Published Date : 2019年6月10日10:01
Deep Manzai Part 6
前回の簡単なあらすじ
前回はseq2seqの
改良版Attentionを使って、
一問一答形式の
文章生成をChainerの
コードにて行いました。
コードはこちらの方のブログを そっくり使わせていただきました。 Attention Seq2Seqで対話モデルを実装してみた
改めて最高級のEnjoy感謝です!
コードはこちらの方のブログを そっくり使わせていただきました。 Attention Seq2Seqで対話モデルを実装してみた
改めて最高級のEnjoy感謝です!
若干の修正
前回の続きを開始。
今回は前回のコードに
若干の修正を加えて
再実行するところから始めます。
修正点
ところで前回は
拝借したソースコードの
関係上MeCabを使いました。
今回はそのまま MeCabを使っていきますが、
MeCabにはNEologd辞書という、 新語や等に幅広く対応した 辞書が存在します。
こちらを使うと、 特に話し言葉の場合、 100%ではありませんが、 適切な分かち書きを してくれるようになります。
今回はそのまま MeCabを使っていきますが、
MeCabにはNEologd辞書という、 新語や等に幅広く対応した 辞書が存在します。
こちらを使うと、 特に話し言葉の場合、 100%ではありませんが、 適切な分かち書きを してくれるようになります。
MeCab覚醒
ちなみに、前回
MeCabで分かち書き部分を
分けたほうが
速くなると
ほざいてしまいましたが、
実際には事前に
分かち書きするのと
対して差がありませんでした。
無念です。
なにはともあれ、 まずはMeCabで Neologd辞書を使う とこまでいきましょう。
Google Colaboratoryで、NEologd辞書で、MeCabを使う(Python) こちらの記事のコードの丸写しです。
最高級のEnjoy感謝です。
無念です。
なにはともあれ、 まずはMeCabで Neologd辞書を使う とこまでいきましょう。
Google Colaboratoryで、NEologd辞書で、MeCabを使う(Python) こちらの記事のコードの丸写しです。
最高級のEnjoy感謝です。
# Colaboratoryで、MeCabを使う準備
!apt-get -q -y install sudo file mecab libmecab-dev mecab-ipadic-utf8 git curl python-mecab
# 続いて、Neologd辞書をインストール、セットアップ
!git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git
!echo yes | mecab-ipadic-neologd/bin/install-mecab-ipadic-neologd -n
# 設定ファイルを変更していきます。
!sed -e "s!/var/lib/mecab/dic/debian!/usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd!g" /etc/mecabrc > /etc/mecabrc.new
!cp /etc/mecabrc /etc/mecabrc.org
!cp /etc/mecabrc.new /etc/mecabrc
# PythonでMeCabを使えるようにする。
!apt-get -q -y install swig
!pip install mecab-python3
# 準備完了。
# オリジナル記事では、Ochasenだけの指定でしたが、
# 自分の環境では変わらず、
# やもなく直接パスを指定。
import MeCab
mecab = MeCab.Tagger('-Ochasen -d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd')
res = mecab.parse('メカブって神ってる')
[r.split('\t')[0] for r in res.split('\n') if r.split('\t')[0]!='EOS' and r.split('\t')[0]!='']
#=> ['メカブ', 'って', '神ってる']
# ちなみに、これを通常の辞書で使用すると。。。
import MeCab
mecab = MeCab.Tagger('-Ochasen')
res = mecab.parse('メカブって神ってる')
[r.split('\t')[0] for r in res.split('\n') if r.split('\t')[0]!='EOS' and r.split('\t')[0]!='']
#=> ['メカブ', 'って', '神', 'って', 'る']
コード修正
さて、Neologd辞書が
使えるようになったところで、
さらっと変更部分の説明。
変える部分は、
1: PythonでMeCabの Neologd辞書を使う設定。
2: GPUの設定部分修正。
3: バッチサイズ変更。
4: モデルセーブくらいです。
一気に修正していきます。
変える部分は、
1: PythonでMeCabの Neologd辞書を使う設定。
2: GPUの設定部分修正。
3: バッチサイズ変更。
4: モデルセーブくらいです。
一気に修正していきます。
そんな大人ぁ、修正してやるぅ!
