Published Date : 2019年4月14日20:44
Scrapy、自然言語処理、モーニング娘。
今更ながら自然言語処理勉強し始めたはいいが 。。。。。。
夏目漱石の小説の解析もいいけど、モチベーションが あがらないため、なんか楽しめる手段はないかなと。
ありました。
モーニング娘。のブログ。
ハロプロ好きなので、使わせて頂きます。
やりたいこと
「ブログ記事の感情分析、文章自動生成、分類、分析」
なにはともあれデータが欲しいので、 データ収集から始めます。
Scrapy 起動
やってみて思ったことは Scrapyの作り方はDjangoに似てる。
とにかく、 まずScrapyを使ってデータを集めよう。
みんな大好きpipがあれば無問題(モウマンタイ)。
pip install Scrapy
もしくは「主」Anacondaの高等魔法。conda。
conda install -c conda-forge scrapy
まずは適当な名前のフォルダを作ろうぜ!
「磯野!スクレイピングしようぜ!」
mkdir Scrapy_Crawl
さあ、フォルダの中に入ろう!
cd Scrapy_Crawl

入ったら魔法を唱えようぜ!
scrapy startproject morningblog

scrapyのコマンドですよ。と黒い窓に知らせ。
startprojectはプロジェクトを作る。
morningblogはプロジェクト名。
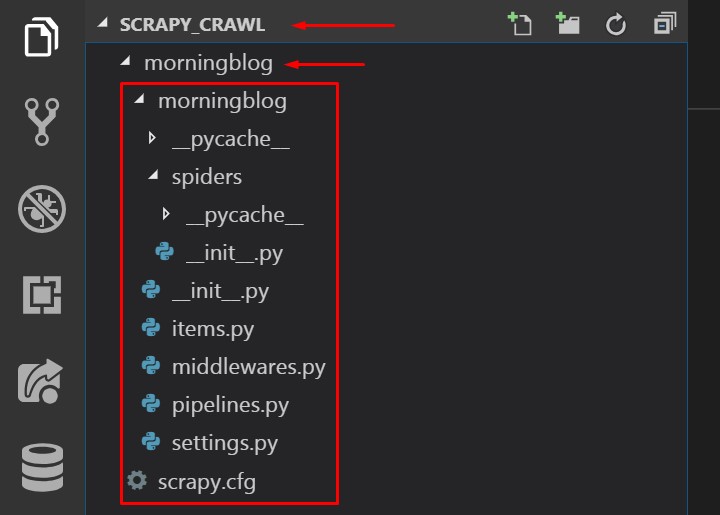
いっぱいファイルが作られてるけど、
よく使うのは今のところ items.pyとsettings.py。
Djangoでいうと、
items.py -> models.py
settings.py -> settings.py
某ブログサイトから記事を毟り取る。
API、APIが欲しいよう。。。
(探してないだけ。普通にあるかも。)
でも、大丈夫。 Scrapyがあればね。
作戦と全体図
決戦の前に体制を整えないとね。
まずは何をどれだけ取ってくるか。
データ量を考える。
ちなみにモーニング娘。は今14期までいるよ。
通常リンクは現役メンバー
以下名前順不同
| 1期(初代) | 中澤裕子 | 安倍なつみ | 飯田圭織 | 石黒彩 | 福田明日香 |
|---|---|---|---|---|---|
| 2期 | 矢口真里 | 保田圭 | 市井紗耶香 | ||
| 3期 | 後藤真希 | ||||
| 4期 | 吉澤ひとみ | 石川梨華 | 辻希美 | 加護亜依 | |
| 5期 | 高橋愛 | 小川麻琴 | 新垣里沙 | 紺野あさ美 | |
| 6期 | 藤本美貴 | 道重さゆみ | 田中れいな | 亀井絵里 | |
| 7期 | 久住小春 | ||||
| 8期 | ジュンジュン | リンリン | 光井愛佳 | ||
| 9期 | 譜久村聖 | 生田衣梨奈 | 鞘師里保 | 鈴木香音 | |
| 10期 | 飯窪春菜 | 佐藤優樹 | 石田亜佑美 | 工藤遥 | |
| 11期 | 小田さくら | ||||
| 12期 | 牧野真莉愛 | 野中美希 | 羽賀朱音 | 尾形春水 | |
| 13期 | 横山玲奈 | 加賀楓 | |||
| 14期 | 森戸知沙希 |
大体ブログやってるよ。
量を推定。
ざっとみたところブログの文字数は
100文字〜1000文字くらい??
