルがあるか確認。
ls -al
ついでにノートブックの名前も変えよう。
一番上の赤枠部分を
クリックして書き換えるだけ。
ちなみに拡張子の、
.ipynbは、
ipython notebookの略。
ローカル環境で jupyter notebook が使えれば、
ファイルをダウンロードして、 すぐに使える。
jupyter notebook をインストールするのは簡単。
ipython notebookの略。
ローカル環境で jupyter notebook が使えれば、
ファイルをダウンロードして、 すぐに使える。
jupyter notebook をインストールするのは簡単。
pip install notebook # インストールし終わったら、 # コマンドライン上で以下を打つだけ。 jupyter notebook # するとブラウザが立ち上がり、 # colaboratoryと一緒の画面が出てきます。 # ただKeras等はインストールと設定が非常に面倒くさいし、 # これから使う分かち書きのライブラリ(文章を単語ごとに細かく分ける)は # LinuxやMac等しか使えない辞書があったり、 # windowsで使えるように設定する必要があったり、 # ややこしいので、colaboratoryを使うのをお勧めします。
ファイルがあるのを確認できたら、
前に作っておいた
nlp_preprocessing.pyの 中身をセルにコピペします。
google colaboratoryでは、 コードやコメントを書く部分の事を セルと言います。
ファイルパスだけ変えます。
nlp_preprocessing.pyの 中身をセルにコピペします。
google colaboratoryでは、 コードやコメントを書く部分の事を セルと言います。
ファイルパスだけ変えます。
表示された中身は横に長く、
見辛くなっています。
見やすくするために、 以下のコードを実行させます。
見やすくするために、 以下のコードを実行させます。
from IPython.display import display display(mornig_blog[-1])
感情分析
それでは前処理をしていく前に、
何か面白みがある事をしていこうぜ!
つーことで、colaboratoryで 以下のコードを実行してね。
つーことで、colaboratoryで 以下のコードを実行してね。
!git clone https://github.com/sugiyamath/sentiment_ja
ちなみにこちらの、
感情評価モデルのパッケージは
ツイートから学習した感情分析モデル
を書いたShun Sugiyama さんが作ったものです。
@sugiyamathさんのブログリンク。 http://datanerd.hateblo.jp/
すごい人です! 感謝感謝!サンキューです!
ツイートから学習した感情分析モデル
を書いたShun Sugiyama さんが作ったものです。
@sugiyamathさんのブログリンク。 http://datanerd.hateblo.jp/
すごい人です! 感謝感謝!サンキューです!
とりあえず使ってみる
以下のコードを実行してね。
cd sentiment_ja

続いて以下のコマンドを打ちます。
!python setup.py install
するとズラーッと文字が表示され、
Pythonで使えるようになります。
とりあえず、使ってみよう。
分かち書きをしないでも使えるので、 以下のコードで試してみます。
とりあえず、使ってみよう。
分かち書きをしないでも使えるので、 以下のコードで試してみます。
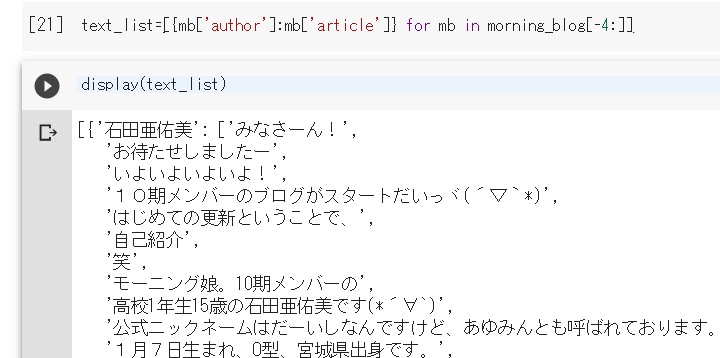
# メンバーのブログ記事の最後から数えて4番目から
# 最後まで、つまり一番古い4記事を取り出します。
# それを、誰の記事なのか分かりやすくするため、
# 記事を書いた人をキー、
# 記事をバリューとして辞書のリストにする。
text_list=[{mb['author']:mb['article']} for mb in morning_blog[-4:]]
# 一応確認。
dispay(text_list)
ちなみに、colaboratoryは、
時間が経つと自動的に セッションアウト等がされてしまい、
設定やインストール等が リセットされてしまうことがあります。
そんな時は以前動かしたセルに戻り、 SHIFT + ENTER で再実行してください。
その際に今いるフロアが 変わっているので、
'./morningblog.json'などは
'../morningblog.json' などに変えてください。