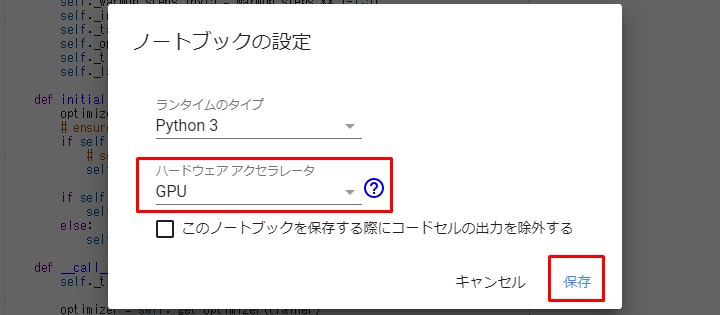
まずColaboratoryで
ランタイムのタイプをGPUにしてね。


お次はコード。
お次はコード。
# これが若さか。。。
# 的なGPU設定修正箇所。
print('GPU availability:', chainer.cuda.available)
print('cuDNN availablility:', chainer.cuda.cudnn_enabled)
if chainer.cuda.available and chainer.cuda.cudnn_enabled:
xp = cuda.cupy
else:
xp = np
MeCabぅの台頭
class DataConverter:
def __init__(self, batch_col_size):
# 変更部分 Neologdn辞書を使えるようにする。
self.mecab = MeCab.Tagger('-Ochasen -d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd') # 形態素解析器
# バッチサイズ32で様子見 EMBED_SIZE = 100 HIDDEN_SIZE = 100 BATCH_SIZE = 32 # ミニバッチ学習のバッチサイズ数 BATCH_COL_SIZE = 16 EPOCH_NUM = 100 # エポック数 N = len(data) # 教師データの数
if (epoch+1)%10 == 0:
ed = datetime.datetime.now()
print("epoch:\t{}\ttotal loss:\t{}\ttime:\t{}".format(epoch+1, total_loss, ed-st))
st = datetime.datetime.now()
# セーブ後にローカルにダウンロード
serializers.save_npz("attention_manzai_model_nights_manzai_batch16.npz", model)
from google.colab import files
files.download("attention_manzai_model_nights_manzai_batch32.npz")
終了DESU。
ナイツの漫才
前回は脈略なく 学習データを 100ぐらいの単位で 取り出しました。
単純に時間がかかるからです。
こんな感じに、 batch_sizeを512に 設定しても、
緩やかな損失値の低下。
時間のかかり具合。
そして恐ろしく値が悪い。

Batchsize32にしても 1800行くらいで 3時間くらいかかります。
だったら、 特定の漫才に特化して、 学習をしていき、 どうなるか、 試すのも悪くありません。
ただ、データ量は少ないです。 期待しないでね。
ナイツのまとめ方
個人的にナイツの
漫才が好きなのと、
タイトルが12個あり、 ボリューム的にも 丁度いいので、
ナイツの漫才を まとめて学習 することにしました。
タイトルが12個あり、 ボリューム的にも 丁度いいので、
ナイツの漫才を まとめて学習 することにしました。
# いちいちマイドライブをマウントするのが # 面倒くさいってかたはファイルをローカルから直接アップロードしてね。 from google.colab import files uploaded = files.upload()
# 前前前回あたりのスクレイピングしたJSONファイルを
# アップロードしたら、読み込む。
import json
with open('daihon.json','r',encoding='utf-8') as f:
daihon_json=json.load(f)
# 作戦:「ガンガンいくぜ!」
# Boke Tukkomi mannaka その他不要な頭の部分をカット。
import re
def split_roll(x):
try:
return re.sub(r'^[^:]+: ','',x)
except:
return x
daihon=[[split_roll(d_) for d_ in d] for d in [d['article'] for d in daihon_json]]
# 振り分けのため、タイトルを抽出
titles=[d['title'] for d in daihon_json]
# 前回のコードです。
# しゃべくり漫才とされている方々のリストを
# Wikiから拝借して、
# 振り分ける。
import requests
from bs4 import BeautifulSoup
res=requests.get('https://ja.wikipedia.org/wiki/%E6%BC%AB%E6%89%8D%E5%B8%AB%E4%B8%80%E8%A6%A7')
soup=BeautifulSoup(res.content,'lxml')
lis=soup.find_all('li')
manzaishi_list=[]
for li in lis:
try:
manzaishi_list.append(li.a.string)
except:
if li.string.startswith('「現代上方演芸人名鑑」'):
break
else:
manzaishi_list.append(li.string)
manzaishi_indices=[]
import re
for i,title in enumerate(titles):
for manzaishi in manzaishi_list:
try:
if re.search(manzaishi,title):
manzaishi_indices.append(i)
except:
pass
manzaishi_titles=[titles[i] for i in manzaishi_indices]