平均2日に一回更新。ぐらい??
文字数少なめに見積もって、
単純計算一人一年分あたり
150ページ✕500文字=4.5万文字。
現役メンバーの人数で計算。
4.5万文字✕14人=63万文字
3年分取得したとしたら。
189万文字。
時間かかりそう。
ちなみにスクレイピング作法として、
サーバーに負担をかけないように、
一回のリクエストごとに
2〜3秒のディレイ(待機時間)
を設けなければならない。
某ブログは
期ごとに分けてると思いきや、
9期、(10期、11期)、12期、(13期、14期)
とブログのページは若干統合されてる。
さらに過去のメンバーの記事も生きています。
どうせなら期ごとの過去メンバーの記事も集めてみる。
ということで、 計16人分(1年〜6年)分 集めていこうと思います。
画像も一緒にとってくると、 相当時間がかかるので、
集めるのは記事本文のみで。
Spider Man !!
スパイダー作成。
覚えていますか、この文言。
つまり、作ったプロジェクトのフォルダに入る。
そしてコードを実行する。
やってみましょう。 スパイダー名と、ドメインだけ変えます。
cd morningblog scrapy genspider getblog 某ブログさいと.jp
成功するとこの文が出てくる。
Created spider 'getblog' using template 'basic' in module: morningblog.spiders.getblog
spidersというフォルダを開くと、 作った名前のPythonファイルができている。
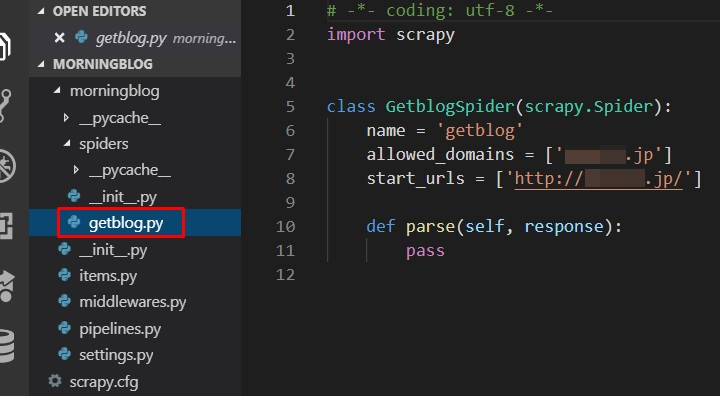
nameは、 スパイダーの名前。動かす時に この名前と一致していないと、怒られる。
allowed_domainsは、 このドメイン名からしか 情報をとってこないよという意味になる。
start_urlsは、 情報をとってくる最初のURL。
複数指定できる。
ブログのURLを書く
start_urlsにメンバーのブログページを リストとして書いていく。
とりあえずparse メソッドの中身は、 受け取ったresponse のURLを表示させるだけにする。
# -*- coding: utf-8 -*-
import scrapy
class GetblogSpider(scrapy.Spider):
name = 'getblog'
allowed_domains = ['某ブログサイト.jp']
start_urls = [
'http://某ブログサイト.jp/morningmusume-9ki/',
'http://某ブログサイト.jp/morningmusume-10ki/',
'http://某ブログサイト.jp/mm-12ki/',
'http://某ブログサイト.jp/morningm-13ki/'
]
def parse(self, response):
print(response.url)
ひとまず、動作確認。
保存して、黒い窓に以下を打つ。
scrapy list 成功すると、実行ファイルの名前が返される。 -> getblog
続いて以下のコマンドを打ちます。
scrapy crawl getblog
するとズラーッと文字が表示された中に、 ちらっとURLが確認できる。
