Published Date : 2019年9月27日18:25
PythonでPandasを使った簡単なスクレイピング
Simple scraping with Pandas in Python
This blog has an English translation
前回の記事の続き。同じことをサクッとPythonで仕上げていきます。プラスアルファも付け足していきます。
Continued from previous article. We'll quickly finish the same thing in Python. And I will add extra.
Pandasを使って5行で終わらす
Use Pandas to end with five lines
import pandas as pd
url = "https://ja.wikipedia.org/wiki/%E3%83%8F%E3%83%AD%E3%83%BC!%E3%83%97%E3%83%AD%E3%82%B8%E3%82%A7%E3%82%AF%E3%83%88"
tables = pd.read_html(url)
members_color_table = tables[3]
members_color_table.to_csv("members_color_table.csv",index=False)
出力結果は以下に表示
Output results are shown below.

簡単、ありがとうPandas!
Easy, thanks Pandas!
ブラウザ表示やAPIで使いやすくする為にJSONファイルにする
Make it a JSON file to make it easier to use in browsers and APIs.
表題の通り。扱いやすいよう、JSONファイルにする。JSON形式で見やすいように整形もする。
As the title says. Make it a JSON file for ease of use. It is also formatted in JSON format for easy viewing.
import re
import json
header = members_color_table.columns
color_table = members_color_table.iloc[:,0]
extract_color = re.compile(r'(?<=\()\w+(?=\))')
extract_member = re.compile(r'\w+(?=\()')
groups = [members_color_table[header[i]] for i in range(1, len(header))]
color_palete = pd.read_html("https://www.toyo-chem.com/ja/products/mkfilm/colorchart.html")
color_schema = {}
for cp in color_palete:
for i, c in enumerate(cp[('色名', '色名')]):
r = cp.loc[i, ('sRGB', 'R')]
g = cp.loc[i, ('sRGB', 'G')]
b = cp.loc[i, ('sRGB', 'B')]
color_schema[c] = f"#{r:02x}{g:02x}{b:02x}"
mc_dict = {}
for g in groups:
mc_dict[g.name] = {}
for idx,member in enumerate(g):
mc_dict[g.name][color_table[idx]] = {}
try:
ziped = zip(extract_member.findall(member),extract_color.findall(member))
tempdict = dict(ziped)
for key, value in tempdict.items():
for k, v in color_schema.items():
try:
if value == k:
tempdict[key] = [value, v]
break
except:
pass
mc_dict[g.name][color_table[idx]] = tempdict
except:
mc_dict[g.name][color_table[idx]] = {'':['','']}
with open("members_color_table.json","w") as f:
json.dump(mc_dict, f, ensure_ascii=False)
コードの説明
Code Description
header = members_color_table.columns
データフレームにcolumnsでアクセスすると列名が得られるYO
Accessing a data-frame as columns gives the column name.
color_table = members_color_table.iloc[:,0]
iloc[行の番号(配列指定でも可)、列の番号(配列指定でも可)]で指定した値を取り出せるYO。この場合「列名:色系統」の種類全てを取り出す。
You can retrieve the value specified by iloc [Row number (Can also be specified as an array), column number (Can also be specified as an array)]. In this case, all types of "Column Name: Color Lineage" are taken out.
extract_color = re.compile(r'(?<=\()\w+(?=\))') extract_member = re.compile(r'\w+(?=\()')
正規表現を使ってメンバーの名前と担当カラーを分ける準備をする。
Prepare to separate the member's name from its color using regular expressions.
groups = [members_color_table[header[i]] for i in range(1, len(header))]
色系統ごとにグループをまとめる。
Group members by color system of their colors.
color_palete = pd.read_html("https://www.toyo-chem.com/ja/products/mkfilm/colorchart.html")
色の名前を16進数表記に直す為、適当なURLからカラーパレットを作る準備をする。
Prepare to create a color palette from the appropriate URL in order to convert the color names to hexdecimal.
color_schema = {}
for cp in color_palete:
for i, c in enumerate(cp[('色名', '色名')]):
r = cp.loc[i, ('sRGB', 'R')]
g = cp.loc[i, ('sRGB', 'G')]
b = cp.loc[i, ('sRGB', 'B')]
color_schema[c] = f"#{r:02x}{g:02x}{b:02x}"
16進数に直す作業。f"{変数:02x}" で 0埋め2桁の16進数表記ができる。
Converting to hexdecimal.f "{variables: 02x}" is 0 padded and 2 digit hexdecimal notation is possible.