'./'は今いるフロアで、
'../'は一つ上のフロアを意味します。
時間が経つと自動的に セッションアウト等がされてしまい、
設定やインストール等が リセットされてしまうことがあります。
そんな時は以前動かしたセルに戻り、 SHIFT + ENTER で再実行してください。
その際に今いるフロアが 変わっているので、
'./morningblog.json'などは
'../morningblog.json' などに変えてください。
'./'は今いるフロアで、
'../'は一つ上のフロアを意味します。
さて、話を戻し、
text_listの中身は 以下のようになっています。
text_listの中身は 以下のようになっています。
| No. | Index | 書いた人 | ||||||
|---|---|---|---|---|---|---|---|---|
| 1 | -4 | 石田亜佑美 | ||||||
| 2 | -3 | 飯窪春菜 | ||||||
| 3 | -2 | 佐藤優樹 | ||||||
| 4 | -1 | 工藤遥 |
感情分析の結果をグラフ化
まずは4人分、4記事という
少ない量で試していきます。
それではarticle の中身を取り出して、
感情分析してみます。
それではarticle の中身を取り出して、
感情分析してみます。
# インストールしたsentimetjaからAnalyzerをインポート
from sentimentja import Analyzer
# Analyzerから感情分析するためのanalyzerオブジェクトを作成
analyzer = Analyzer()
# 4人分、4記事が入ったtext_listから
# 一つずつの記事を、一行ごとに感情分析していきます。
# グラフ化する時のタイトルに使うため、
# 二度手間ですが再び辞書型にしてキーを書いた人にする。
analyzed_dict=[{list(tl.keys())[0]:analyzer.analyze(t)} for tl in text_list for t in list(tl.values())]
# 表示してみる
display(analyzed_dict)
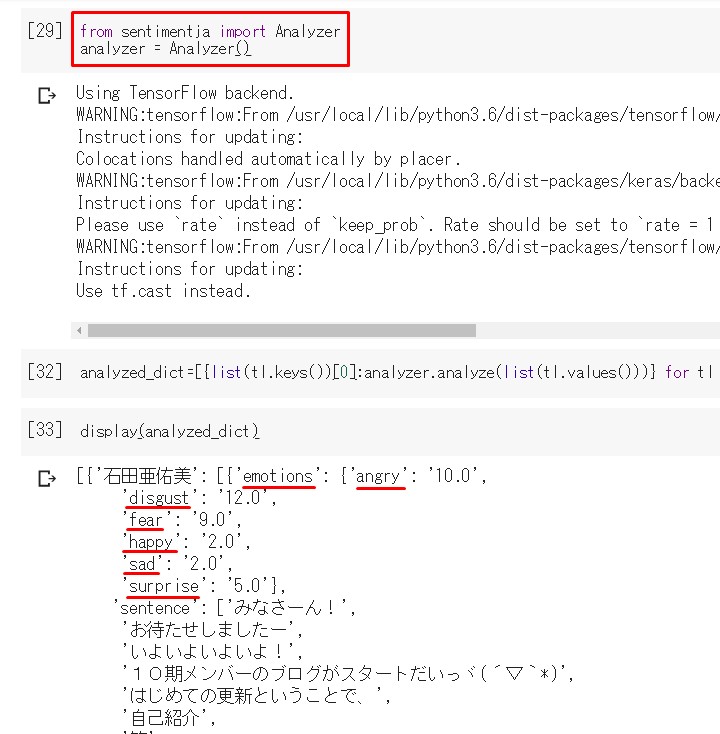
emotionsがキーとなり、
計6つの感情があります。
happyは幸せ なので前向きな感情。
disgustは嫌悪 なので後ろ向きな感情。
fearは恐れ なので後ろ向きな感情。
angryは怒り なので後ろ向きな感情。
sadは悲しみ なので後ろ向きな感情。
surpriseは驚き なので前向き、後ろ向き、 どっちともとれる感情。
もう一つのキーsentence は元となった文章。
happyは幸せ なので前向きな感情。
disgustは嫌悪 なので後ろ向きな感情。
fearは恐れ なので後ろ向きな感情。
angryは怒り なので後ろ向きな感情。
sadは悲しみ なので後ろ向きな感情。
surpriseは驚き なので前向き、後ろ向き、 どっちともとれる感情。
もう一つのキーsentence は元となった文章。
懸念材料
ただ、安直に”恐れ”や”悲しみ”だからといって、
駄目な感情と決めつけるのではなく、
その人の置かれた立場や状況 から読み取れる文脈と一致していれば、 よいわけで、
一概に数値化して判断するのも 難しいものです。
例えば、一番最初のブログで、 尚且、モーニング娘に入りたての時期。
この時の自己紹介で「Happy」 が出てくることもあれば、
「緊張」や「不安」といった言葉を 素直に出す人もいるはずです。
そこで十把一絡に「駄目」ではなく、 それは自然な感情だと思うことも重要です。
さらにこのパッケージの作者の ブログにも書いてある通り
精度があまり良く無いみたいです。
ただ使用するだけの側なので、 その辺はあまり触れたくないです。
まあとにかくこの結果を、 グラフで表示してみます。
その人の置かれた立場や状況 から読み取れる文脈と一致していれば、 よいわけで、
一概に数値化して判断するのも 難しいものです。
例えば、一番最初のブログで、 尚且、モーニング娘に入りたての時期。
この時の自己紹介で「Happy」 が出てくることもあれば、
「緊張」や「不安」といった言葉を 素直に出す人もいるはずです。
そこで十把一絡に「駄目」ではなく、 それは自然な感情だと思うことも重要です。
さらにこのパッケージの作者の ブログにも書いてある通り
精度があまり良く無いみたいです。
ただ使用するだけの側なので、 その辺はあまり触れたくないです。
まあとにかくこの結果を、 グラフで表示してみます。
実食!