manzaishi_daihon=[daihon[i] for i in manzaishi_indices]
# ナイツの漫才のみ抽出。
nights_manzai_list=[manzaishi_daihon[idx] for idx,m in enumerate(manzaishi_titles) if 'ナイツ' in m]
import numpy as np
nights_scripts=np.array([np.array([line for line in lines]) for lines in nights_manzai_list])
nights_script_lines=np.concatenate(nights_scripts)
nights_script_lines[1:3]
#=> array(['よろしくお願い致します。', '今年、やりたいなって思ってる事がありましてレストランのオーナーになりたいと思ってるんですよ。'],dtype='>U76')
いざ学習
バッチサイズを8にしました。
時間はかかりますが、
精度はあがる。。。はず。
それと、Colaboratoryを 長時間回しておくと、 途中で果てるので、
途中経過のモデルを 保存しておきましょう。
最後に学習済みのモデルも 保存しますが、
colaboratoryが果てたら、 Mydriveに保存してない限り、
全ての変数とファイルが 消え去っているため、
ローカルに落としておく。
これが嫌なら、MyDriveを マウントして、 MyDrive内で作業をすること。
それと、Colaboratoryを 長時間回しておくと、 途中で果てるので、
途中経過のモデルを 保存しておきましょう。
最後に学習済みのモデルも 保存しますが、
colaboratoryが果てたら、 Mydriveに保存してない限り、
全ての変数とファイルが 消え去っているため、
ローカルに落としておく。
これが嫌なら、MyDriveを マウントして、 MyDrive内で作業をすること。
# リストオブリストオブリストにするための処理。 data=[[[nights_script_lines[idx]],[nights_script_lines[idx+1]]] for idx in range(0,len(nights_script_lines)-1)] # 確認。 data[:2] # => # [[['よろしくお願いします。'], ['よろしくお願い致します。']], # [['よろしくお願い致します。'], ['今年、やりたいなって思ってる事がありましてレストランのオーナーになりたいと思ってるんですよ。']]]
# 定数
EMBED_SIZE = 100
HIDDEN_SIZE = 100
BATCH_SIZE = 8 # ミニバッチ学習のバッチサイズ数
BATCH_COL_SIZE = 16
EPOCH_NUM = 100 # エポック数
N = len(data) # 教師データの数
# 教師データの読み込み
data_converter = DataConverter(batch_col_size=BATCH_COL_SIZE) # データコンバーター
data_converter.load(data) # 教師データ読み込み
vocab_size = len(data_converter.vocab) # 単語数
# モデルの宣言
model = AttSeq2Seq(vocab_size=vocab_size, embed_size=EMBED_SIZE, hidden_size=HIDDEN_SIZE, batch_col_size=BATCH_COL_SIZE)
opt = optimizers.Adam()
opt.setup(model)
opt.add_hook(optimizer.GradientClipping(5))
# ここでGPUの設定。
if xp == cuda.cupy:
chainer.cuda.get_device(0).use()
model.to_gpu(0)
model.reset()
# 学習開始
print("Train")
st = datetime.datetime.now()
# 途中経過のロードの場合。
# 例えば、エポック41でセーブしたけど、42ぐらいで落ちてた場合。
# ここらへんのタイミングでロードしておく。
# serializers.load_npz('41_57.61121.network',model)
for epoch in range(EPOCH_NUM):
# ミニバッチ学習
perm = np.random.permutation(N) # ランダムな整数列リストを取得
total_loss = 0
for i in range(0, N, BATCH_SIZE):
enc_words = data_converter.train_queries[perm[i:i+BATCH_SIZE]]
dec_words = data_converter.train_responses[perm[i:i+BATCH_SIZE]]
model.reset()
loss = model(enc_words=enc_words, dec_words=dec_words, train=True)
loss.backward()
loss.unchain_backward()
total_loss += loss.data
opt.update()
# 落ちたとき対策の途中保存。
output_path = f"{epoch+1}_{total_loss}.network"
serializers.save_npz(output_path, model)
if (epoch+1)%10 == 0:
ed = datetime.datetime.now()
print("epoch:\t{}\ttotal loss:\t{}\ttime:\t{}".format(epoch+1, total_loss, ed-st))
st = datetime.datetime.now()