header = members_color_table.columns
データフレームにcolumnsでアクセスすると列名が得られるYO
Accessing a data frame as columns gives the column name.
mc_dict = {}
JSONファイルを用意するため、空の辞書を作る。
Create an empty dictionary to prepare the JSON file.
for g in groups:
mc_dict[g.name] = {}
for idx,member in enumerate(g):
mc_dict[g.name][color_table[idx]] = {}
try:
ziped = zip(extract_member.findall(member),extract_color.findall(member))
tempdict = dict(ziped)
for key, value in tempdict.items():
for k, v in color_schema.items():
try:
if value == k:
tempdict[key] = [value, v]
break
except:
pass
mc_dict[g.name][color_table[idx]] = tempdict
except:
mc_dict[g.name][color_table[idx]] = {'':['','']}
先程コンパイルした正規表現のパターンを使って、メンバーの名前とメンバーカラーを分ける。 さっき作ったカラーパレットから16進数に変換。 メンバーカラーと16進数をセットにしたリストを作成して、メンバーの名前をキーにした辞書にする。 そして、グループと色の系統毎に振り分けていく。
Separate member names and member colors using the previously compiled regular expression patterns. I converted the color palette I made earlier to hexdecimal. Create a list of member colors and hexdecimals as a key dictionary of member names. Then, they are divided into groups and color systems.
with open("members_color_table.json","w") as f:
json.dump(mc_dict, f, ensure_ascii=False)
JSONファイルとして、書き出す。 日本語の文字化けを防ぐ為、ensure_asciiをFalseにする。
Export as a JSON file. Set ensure_ascii to False for Japanese characters to display correctly.
このJSONファイルをFlaskを使って表示させるとこんな感じになる。
This JSON file looks like this when viewed in Flask.
@app.route('/get_json', methods=['GET'])
def get_json():
with open(json_url) as f:
output = json.load(f)
return jsonify(output)
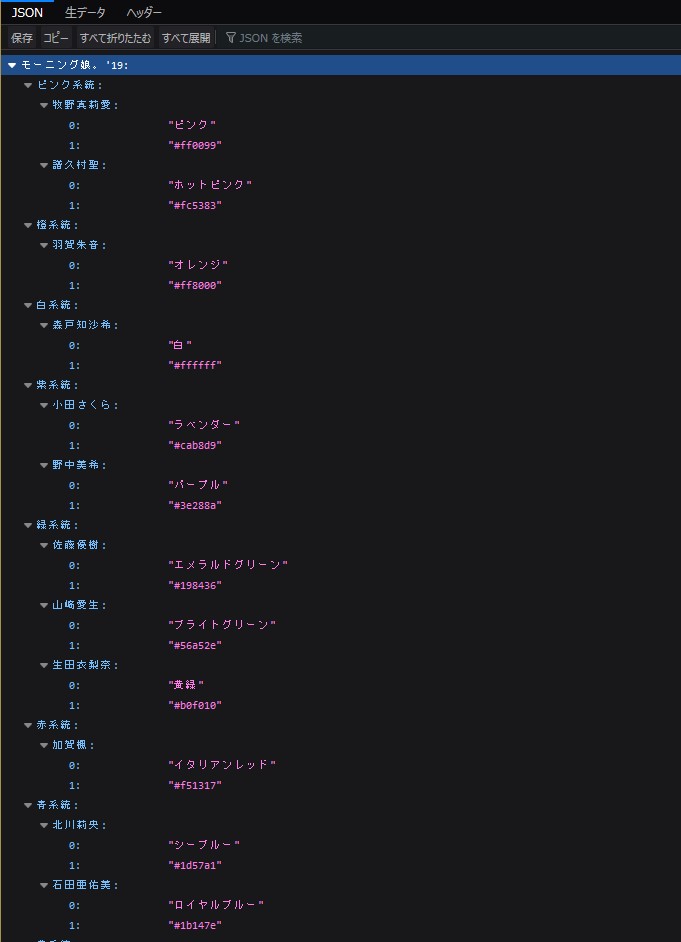
後半へ続く
Follow in the second half
次回簡単なアプリを作りマリウス葉。
I will make a simple application next time.
JSONファイルを使って色を出すだけです。簡単なお仕事です。
All you have to do is use a JSON file to generate the colors. It's a piece of cake.
See You Next Page!