日本語に対応させる
Pythonのグラフツール、
Matplotlibは
デフォルトでは 日本語に対応してません。
そのまま日本語を 表示させようとすると、
所謂「豆腐」 (表示が豆腐っぽいので)になります。
デフォルトでは 日本語に対応してません。
そのまま日本語を 表示させようとすると、
所謂「豆腐」 (表示が豆腐っぽいので)になります。
そのため、日本語を表示させるための、
便利なライブラリをインストールします!
感謝感激雨あられ。
以下を打ち込み インストール完了を待ちます。
感謝感激雨あられ。
以下を打ち込み インストール完了を待ちます。
!pip install japanize-matplotlib
食わず嫌い王
以下非常に猥雑なコードになりましたが、
動くのでとりあえずこれで試してください。
ああ。。。もっと良い方法があればな。
非常に無駄なコードになっているのに 十万ボリバル賭ける。
ああ。。。もっと良い方法があればな。
非常に無駄なコードになっているのに 十万ボリバル賭ける。
# データをいっぺんに処理するためPandasをインポート
import pandas as pd
# グラフツールのライブラリを長いので短い名前にしてインポート
import matplotlib.pyplot as plt
# 日本語を表示してくれる
import japanize_matplotlib
# 軽くグラフを表示してくれるマジックコマンド
% matplotlib inline
# 表題をメンバーの名前と日付にする。
plot_titles=[list(ad.keys())[0] for ad in analyzed_dict]
# 感情表記6種類をX軸のラベルにするための準備
columns=list(list(analyzed_dict[0].values())[0][0]['emotions'])
# 平均や比率を計算するのに、DataFrameにすると便利なので変換する
senti_dfs=[pd.DataFrame([a['emotions'] for av in list(ad.values()) for a in av],columns=columns) for ad in analyzed_dict]
# 合計値をリストにしてメンバー分格納。
emotions_sums=[[sd[s].apply(float).sum() for s in sd.columns] for sd in senti_dfs]
# 感情ごとの比率をリスト化していく。
rates=[esum/sum(esums) for esum in emotions_sums]
senti_rates=[dict(map(list,zip(senti_dfs[num].columns.tolist(),rate))) for num,rate in enumerate(rates)]