[scrapy.core.engine] DEBUG: Crawled (200) <GET https://某ブログサイト.jp/morningmusume-9ki/> (referer: https://某ブログサイト.jp/morningmusume-9ki/) [scrapy.core.scraper] DEBUG: Scraped from <200 https://某ブログサイト.jp/morningmusume-9ki/> https://某ブログサイト.jp/morningmusume-9ki/ <-- ここがprint()部分。
動作を確認したので、 ブログ記事をとってきます。
記事取得。
データの受け渡し方法。
記事を取得するコードを書く前に、 JSONなどで保存できるようにする。
まずはitems.pyを開きます。
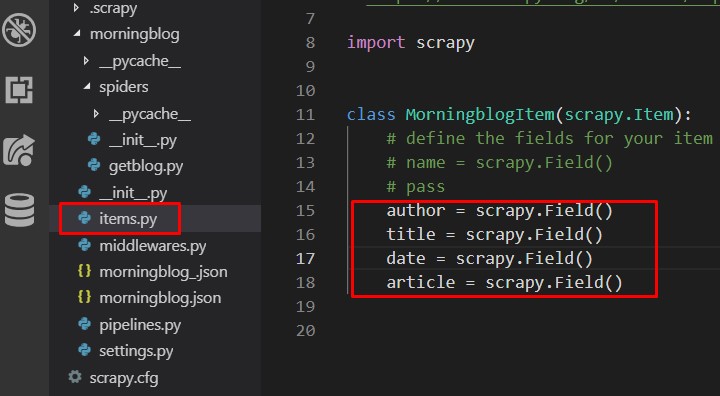
開くと最初からクラスが用意されています。
passの部分をコメントアウトして、 赤枠部分を書いていきます。
author = scrapy.Field() title = scrapy.Field() date = scrapy.Field() article = scrapy.Field()
簡単に、説明すると authorやtitleは
辞書でいうキーになります。
Field()はSpider からとってきたデータが入ります。
実際の使い方。
# クラスファイルからインスタンスオブジェクトを作成。
item = MorningblogItem()
# 辞書のキーを指定するみたいにデータを入れる。
item['author'] = response.xpath('//a/text()').get()
# yield文は今までの処理を一旦中断して、
# 値を関数の外へ返す。
# 値を返した後、また次の行から処理を繰り返す。
# 簡単にいうとメモリの節約。
yield item
itemの中身を疑似的に表示すると、 以下のように、ほぼ辞書になる。
print(item)
# 疑似的にitemを表現してみる。
-> {'author':'記事を書いた人。'}
ということで、一旦
このクラスファイルを
保存して閉じる。
itemsのクラスを使えるようにする。
# morningblogの中にある、 # items.pyから、 # MorningblogItemクラスファイルを呼び込む。 from morningblog.items import MorningblogItem
def parseは spiderが動いたら実行される関数。
def parse(self, response):
# クラスからオブジェクトを作成
item=MorningblogItem()
# 作者の名前が書いてあるHTML要素までのXPATHから、テキスト情報を抜き出す。
item["author"]=response.xpath('//dl[@class="skin-entryThemes"]/dd/a/text()').get()
# タイトルが書いてあるHTML要素までのXPATHから、テキスト情報を抜き出す。
item["title"]=response.xpath('//article/@data-unique-entry-title').get()
# 記事作成日が書いてあるHTML要素までのXPATHから、テキスト情報を抜き出す。
item["date"]=response.xpath('//time[@class="skin-textQuiet"]/@datetime').get()
# 記事要の本文が書いてあるHTML要素までのXPATHから、テキスト情報を抜き出す。
text_list=response.xpath('//div[@class="skin-entryBody"]//text()')