# 保存してやるぅ!
serializers.save_npz("attention_manzai_model_nights_manzai_batch8.npz", model)
# 落ちろ!カトンボ!
from google.colab import files
files.download("attention_manzai_model_nights_manzai_batch8.npz")
上でバッチサイズ8にしましたが、
正直時間がかかりすぎなので、
3分クッキングよろしく、
先にバッチサイズ32のほうを
epoch 50 にして、
再学習させました。
結果がこちら。
損失値は。。。

まっ、いっか!
結果がこちら。
損失値は。。。
まっ、いっか!
ヤホー
インプット文を使用して、
ナイツ漫才っぽくチャレンジ。
print("\n漫才のようなものスタート")
def predict(model, query):
enc_query = data_converter.sentence2ids(query, train=False)
dec_response = model(enc_words=enc_query, train=False)
response = data_converter.ids2words(dec_response)
# change
print("=<;", ''.join(response).replace('',''))
for i in range(10):
print(f'{i+1}回目のやりとり')
predict(model, input('-> '))
print()

無念。
アテンションプリーズ!
Sudachi再利用バージョン
先立って、
アプリの用意のため、
MeCabをCoreserverに インストールしようとしたら、
sudo権限がないため、 apt-getが使えなかった。
結局Sudachiの お世話になることに。
なので、 Sudachi再利用バージョンの コードを書いておきます。
といっても大した 修正ではありません。
MeCabをCoreserverに インストールしようとしたら、
sudo権限がないため、 apt-getが使えなかった。
結局Sudachiの お世話になることに。
なので、 Sudachi再利用バージョンの コードを書いておきます。
といっても大した 修正ではありません。
# まずinitializeのMeCab部分をコメントアウト
class DataConverter:
def __init__(self, batch_col_size):
# クラスの初期化
# :param batch_col_size: 学習時のミニバッチ単語数サイズ
# self.mecab = MeCab.Tagger() # 形態素解析器
self.vocab = {"":0, "": 1} # 単語辞書
self.batch_col_size = batch_col_size
# 続いて既に分かち書きされているので、
# Splitメソッドで半角空白で区切りリスト化するだけ。
def sentence2words(self, sentence):
# 文章を単語の配列にして返却する
# :param sentence: 文章文字列
##変更箇所##
# sentence_words = []
# self.mecab.parse(sentence).split("\n"): # 形態素解析で単語に分解する
# w = m.split("\t")[0].lower() # 単語
# if len(m) == 0 or m == "eos": # 不正文字、EOSは省略
continue
# sentence_words.append(m)
# これだけ
sentence_words = [m for m in sentence.split(' ')]
###########
sentence_words.append("") # 最後にvocabに登録しているを代入する
return sentence_words
Sudachiを直に利用するなら
# 現在のパスからSudachipyを使えるようにする。
import sys
sys.path.append('src/sudachipy/')
# Sudachiの設定ファイルを読み込む。
import json
from sudachipy import config
from sudachipy import dictionary
from sudachipy import tokenizer
with open(config.SETTINGFILE, 'r', encoding='utf-8') as f:
settings = json.load(f)
# 分かち書きしてくれるオブジェクトを作成。
tokenizer_obj = dictionary.Dictionary(settings).create()
# よしなに、単語を分けてくれるモードを指定。
mode = tokenizer.Tokenizer.SplitMode.C
# DataConverter内の修正
class DataConverter:
# 省略
# self.mecab = MeCab.Tagger()
self.sudachi = tokenizer_obj
# 省略
# sentence2words内修正
def sentence2words(self, sentence):
# 形態素解析で単語に分解する
tokens = self.sudachi.tokenize(mode, sentence)
sentence_words = [token.surface() for token in tokens]
sentence_words.append("") # 最後にvocabに登録しているを代入する
return sentence_words
次回へ続く
次回は取り敢えず
ナイツの分だけWEBアプリ化して、
その間に全体の学習を 進めていきます。
いわば時間稼ぎ。
こうして同じテーマの 無限ループは続く。。。
See You Next Page!
その間に全体の学習を 進めていきます。
いわば時間稼ぎ。
こうして同じテーマの 無限ループは続く。。。
See You Next Page!