# 感情の種類と対応する比率をパーセンテージに直して表記させる。
labels=[[f'{list(sr.keys())[i]} \n {round(list(sr.values())[i]*100)}%' for i in range(len(sr.keys()))] for sr in senti_rates]
# メンバーの記事ごとにグラフに表示していく。
for num in range(len(senti_dfs)):
# X軸に「仮」の名前をつけてグラフの骨組みを作っておくための作業。
x=[i+1 for i in range(len(emotions_sums[num]))]
# Y軸はそれぞれの感情の合計値。
y=emotions_sums[num]
# 表題は書いた人の名前と日付。
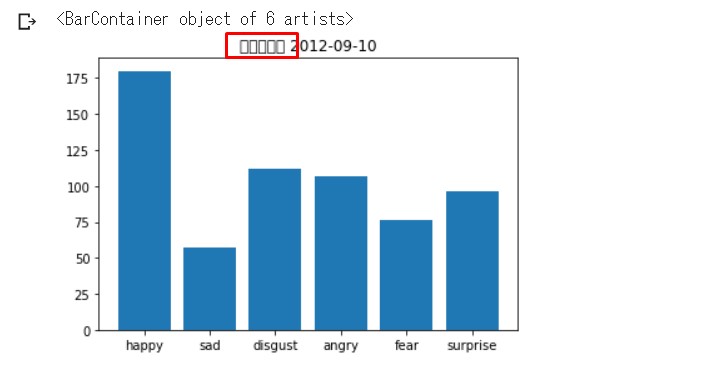
plt.title(f'{plot_titles[num]} {morning_blog[-4:][num]["date"].split(" ")[-1]}')
# X,Yを指定してグラフの型を作ったのち、ラベル、
# つまり、感情の名前と比率を貼り付ける。
plt.bar(x,y,tick_label=labels[num])
# 一つずつグラフ表示させる
plt.show()
判定
考察
精度云々よりも納得のいく結果になる。
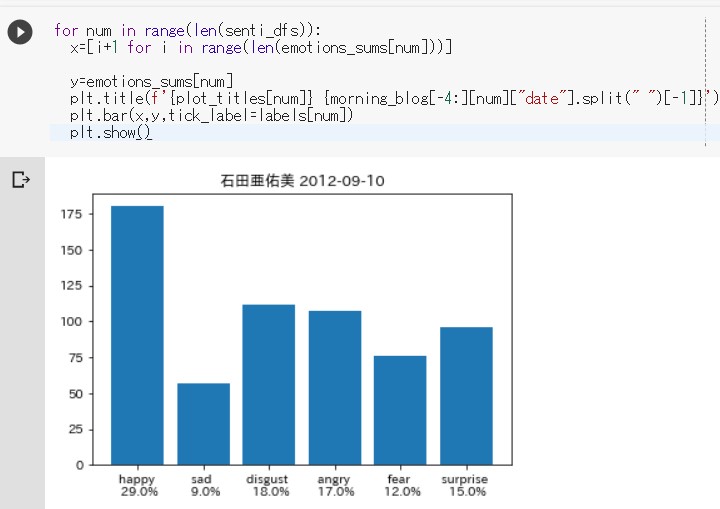
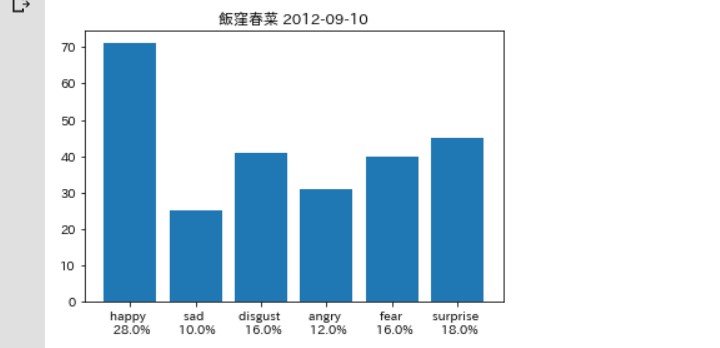
まず石田亜佑美さん(以下「あゆみん」)、 飯窪春菜さん(以下「はるなん」)の両名。
多少の違いはあれど、 同じようなグラフの形状になっている。
まず石田亜佑美さん(以下「あゆみん」)、 飯窪春菜さん(以下「はるなん」)の両名。
多少の違いはあれど、 同じようなグラフの形状になっている。
両名の共通点
この二人は加入前に、
他で芸能活動をしていたらしい。
そしてあゆみんは14歳の時モー娘。に加入。
はるなんは16歳の時である。
他の二人は加入時11歳と12歳。 世間的にはまだまだ若いとはいえ、 対外での経験値と この歳の差は精神面での 十分なアドバンテージになる。
つまり、良い意味でも 悪い意味でも成熟して 「おりこうさん」のブログに なりやすかったのではないだろうか?
Happyが多めで、他はおそらく ノイズのようなものだろう。
他の感情分析を取り扱っているサイトでも いわゆるHappyの感情が優先的に 選出されるみたいな内容をチラホラみかける。
要するに他とパターンが似ている テンプレート的なブログに なっているのではないだろうか。
他で芸能活動をしていたらしい。
そしてあゆみんは14歳の時モー娘。に加入。
はるなんは16歳の時である。
他の二人は加入時11歳と12歳。 世間的にはまだまだ若いとはいえ、 対外での経験値と この歳の差は精神面での 十分なアドバンテージになる。
つまり、良い意味でも 悪い意味でも成熟して 「おりこうさん」のブログに なりやすかったのではないだろうか?