# 不要な改行や文字を取り除いて、
# 'article'のキーに、記事のリストを格納する。
item['article']=[text.get().strip() for text in text_list if text.get()!='\n' and text.get()!='\xa0']
# 一つの記事情報が入っているitemをyieldで返す。
yield item
次のページからも記事を取得。
続いて、ネクストボタンから 次のページに行くための処理を行う。
# 次へボタンがあるHTML要素までのXPATHから、aタグ要素を取得。
next_page_top=response.xpath('//a[@class="skin-pagingNext skin-btnPaging ga-pagingTopNextTop"]')
# 次へボタンが存在している場合。
# つまり、次のページがあるなら、以下の処理をする。
if next_page_top:
# response.urljoinでベースとなるURLと、
# aタグのhrefから取ってきたURLをくっつける。
next_page_url=response.urljoin(next_page_top.xpath('@href').get())
# scrapy.Requestを使って、
# 次のページのURLへ飛ぶ。
# callbackにparseメソッド自身を指定して、
# グルグルとループさせるように記事を取り出していく。
# dont_filterは、scrapyが
# 同じURLに対してクロールを行わないようにする為のフィルター。
# Trueにすると、フィルターを行わないようにできる。
yield scrapy.Request(next_page_url,callback=self.parse,dont_filter=True)
さて、これを保存してから 最後の仕上げ。
日本語を保存できるようにする。
items.pyと同じフロアにある、 settings.pyという設定ファイルを開きます。
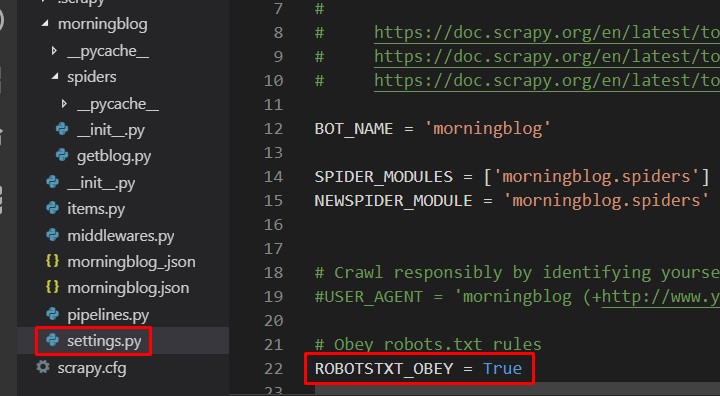
以下のコメントアウトを外します。 ROBOTSTXT_OBEY = TURE robots.txtに従う。 robots.txtとは取られたくない情報を クロールされないように制限するファイルです。 これがあるにも関わらず、 無理やりクロールしようとするのを避けるためにTrueにします。
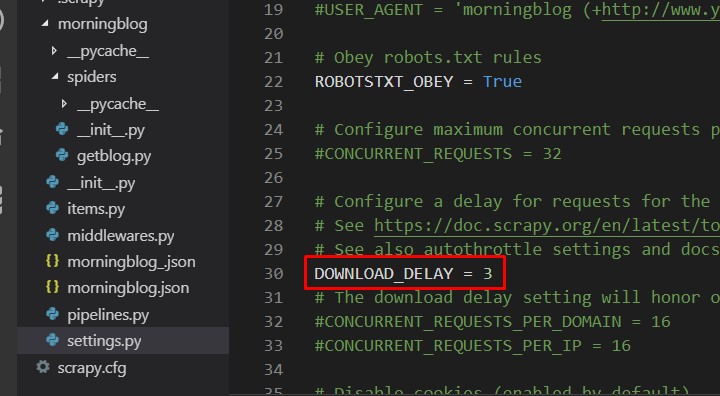
以下のコメントアウトを外します。 DOWNLOAD_DELAY = 3 ページの情報をダウンロードしたあとに、 3秒間待つようにする設定。 サーバーへの負担を軽くするために、 2〜3秒は待機時間を設けるのがマナーとされている。
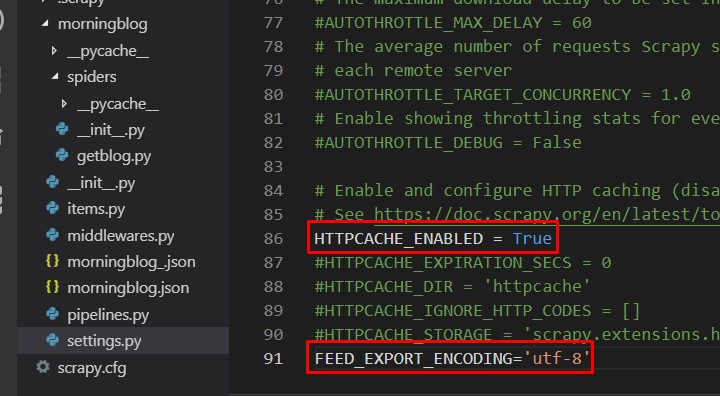
以下のコメントアウトを外します。 HTTPCACHE_ENABLED = True キャッシュ機能を有効にする。 キャッシュは前回行った作業を記録するような機能。 次回から同じことする時、作業が速くなる。 こちらはデフォルトで書いていないので、 新たに加える。 FEED_EXPORT_ENCODING='utf-8' これが無いと、取ってきたデータの 日本語が上手く反映されない。
さあ、settings.pyを保存して、 クロールしていきましょう。
レッツ クロール!