Happyが多めで、他はおそらく ノイズのようなものだろう。
他の感情分析を取り扱っているサイトでも いわゆるHappyの感情が優先的に 選出されるみたいな内容をチラホラみかける。
要するに他とパターンが似ている テンプレート的なブログに なっているのではないだろうか。
天才と狂犬
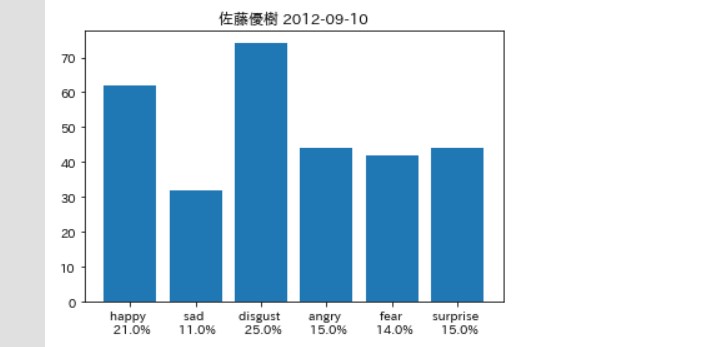
そしてお次は佐藤優樹さん
(以下「まーちゃん」)
と工藤遥さん(以下「くどぅー」)
この二人は非常にユニークである。
芸能活動はしてなかった北海道出身のまーちゃん。
非常に特殊で、周りと違った性格をしていて、 乗馬とドラムやピアノなどを習っていたなど多才。
絶対音感や独特な言語センスを持っている天才。
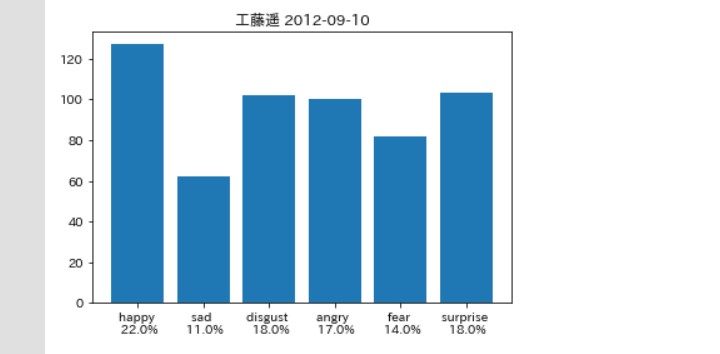
一方、 史上最年少でモー娘。に加入したが、 実は一年近くハロプロエッグで下積みしていた 早熟の狂犬チワワくどぅー。
当時くどぅーはかなりいきっていたらしく、 (自信の表れか) 自ら黒歴史と語っている。
他と比べて、disgust angry happy surprise など数値が近く高低差が少ない。
つまり当時は全ての感情を バランス良く出していたのではないだろうか。
それが良くも悪くも堂々とした 態度で「いきっていた」と 捉えられていたのではないだろうか。
そして「天才」まーちゃんだが、 一人だけ他と違い HappyとDisgustが反転している。
まーちゃんだけ文章量が少なかったので それが影響しているとはいえ、 興味深い結果に。
ちょうどくどぅーと反対のようなグラフになっている。 つまりすべての感情をだそうとしているが、
基本的な2つの相反する感情が行ったり来たりしている 非常に不安定な状態といえなくもない。
この二人は非常にユニークである。
芸能活動はしてなかった北海道出身のまーちゃん。
非常に特殊で、周りと違った性格をしていて、 乗馬とドラムやピアノなどを習っていたなど多才。
絶対音感や独特な言語センスを持っている天才。
一方、 史上最年少でモー娘。に加入したが、 実は一年近くハロプロエッグで下積みしていた 早熟の狂犬チワワくどぅー。
当時くどぅーはかなりいきっていたらしく、 (自信の表れか) 自ら黒歴史と語っている。
他と比べて、disgust angry happy surprise など数値が近く高低差が少ない。
つまり当時は全ての感情を バランス良く出していたのではないだろうか。
それが良くも悪くも堂々とした 態度で「いきっていた」と 捉えられていたのではないだろうか。
そして「天才」まーちゃんだが、 一人だけ他と違い HappyとDisgustが反転している。
まーちゃんだけ文章量が少なかったので それが影響しているとはいえ、 興味深い結果に。
ちょうどくどぅーと反対のようなグラフになっている。 つまりすべての感情をだそうとしているが、
基本的な2つの相反する感情が行ったり来たりしている 非常に不安定な状態といえなくもない。
再検証の余地おおあり
四人の性格を良く知ってるであろう
百戦錬磨のモー娘。オタク達は
他の細かい数値を見て
納得するだろうか。
(Angryが多めだから、 攻撃的な性格だろう等)
というより、そもそも 検証数が圧倒的に少なすぎる。
これを期間ごとに、 もっと大量に検証すれば違った結果
予想通りの結果 色々な結果が見られるに違いない。
(Angryが多めだから、 攻撃的な性格だろう等)
というより、そもそも 検証数が圧倒的に少なすぎる。
これを期間ごとに、 もっと大量に検証すれば違った結果
予想通りの結果 色々な結果が見られるに違いない。
おまけ
おまけと言えど、
本題みたいなもんで。
ブログ記事で取ってきた 全メンバーの最初の記事の感情分析。
Here We Go!!