フロアはそのまま、 以下のコマンドで確認する。
scrapy list 正常にことが進めば以下が表示される。 -> getblog
いよいよクロール開始。 以下のコマンドを打つ。
scrapy crawl getblog -o morningblog.json crawl はクロールを開始させるという意味。 次に実行ファイル名を指定する。-> getblog -o は 結果をoutputさせるというオプション。 morningblog.jsonという名前のJSONファイルでoutputする。
実行するとこんな感じに記事が取れていく。
あとはひたすら心を無にして、 流れていく文字を見つめていくだけだ。
2019-04-14 13:35:20 [scrapy.core.engine] DEBUG: Crawled (200)
<GET https://某ブログサイト.jp/mm-12ki/page-3051.html>
(referer: https://某ブログサイト.jp/mm-12ki/page-3050.html)
2019-04-14 13:35:20 [scrapy.core.scraper] DEBUG: Scraped from
<200 https://某ブログサイト.jp/mm-12ki/page-3051.html>
{'article': ['こんばんおやきー',
'今日はBuono!さんの日本武道館ライブを見に行かせていただきました',
'Buono!さんのパフォーマンスは、',
'去年の冬ハローでしか見たことがなかったので……',
'たくさんの曲を生で見れたことがすごく嬉しかったです',
'ロックでかっこいい曲',
'バラード系なゆっくりな曲',
'元気でかわいい曲',
'色んなBuono!さんを見ることが出来て',
'ほんとにテンションあがりっぱなしでした!',
'いつも、武道館公演を客席から見ていると',
'会場全体の一体感って、本当にすごいなぁって思うんです!!',
'ステージから見ててもそう感じるけど、',
'客席から見ていても、熱気が伝わってくるコンサート…',
'ほんっとにステキだなぁと思いました',
'そしてすごく楽しかったです',
'3時間がすごく早く感じました…',
'またBuono!さんのライブ、見たいですっ',
....................................................
....................................................
省略。
'author': '羽賀朱音',
'date': '2016-08-25',
'title': 'Buono!さんだみょーん。羽賀朱音'}
さて、ここで驚愕の事実。
現役メンバー、時期が被る過去メンバー
すべてのブログ記事を収集し終わるのに、
なんと。。。15時間!!!
かかってしまいました。
そりゃそうだ。
1ページダウンロードしてから 待機時間が3秒ある。
そんで今回記事を取ってくるブログのページが 全部で18000ページ以上ありやした。
単純計算 18000✕3秒=54000秒
54000秒÷60秒=900分
900分÷60分=15時間…
まあしゃあない。 眠る前とかにやってください。
それか9期だけとか、 (10期、11期)だけとかに
分けたほうがいいと思う。
ここを一つだけにするとかで対応可能。 start_urls = [ 'http://某ブログサイト.jp/morningmusume-9ki/', 'http://某ブログサイト.jp/morningmusume-10ki/', 'http://某ブログサイト.jp/mm-12ki/', 'http://某ブログサイト.jp/morningm-13ki/' ] 例えばこう。 start_urls = [ 'http://某ブログサイト.jp/morningmusume-9ki/' ]
全コード
getblog.py
# -*- coding: utf-8 -*-
import scrapy
from morningblog.items import MorningblogItem
class GetblogSpider(scrapy.Spider):
name = 'getblog'
allowed_domains = ['某ブログサイト.jp']
start_urls = [
'http://某ブログサイト.jp/morningmusume-9ki/',
'http://某ブログサイト.jp/morningmusume-10ki/',
'http://某ブログサイト.jp/mm-12ki/',
'http://某ブログサイト.jp/morningm-13ki/'
]
def parse(self, response):
item=MorningblogItem()
item["author"]=response.xpath('//dl[@class="skin-entryThemes"]/dd/a/text()').get()
item["title"]=response.xpath('//article/@data-unique-entry-title').get()
item["date"]=response.xpath('//time[@class="skin-textQuiet"]/@datetime').get()
text_list=response.xpath('//div[@class="skin-entryBody"]//text()')
item['article']=[text.get().strip() for text in text_list if text.get()!='\n' and text.get()!='\xa0']
yield item
next_page_top=response.xpath('//a[@class="skin-pagingNext skin-btnPaging ga-pagingTopNextTop"]')
if next_page_top:
next_page_url=response.urljoin(next_page_top.xpath('@href').get())
yield scrapy.Request(next_page_url,callback=self.parse,dont_filter=True)
items.py
import scrapy class MorningblogItem(scrapy.Item): author = scrapy.Field() title = scrapy.Field() date = scrapy.Field() article = scrapy.Field()
settings.py(変更部分のみ)
ROBOTSTXT_OBEY = True DOWNLOAD_DELAY = 3 HTTPCACHE_ENABLED = True FEED_EXPORT_ENCODING='utf-8'
とりあえず次は集めたデータの前処理。
形態素解析などやっていきます。
See You Next Page !