ブログ記事で取ってきた 全メンバーの最初の記事の感情分析。
Here We Go!!
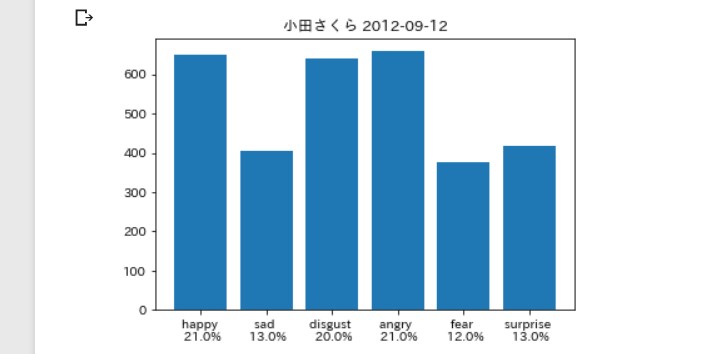
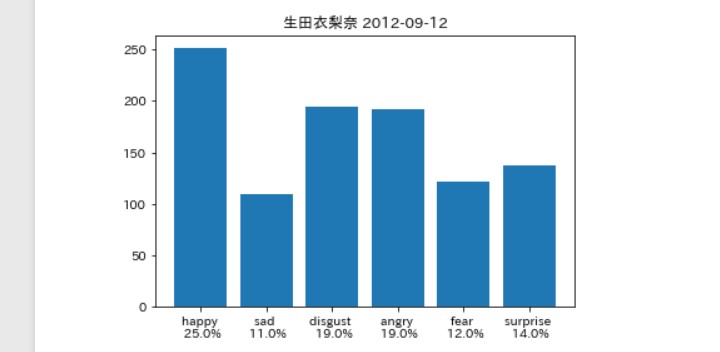
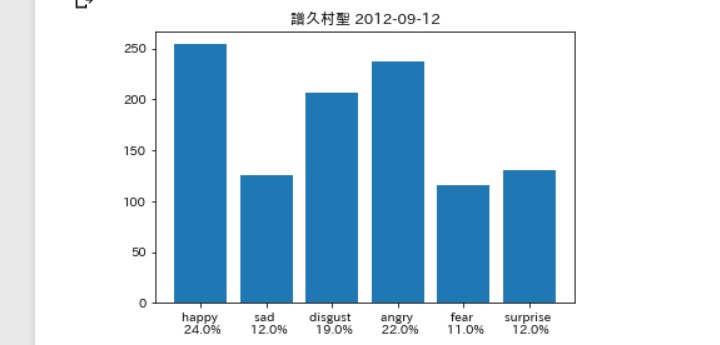
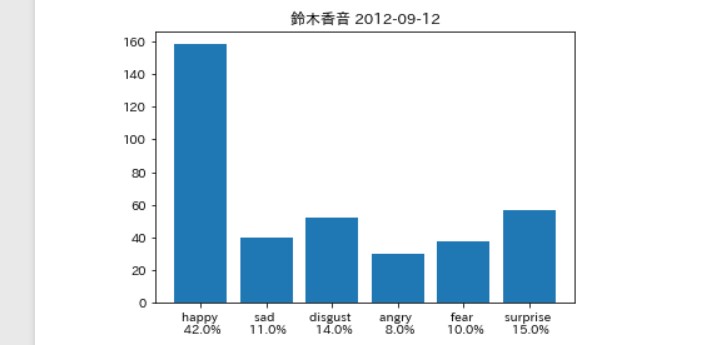
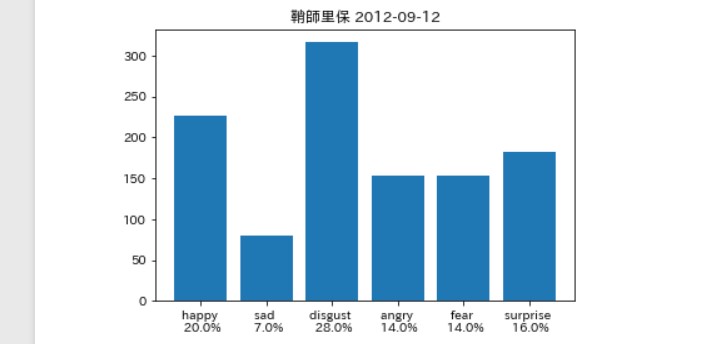
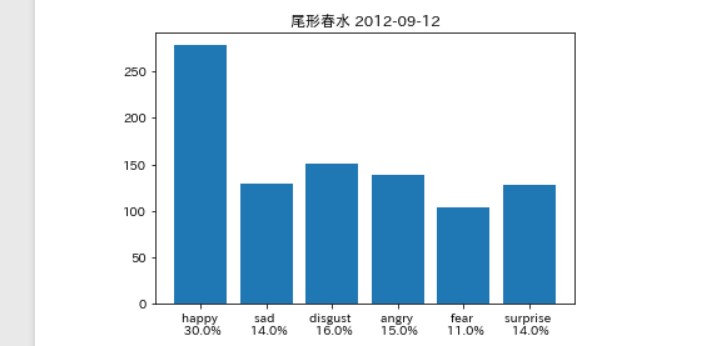
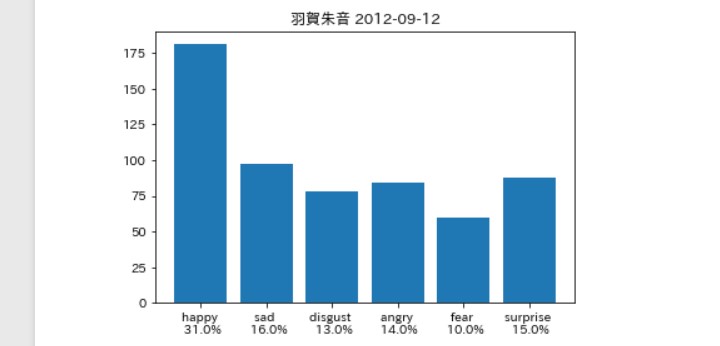
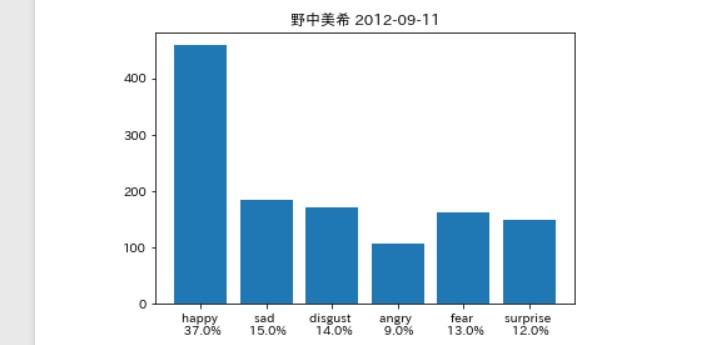
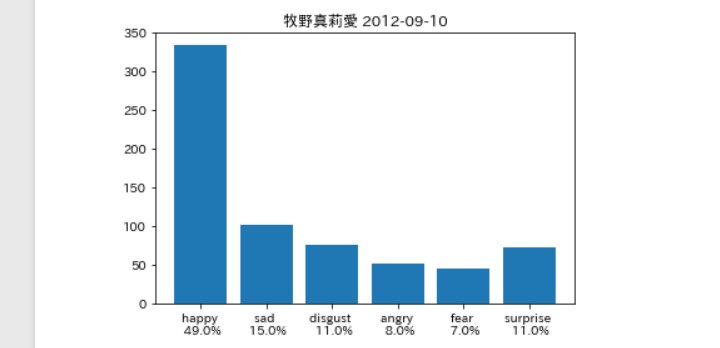
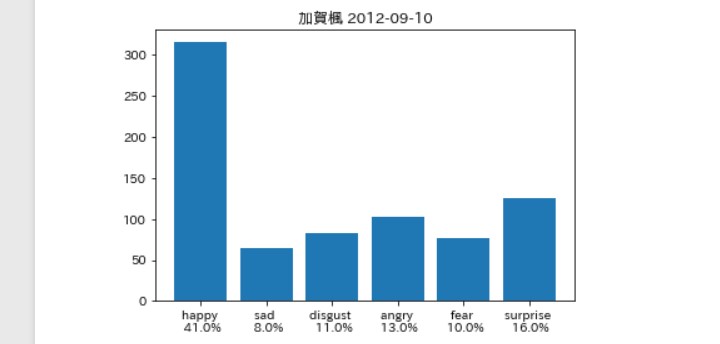
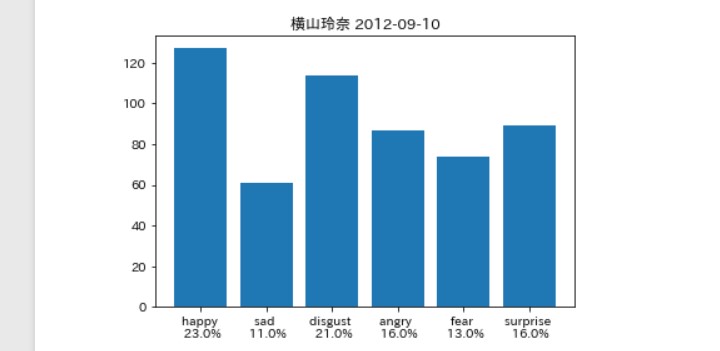
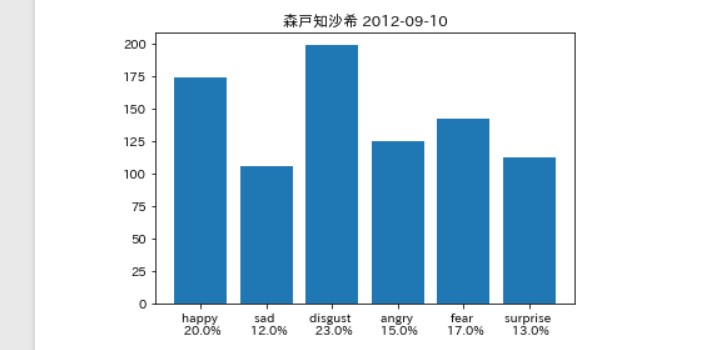
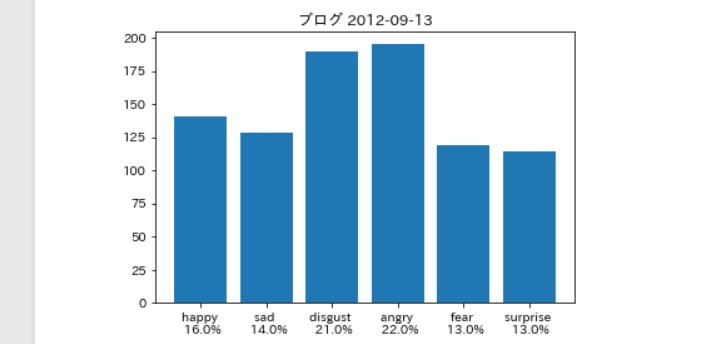
そんなに違いはないは。。。ず。。。
牧野真莉愛さん(以下(まりあ))
すげぇ。。。
なんていうか。。。 キャラ通り。。。
負けじと劣らず加賀楓さん(以下(かえでぃ))
前者に比べてsurpriseが 多めっていうのも、
ドラマを知ってる人達からすると 胸熱な分析結果ですね。
そして笑ったのは 最後の著者「ブログ」。
この著者「ブログ」とは、
これはメンバーに関する告知を 「事務所」が発信しているものです。
そして、最初の「ブログ」の内容が、 「佐藤優樹に関するお知らせ」
要約すると、 「まーちゃんはインフルになったんで、 コンサート出られません。さーせん。」
事務所の「怒り」が見事に分析 できているのではないだろうか(笑)
牧野真莉愛さん(以下(まりあ))
すげぇ。。。
なんていうか。。。 キャラ通り。。。
負けじと劣らず加賀楓さん(以下(かえでぃ))
前者に比べてsurpriseが 多めっていうのも、
ドラマを知ってる人達からすると 胸熱な分析結果ですね。
そして笑ったのは 最後の著者「ブログ」。
この著者「ブログ」とは、
これはメンバーに関する告知を 「事務所」が発信しているものです。
そして、最初の「ブログ」の内容が、 「佐藤優樹に関するお知らせ」
要約すると、 「まーちゃんはインフルになったんで、 コンサート出られません。さーせん。」
事務所の「怒り」が見事に分析 できているのではないだろうか(笑)
さて次もまた集めた
データで色々試してみます。
続きやったり、他の事したり。
See You Next Page !
続きやったり、他の事したり。
See You Next Page !